😀'데이터베이스의 속도를 올리려면 무엇을 해야합니까?'라는 물음에 대한 가장 많은 답변으로 '인덱싱'을 생각해보라 라는 말을 들었다. 배열에서의 인덱스는 알아도 데이터베이스에서 인덱스는 뭔지 알아보자.
인덱스(Index)란?
인덱스(Index)는 데이터베이스에서 테이블의 검색 속도를 높이기 위한 기술 또는 장치이다.
인덱스를 "검색 속도를 높이기 위한 자료구조"라고도 표현하는데 우리가 알고있는 트리(tree)구조나 해시 테이블(hash table)구조를 사용하기 때문에 자료구조라고도 표현한다.
😀일반적으로 DB에서 특정 데이터를 찾기위해서 테이블을 모두 조회하게 된다면, 당연히 모든 정보를 읽느라 시간이 비교적 오래걸릴 것이다. 만약에 특정데이터의 위치를 알려주는 데이터가 따로 있다면, 위치를 알려주는 데이터를 보고 한번에 찾아갈 수 있을 것이다.
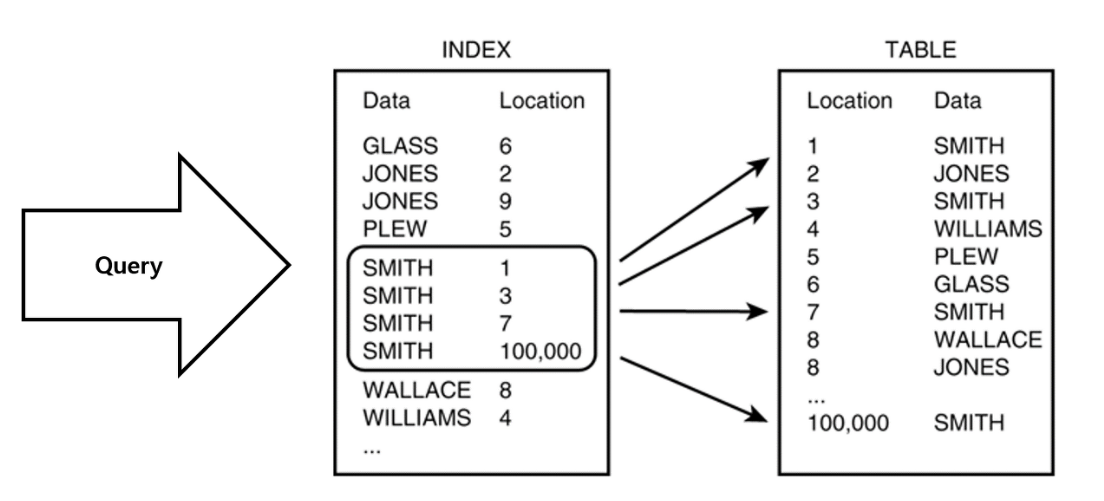
😀보통 인덱스를 표현하면 도서에서 제일 뒤에 수록하는 찾아보기와 같은 기능을 한다고 말한다. 우리가 도서를 읽을 때 앞에서부터 넘겨가며 내가원하는 단원의 특정 주제를 찾으려면 당연히 한참 걸린다. 하지만 찾아보기를 한번 보게 된다면, 우리가 원하는 단원의 특정주제를 한번에 찾아갈 수 있을 것이다.
인덱스의 구조
인덱스는 일반적으로 키(Key)와 값(Value)으로 구성된다. 키는 검색에 사용되는 컬럼(Column)이나 컬럼 조합이며, 값은 해당 레코드(Record)를 가리키는 포인터(Pointer)이다. 이 포인터를 사용하여 레코드를 직접 읽을 수 있다.
인덱스를 구현하는데는 해시테이블(Hash table), B트리(B-tree), B+트리(B+tree)구조를 보통 사용한다.
해시 테이블(Hash table)
해시 테이블은 무한에 가까운 데이터들을 유한한 개수의 해시 값으로 매핑한 테이블이다.
(Key, Value) 데이터를 아주 빠르게 찾아낼 수 있는 자료구조이다.
삽입, 삭제, 탐색 시 평균적으로 O(1)의 시간복잡도를 가지고 있고 unordered_map으로 구현한다.
❓unordered_map은 해시 테이블을 구현한 C++ STL 컨테이너 중 하나이다.
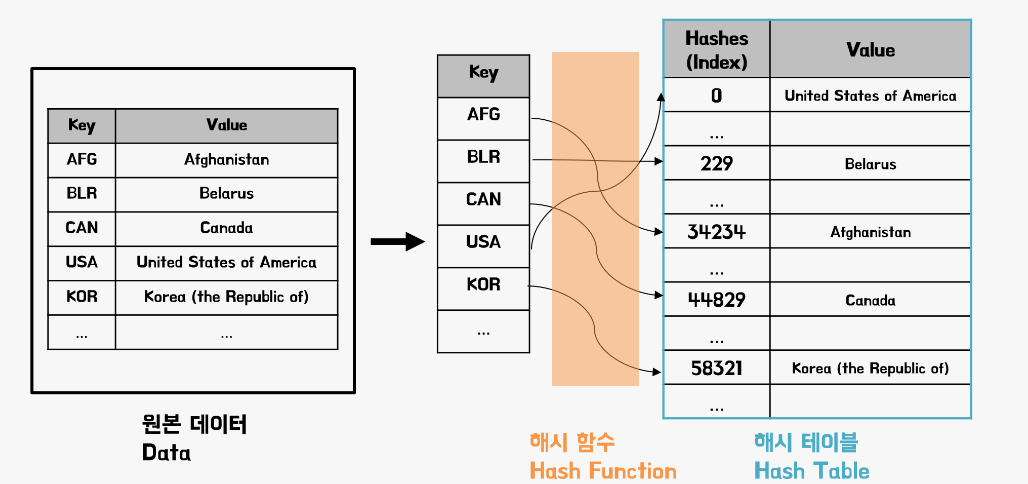
해시테이블은 해시 함수(hash function)를 이용하여 키(key) 값을 배열의 인덱스로 변환하고, 이 인덱스에 해당하는 배열의 원소에 값을 저장한다. 따라서 해시테이블은 배열과 연관된 자료구조이다.
해시테이블의 동작원리는 키 값의 해시값을 계산한 뒤, 해당 해시값을 인덱스로 이용하여 데이터를 저장하거나 검색한다.
일반적으로 해시함수는 키 값을 받아 고정된 길이의 숫자 값인 해시값(hash value)을 반환한다.
해시값은 배열의 인덱스를 구하기 위한 값으로 사용된다. 해시값을 이용하면 검색 속도를 대폭 향상시킬 수 있다.
❗하지만, 해시테이블에서는 서로 다른 키 값이 같은 해시값을 반환하여 같은 배열 인덱스에 데이터를 저장하게 되는 상황, 즉 해시 충돌(hash collision) 이 발생할 수 있다.
이러한 해시 충돌(hash collision)을 처리하는 방법으로는 대표적으로 체이닝(chaining)과 개방주소법(open addressing)이 있다.
체이닝(chaining)은 해시 충돌이 발생하면 해당 인덱스에 연결 리스트를 생성하여, 동일한 인덱스에 속한 다른 데이터와 함께 연결리스트에 추가하는 방법이고
개방주소법(open addressing)은 해시 충돌이 발생하면 다른 빈 인덱스를 탐색하여 데이터를 저장하는 방법이다.
❌해시 테이블은 실제로 인덱스에서 잘 사용되지 않는다.
그 이유는, 해시 테이블은 등호(=) 연산에 최적화되어있기 때문이다. 데이터베이스에선 부등호(<, >) 연산이 자주 사용되는데, 해시 테이블 내의 데이터들은 정렬되어 있지 않으므로 특정 기준보다 크거나 작은 값을 빠른 시간 내에 찾을 수가 없다.
B-트리(B-tree)
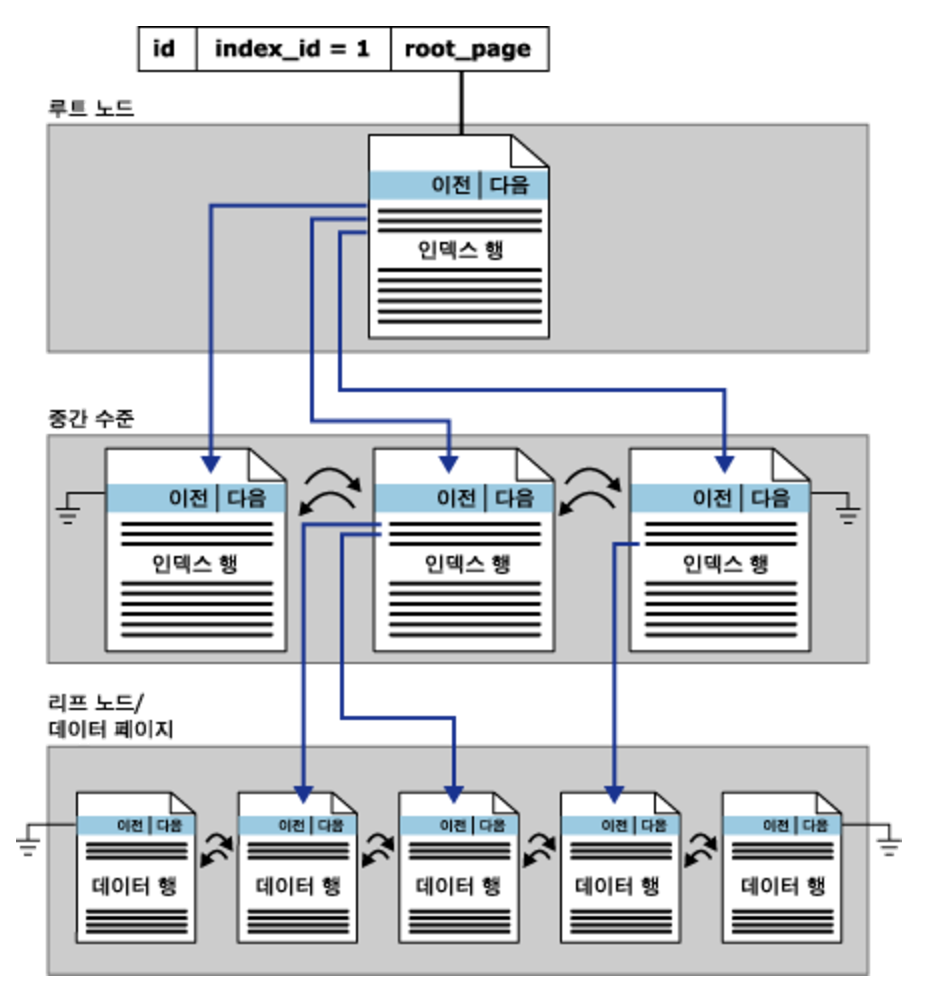
😀B-tree 인덱스는 여러 개의 노드로 구성되며, 각 노드는 하나의 데이터 페이지와 연결되어 있다. 이러한 노드들은 트리 구조를 형성하여 데이터를 빠르게 검색할 수 있다.

B-tree 인덱스는 여러 개의 노드로 구성된다. 일반적으로 각 노드는 레벨과 식별자로 구분된다.
가장 위의 노드는 루트 노드라고 하며, 이 노드는 하나의 데이터 페이지와 연결되어 있다.
루트 노드에서 각 노드는 하나 이상의 자식 노드를 가지고 있으며, 각 자식 노드는 또 다시 하나 이상의 자식 노드를 가질 수 있다.
중간에 존재하는 노드들을 서브 노드라고 하며, 가장 하위의 노드는 리프노드라고 한다.
리프노드는 인덱스 키와 함께 실제 데이터를 가지고 있다.
B-tree 인덱스의 검색 동작 순서는 아래와 같다.
인덱스 노드에 접근한다.
인덱스 노드를 검색하여 검색 키와 일치하는 서브 트리를 선택한다.
선택된 서브 트리에서 다시 검색을 수행한다.
검색 키와 일치하는 데이터 페이지를 찾으면 검색을 종료한다.
😀B-Tree의 경우, 키 값과 데이터 값이 노드 안에 함께 저장되기 때문에 노드 크기가 크고, 디스크 I/O 작업이 많아지는 문제가 있습니다. 이러한 문제를 개선하기 위해 B+Tree구조를 더 많이 사용한다.
B+트리(B+tree)
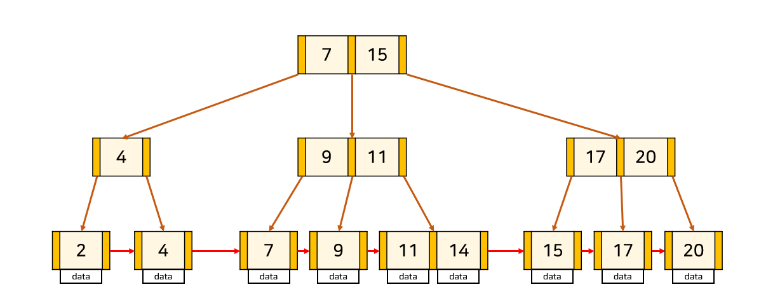
B+트리는 B-Tree의 변형 중 하나로, 디스크 기반의 데이터 구조에서 빠른 검색 및 범위 검색을 위해 고안되었다.
B-Tree의 경우, 키 값과 데이터 값이 노드 안에 함께 저장되기 때문에 노드 크기가 크고, 디스크 I/O 작업이 많아지는 문제가 발생한다.
이러한 문제를 개선하기 위해 B+트리는 데이터 노드의 포인터만을 갖고, 모든 데이터는 리프 노드에만 저장하게 된다.
-
B-트리와의 차이점
B+트리는 B-트리와 매우유사하지만 확실하게 다른 것은 내부 노드의 데이터 유/무 이다.
B 트리는 내부 노드와 리프 노드가 모두 데이터를 가지며, 내부 노드의 자식 노드는 최대 m개, 최소 (m/2)개를 가질 수 있다. 리프 노드 역시 데이터와 함께 자식 노드를 가질 수 있다.
반면 B+ 트리는 리프노드만 데이터를 갖고 내부 노드가 데이터를 가지지 않으며, 자식 노드의 개수는 최대 (m+1)개, 최소 (m/2+1)개 이다. 모든 데이터는 리프 노드에만 존재하며, 리프 노드는 서로 연결된 리스트 형태를 이룬다. -
B+트리가 갖는 강점
-
리프 노드만 디스크 I/O 작업을 수행하므로, 더 적은 I/O 작업을 필요로 한다. B-Tree와 달리 노드 크기가 크지 않아서, 한 번에 많은 양의 데이터를 읽을 필요가 없기 때문이다.
-
모든 데이터가 리프 노드에만 저장되기 때문에, 범위 검색을 더 빠르게 처리할 수 있다.
-
인덱스 블록 크기를 유연하게 조정할 수 있어서, 더 많은 데이터를 처리할 수 있다.
-
B-Tree와 같이 검색 성능이 뛰어나면서도, 범위 검색 및 저장 공간 사용 면에서 더 나은 성능을 제공한다.
-
B-Tree와 B+tree 모두 O(log n)의 시간복잡도를 가지지만, B+Tree가 더 작은 크기의 노드들을 읽어나가 리프노드에 도착 하기 때문에 디스크에서 데이터를 읽어오는 비용이 줄고 검색 성능이 더 좋다.
인덱스의 장단점
😀인덱스는 데이터베이스의 성능을 향상시키기 위해 사용되지만 사용함으로 인해 잃거나 더 많은 작업이 필요해 질 수 도있다.
장점
-
빠른 검색 속도
인덱스를 사용하면 검색 작업이 빨라진다.
데이터베이스에서 데이터를 검색할 때, 인덱스를 사용하면 검색 대상이 줄어들어 빠르게 결과를 가져올 수 있다. -
중복 데이터 제거
인덱스는 중복 데이터를 제거하는 데에도 사용할 수 있다.
인덱스를 사용하면 중복 데이터를 허용하지 않도록 강제할 수 있다. -
데이터 정렬
인덱스는 데이터를 정렬하는 데에도 사용된다.
데이터베이스에서 데이터를 정렬할 때 인덱스를 사용하면 정렬이 빠르고 효율적이다.
단점
-
생성시간의 소요
인덱스를 만드는 데에 시간이 걸린다.
인덱스를 만들 때는 데이터베이스의 크기에 따라 시간이 많이 걸릴 수 있다. -
데이터 공간 차지
인덱스를 저장하는 데에 공간이 필요합니다. 인덱스를 저장하려면 따로 공간을 할당해야 한다.
이 공간이 부족하면 오히려 데이터베이스의 성능이 저하된다. -
추가적인 작업의 필요성
인덱스를 유지하는 데에 추가 작업이 필요하다.
데이터베이스에서 데이터가 변경될 때마다 인덱스도 함께 변경해야 한다.
인덱스 사용시 주의점
😀컴퓨터과학의 거장 도널드 크누스는 '섣부른 최적화는 만악의 근원'이라는 말을 했다. 확실하지도 않은 성능상의 이익 때문에 아키텍처나 가독성을 해치는 개발을 하지 말라는 뜻이다.
인덱스는 데이터베이스에서 읽기속도를 올리기 위한 최적화 기법이다. 하지만 얻는 혜택이 있으면 ❌그에 따른 부작용도 있다.
인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지시켜줘야 한다는 점이다. 그렇기에 레코드 내에 데이터 값이 바뀌는 부분이라면 오히려 데이터베이스의 성능을 저하시킬 수도 있다.
-
삽입, 수정, 삭제 기능에 취약하다.
INSERT, UPDATE, DELETE를 통해 데이터가 추가되거나 값이 바뀐다면 인덱스 테이블 내에 있는 각 요청이 발생할 때 마다 값들을 다시 정렬을 해야 한다. 이는 인덱스 테이블과 원본테이블 두 가지 테이블의 데이터를 다시 정렬 해줘야하기 때문에 데이터베이스의 속도를 절감시킬 수 있다.
-
데이터의 양이 적으면 적을수록 효율을 내기 힘들다.
인덱스는 테이블의 전체 데이터 중에서 10~15% 이하의 데이터를 처리하는 경우에만 효율적이고 그 이상의 데이터를 처리할 땐 인덱스를 사용하지 않는 것이 더 낫다.
예를 들면 100개의 데이터가 있는 테이블과 100만 개의 데이터가 들어 있는 테이블이 있다고 하자. 100만 개의 데이터가 들어있는 테이블이라면 풀 스캔보다는 인덱스 스캔이 유리하겠지만, 100개의 데이터가 들어있는 테이블은 굳이 인덱스 스캔 없이 풀 스캔이 빠를 것이다.
참고자료(출처)
Rebro의 코딩 일기장 [DB] 11. 인덱스(Index) - (1) 개념, 장단점, B+Tree 등
괭이쟁이 깃허브io 포스팅 [자료구조 2] 해시테이블(HashTable) 이해하기
티스토리 드럼치는 코린이의 개발 공간 [DB] 데이터베이스(DB) 인덱스(Index) 란 무엇인가?
티스토리 망나니개발자 포스팅 [Database] 인덱스(index)란?
Nesoy Blog 포스팅 DB의 Index 기능에 대해
