//참고 자료입니다.
-
c++ 최적화 10장 벡터 공부
-
뇌를 자극하는 c++
-
이펙티브 stl
-
c++ 스탠다드 레퍼렌스
-
코드없는 프로그래밍
http://lab.gamecodi.com/board/zboard.php?id=GAMECODILAB_QnA_etc&no=3177
- 템플릿 인자에 값이 아닌 포인터 넣기
- 중요!!
https://snowfleur.tistory.com/48
https://leemoney93.tistory.com/67
- 메모리 할당에 대해서
https://woo-dev.tistory.com/51
0. 업데이트
push_back vs emplace_back
: 아래 설명방식은 잘못됨.
- 차이점은 코드 작성방식이 다르다는 점이 있음.

- push_back은 오러로딩 으로 2개의 함수가 있고,
- emplace_back 함수는 forward 방식으로 되어 있음.
push_back(&&) 의 경우, 생성과 이동 동작이 발생함.
- emplace_back 은 함수내에서 객체 생성만 하고, move 이루어지지 않음.
포인터 형식 vs 값 형식
포인터 형식의 경우는 이미 힙에 할당된 포인터를 벡터에 저장하는 방식이기 때문에 , 복사가 발생하지 않고, 벡터의 메모리 재할당이 발생하지 않음.
값 형식의 경우에는 복사가 발생함.
그리고 벡터의 메모리 재할당이 발생하는데, 왜 발생하는지를 알아보자.
-
변수 타입으로 받으면 복사가 발생함.
-> 실행결과를 보면 알 수 있지만, 이 때는 clear를 안해도 알아서 소멸자를 호출하고 있는 것을 확인할 수 있음.
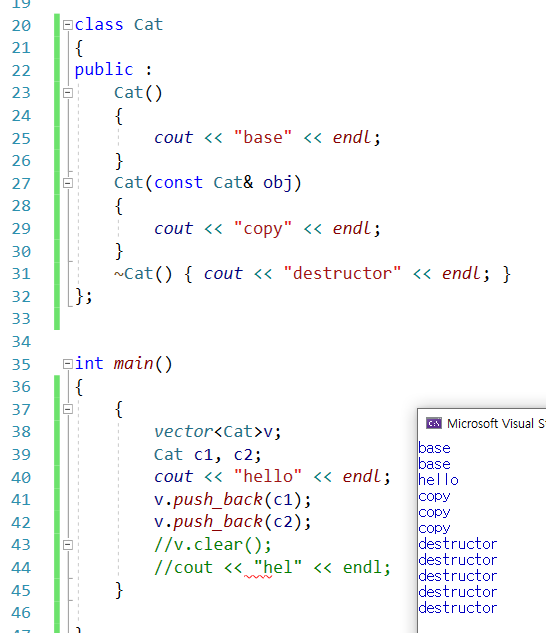
-
copy가 왜 3번 발생했을까에 대해서
-> vector에서의 메모리 재할당으로 인함.
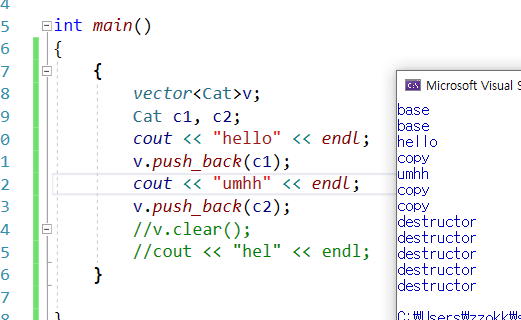
- 포인터 타입으로 받으면 복사 발생 안함.
-> 이 때는 반드시 직접 소멸자를 호출하고, clear를 해서 소멸자를 호출시켜야 함.
: clear 만으로는 소멸자 호출하지 않음.
-> 신기한 점이 벡터 자체에 대한 메모리 재할당도 이루어지지 않는다는 점임...
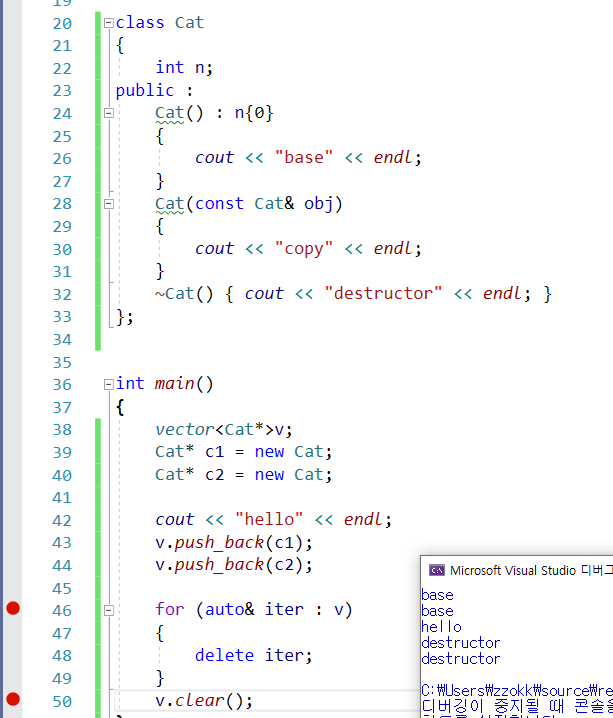
결론
: 포인터형식을 타입으로 사용하는 것이 성능면에서 좋은 듯함.
- 추가적인 공부 필요 // 230503
1.정의
: 동적으로 크기를 조절할 수 있는 배열
2.반복자
: 임의 접근자를 사용함.
3.시간 복잡도
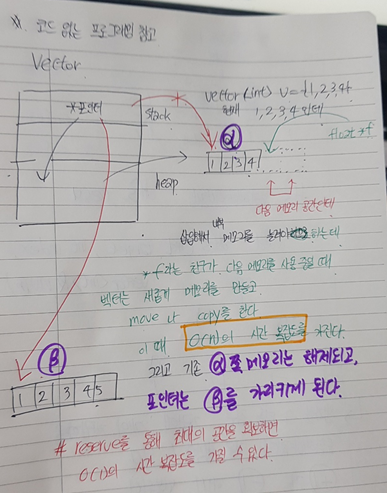
- 코드없는 프로그래밍 참고
1) random Access는 O(1) 의 시간복잡도를 가진다.
왜냐하면 벡터는 연속된 어레이의 첫번째 공간을 가리키고 있고,
모든 컨테이너가 연속되어 있으므로 시작점만 알고, 몇번째 인덱스에 접근하는지만
알면 시작주소값을 가지고 접근할 수 있기 때문이다.
2) 마지막 공간에 삽입하고 제거하는 것은 O(1)의 시간 복잡도를 가진다.
만약 현재 1만개의 데이터를 가지고 있는 상태에서 push_back이나 pop_back을 한다고 하면 첫번째 공간에서 10001번째 공간으로 가서 진행해야 하므로
v.begin() + 10001 이런 방식으로 접근하므로 O(1)이다.
O(1)의 시간 복잡도를 가진다.
3) 마지막 공간이 아닌 다른 공간에 추가 및 제거 시 O(n)의 시간복잡도를 가진다.
왜냐하면 최악으로 바라보았을때 0번째에 데이터를 추가한다고 하면 0 ~ 10000번째의 데이터를 모두 한칸씩 오른쪽으로 이동해야 하므로 10000번의 move가 발생한다.
4) size와 capacity가 같은 상태에서 삽입을 할 경우 시간 복잡도가 O(n)을 갖는다.
size와 capacity가 같으면 메모리 재할당 및 기존 원소를 move나 copy를 해야 하므로 O(n)이다.
4-2) 객체를 통한 vector 메모리 how 사용되는지 확인하자.
-
코드없는 프로그래밍을 참고했습니다.
-
클래스

-
main 함수
-> 출력값은 이렇다. , 메모리 재할당 및 복사가 발생한다는 것을 확인할 수 있다.
- 클래스를 정의할때 noexcept를 정의하는 이유
복사보다는 이동생성자로 호출하는 것이 낫다. 유저 입장에서 move를 일어나게 하고 싶은데 컴파일러가 알아서 copy를 했다. 그 이유는 클래스를 정의할 때 exception이 발생할 수 있기 때문에 컴파일러가 안전하게 복사생성자를 호출한 것이라고 한다.
현재 지금 코드에서 move는 새로운 리소스를 요청하지? 않기 때문에 exception이 일어날수가 없다.
noexept 키워드를 붙이도록 하자.
소멸자와 이동생성자에 정의를 할때 noexept를 꼭 붙여주어야 하는 이유다.
- noexept 키워드 추가 후 move생성자가 호출되는 것을 확인할 수 있따.
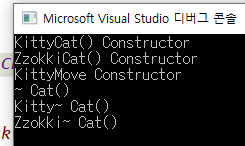
물론 가장 좋은 방법은 reserve로 미리 메모리를 확보한 상태에서 삽입하는 것이 짱이다!
4. 메모리 사용
: 벡터는 요소의 개수를 나타내는 size와 벡터가 확보한 메모리(내부 버퍼)의 크기를 capacity, 벡터의 포인터 정보가 있다.
크기와 용량이 같을때 삽입이 일어나면 내부 버퍼를 재할당하고, 벡터의 모든 요소들을
새 저장공간으로 복사한 뒤 기존 버퍼의 모든 반복자와 참조자를 무효화하는 확장 작업을 한다.
이 비용이 매우 크다.
- 릴리즈 모드로 진행함 + 32비트임.
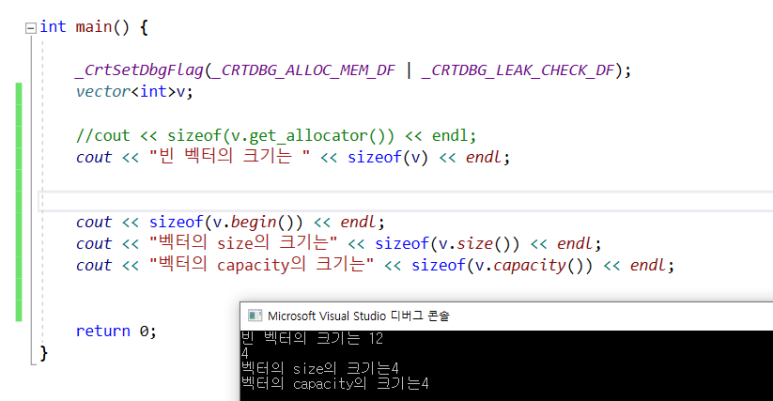
: 비어있는 벡터 v의 사이즈를 확인했더니 12바이트가 나왔다.
스택에 포인터 변수 하나 , 힙공간을 가리키고 있으며, 가리키는 곳의 사이즈와 capacity 정보를 가지고 있다.
5. 삽입하는 방법
- c++ 최적화 참고
: 10만개의 데이터를 가지고 진행함.
=> 벡터를 삽입하는 방법 중 가장 빠른 것은 대입이다.
대입이 효율적인 이유는 복사하는 벡터의 크기를 이미 알고 있으므로 대입할 벡터의 내부 버퍼를 만들기 위해 메모리 관리자를 딱 한 번만 호출하면 되기 때문이다.
1) 인덱스 접근 대입 -> 0.445밀리초
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int>v1 = { 1,2,3,4,5,6 };
vector<int>v2;
v2 = v1;
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
}
2) insert -> 0.696밀리초
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int>v1 = { 1,2,3,4,5,6 };
vector<int>v2;
v2.insert(v2.end(), v1.begin(), v1.end());
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
}
3) push_back
- 이터레이터를 이용 : 2.26밀리
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int>v1 = { 1,2,3,4,5,6 };
vector<int>v2;
for (auto iter = v1.begin(); iter != v1.end(); iter++)
{
v2.push_back(*iter);
}
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
}
- at()을 이용 : 2.05 밀리
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int>v1 = { 1,2,3,4,5,6 };
vector<int>v2;
for (unsigned i = 0; i < v1.size(); i++)
{
v2.push_back(v1.at(i));
}
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
}
- 인덱스를 이용해서 : 1.99밀리
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int>v1 = { 1,2,3,4,5,6 };
vector<int>v2;
for (unsigned i = 0; i < v1.size(); i++)
{
v2.push_back(v1[i]);
}
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
}
push_back이
- insert나 대입에 비해서 좋지 않은 이유 :벡터에 항복을 하나씩 삽입하기 때문에 벡터를 얼마나 삽입되는지 알지 못하므로, 내부 버퍼가 점진적으로 커진다.
- reserve 없이 진행할 경우 내부버퍼가 여러번 재할당 되고, 새로 할당된 버퍼에 모든
항목을 복사한다.
=> reserve를 한 후 삽입하면 0.674밀리초가 나온다.
6. 메모리 확장 정책
: 컴파일 마다 다르지만, capacity는 기존 size() / 2만큼 증가하거나
size의 2배만큼 증가한다.
- 뇌를 자극하는 stl 참고
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int> v;
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
}
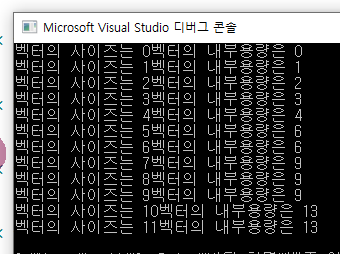
- 원소가 추가할때마다 메모리가 자라나게 하려면 메모리를 재할당해야 한다.
원소가 추가될때마다 메모리를 재할당하고 , 이전 원소를 모두 복사한다면 너무나 비효율적이다.
조금이나마 재할당에 드는 성능 문제를 보완하고자 만들어진 개념이 capacity이다.
미리 적당한 메모리 공간을 할당 한 후에 컨테이너를 삽입하는 방식이다.지금 여기서는 기존 size() / 2 만큼 추가하는 것을 확인할 수 있다.
어떤 컴파일러는 사이즈의 두배 만큼 확장하기도 한다.
7. reserve 후에 size 동일한 상태에서 push_back 하면?
: reserve를 하더라도, 용량과 사이즈가 동일한 상태에서 삽입 들어올 경우 메모리 확장이 이루어진다.
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int> v;
v.reserve(5);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
v.push_back(1);
cout << "벡터의 사이즈는 " << v.size() << "벡터의 내부용량은 " << v.capacity() << endl;
}

8. 효율적으로 사용하는 방법
: reserve를 통해서 큰 용량의 내부 버퍼를 확보해서 사용하는 것이 좋다.
reserve없이 삽입할때마다 메모리 재할당 복사, 기존 레퍼런스 제거작업이 발생하므로
미리 reserve를 통해 내부 용량을 확보한다면 메모리 재할당, 복사, 등이 발생하지 않아 효율이 좋습니다.
But, 필요 이상의 메모리를 확보한다면, 메모리 낭비이다.
이때는 shrink_to_fit을 이용해 사용되지 않는 메모리를 줄여서 size와 동일하게 만들 수 있따.
9. reserve()와 벡터 선언과 동시에 초기화 하는 방법에는 차이가 없을까?
: 주어진 원소가 디폴트 생성자가 제공되는 복잡한 타입- 클래스 에서는 초기화에 시간이 발생한다.
따라서 초기화를 하려는 이유가 재할당을 피하는 것이라면 반드시 reserve()를 사용해야만! 한다.
1) 선언과 동시에 초기화를 진행할 경우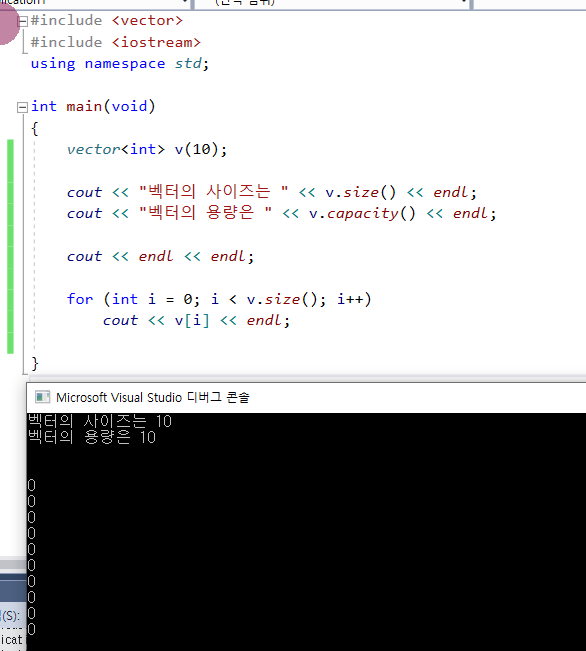
디폴트값이 생성된다.
- int 형이라서 빠르게 초기화가 일어나겠지만, 클래스라고 생각하면 생성자 호출 왔다리 갔다리 하는데 시간이 걸린다고 생각할 수 있다.
2) reserve를 사용한 경우
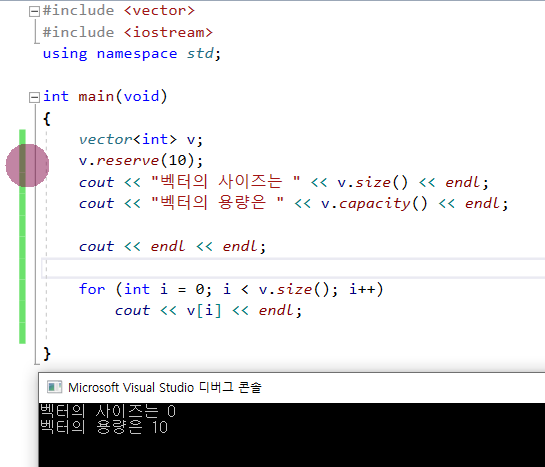
내부 용량만 확보하고, 디폴트값은 없다!
10. 메모리 해제
- 지역변수로 사용할 때
-
지역변수로 사용된 벡터는 알아서 소멸됨을 확인할 수 있다.
스코프 벗어남과 동시에 stack에 저장된 메모리 사라지고,
힙 영역에 있는 컨테이너들도 동시에 사라진다. -
메모리릭 발생되지 않는 것을 확인할 수 잇따.
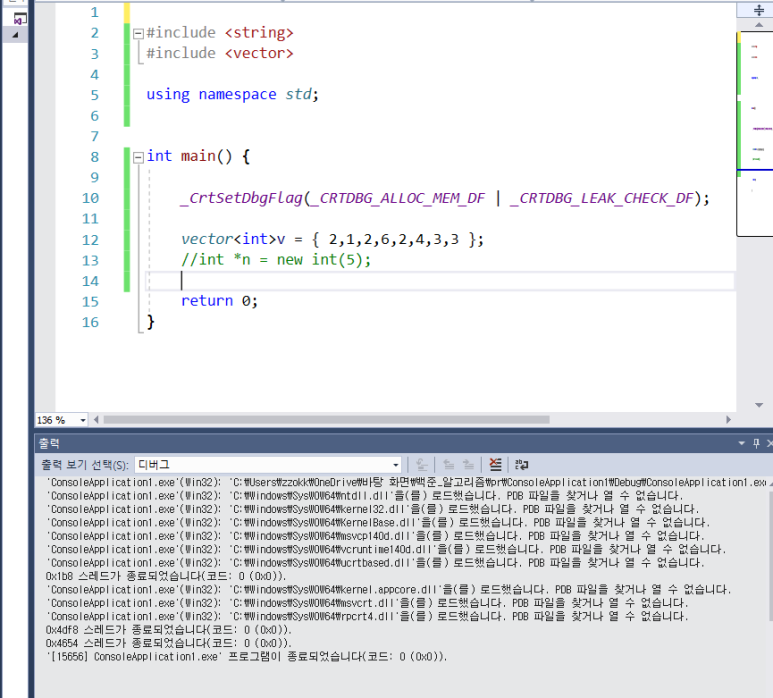
-
메모리 릭 발생 코드
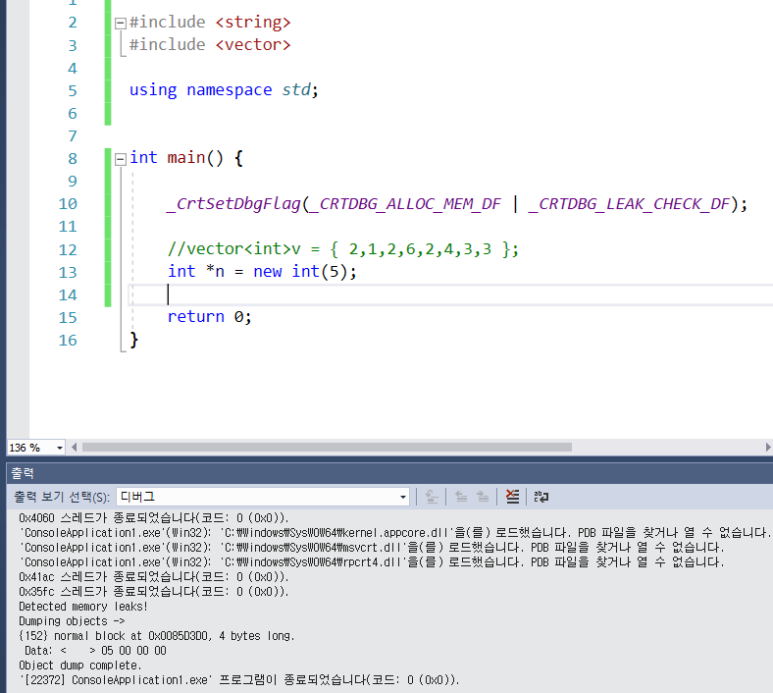
- 클래스 형식을 데이터로 지역변수 벡터 사용하기
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class Cat
{
public :
explicit Cat(int age) : mAge{ age }
{
cout << "배고파" << endl;
}
void speak() const
{
cout << "야옹" << mAge << endl;
}
~Cat()
{
cout << " 집에 갈래 " << endl;
}
private:
int mAge;
};
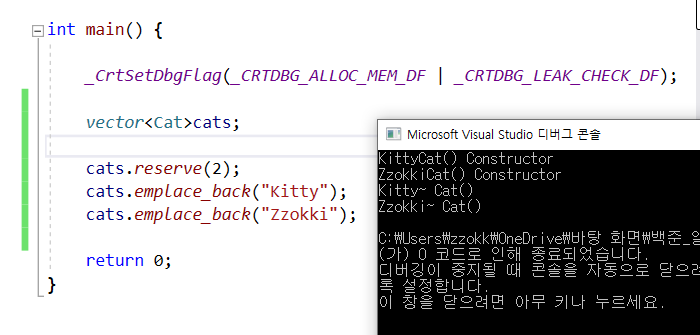
int main() {
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);
vector<Cat> cats;
cats.emplace_back(Cat(1));
cats.emplace_back(Cat(2));
cats.emplace_back(Cat(3));
cats.emplace_back(Cat(4));
return 0;
}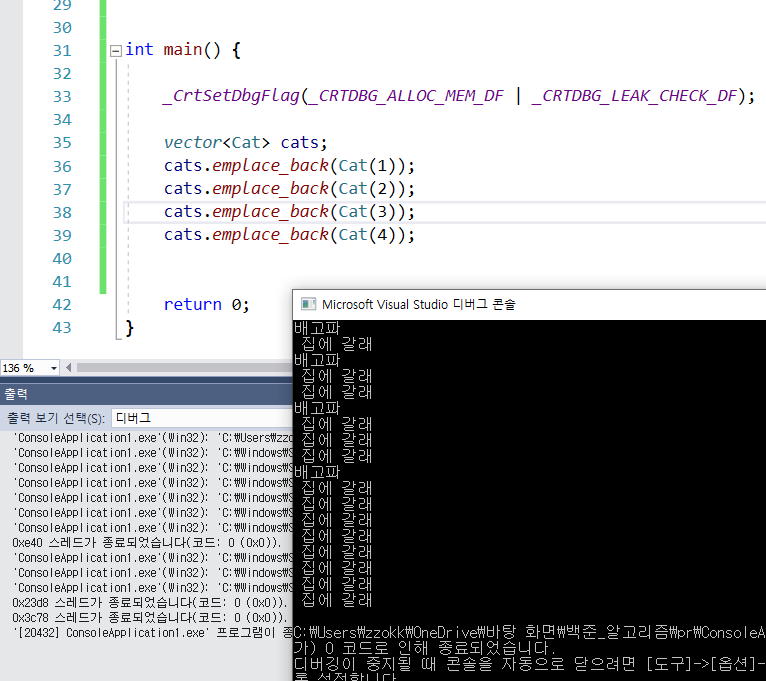
재할당과 소멸이 발생하는 것을 확인할 수 있다
추가적으로 메모리 릭도 발생하지 않는 것을 확인할 수 있다.
- class나, struct의 데이터를 동적할당 할 경우 유저가 직접해제해야 한다.
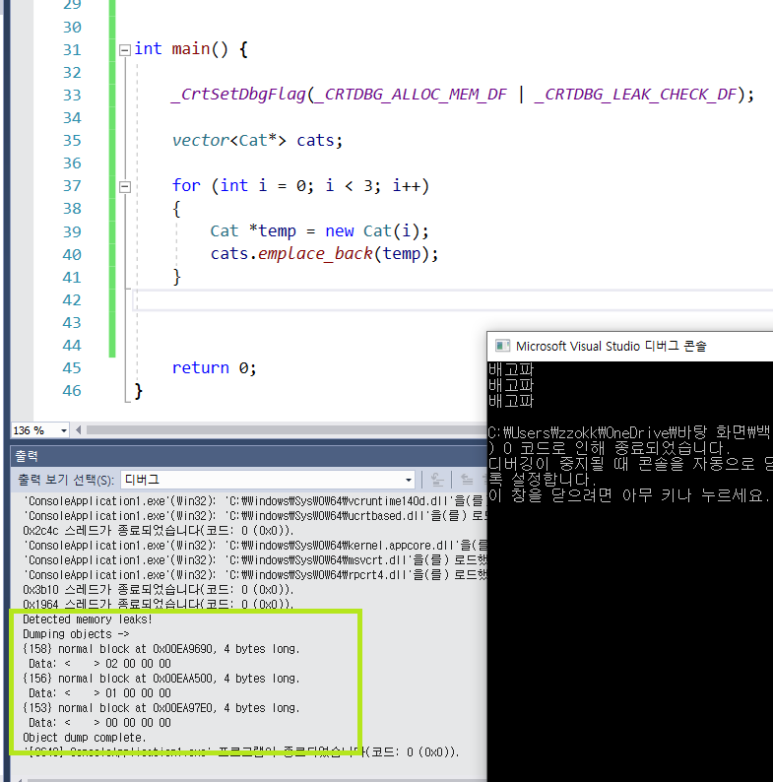
소멸자도 호출되지 않으며, 메모리 릭이 발생하는 것을 확인할 수 있다.
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class Cat
{
public :
explicit Cat(int age) : mAge{ age }
{
cout << "배고파" << endl;
}
void speak() const
{
cout << "야옹" << mAge << endl;
}
~Cat()
{
cout << " 집에 갈래 " << endl;
}
private:
int mAge;
};
int main() {
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);
vector<Cat*> cats;
for (int i = 0; i < 3; i++)
{
Cat *temp = new Cat(i);
cats.emplace_back(temp);
}
for (int i = 0; i < 3; i++)
{
delete cats[i];
}
return 0;
}이상 없으며, !!소멸자에서 우리가 멤버변수로 사용된 벡터를 해제할 필요까지는 없다.
- 프로그램 구동 중에 clear를 하더라도 이미 확장된 capacity는 그대로이다.
-
clear() 호출시.
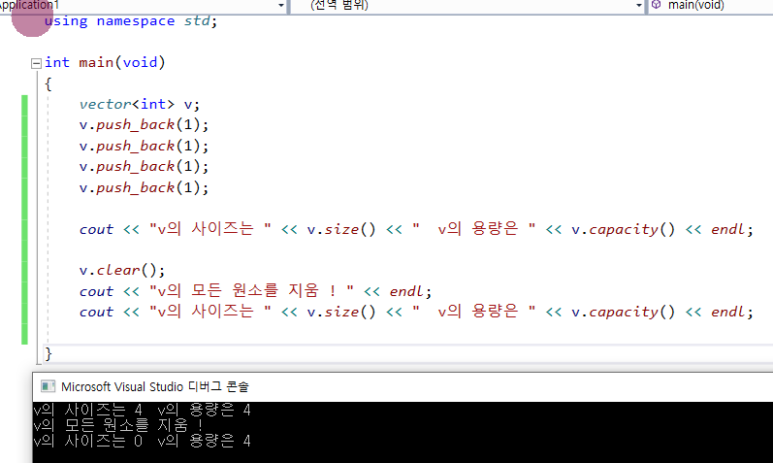
-
resize()로 size()를 축소하더라도
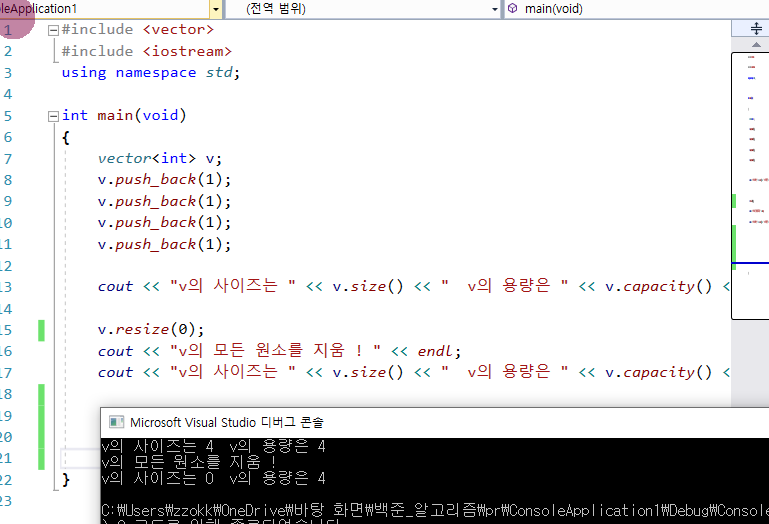
clear와 resize를 통해 모든 원소 비웠는데도 capacity는 남아있다!
capacity를 0으로 만들기
1) 빈벡터를 만들어 놓고, 사용완료된 벡터를 swap하는 방법을 통해 메모리를 회수할 수 있다.
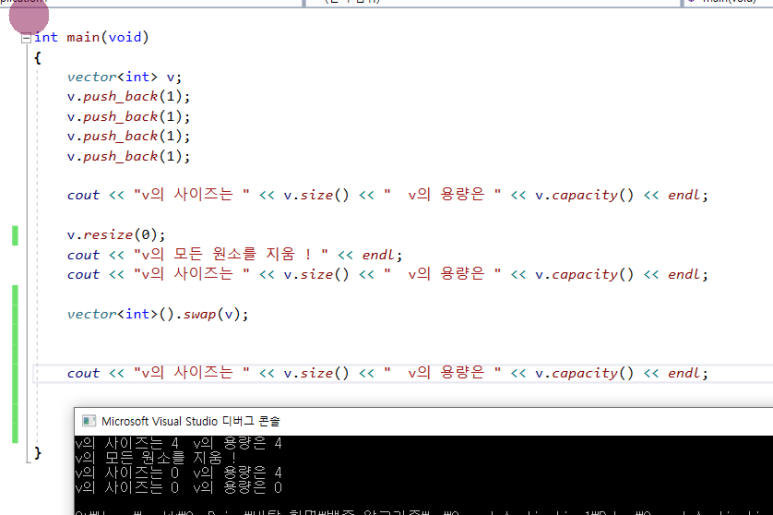
2) shrink_to_fit 이라는 함수 사용하기
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int> v;
v.push_back(1);
v.push_back(1);
v.push_back(1);
v.push_back(1);
cout << "v의 사이즈는 " << v.size() << " v의 용량은 " << v.capacity() << endl;
v.clear();
cout << "v의 모든 원소를 지움 ! " << endl;
cout << "v의 사이즈는 " << v.size() << " v의 용량은 " << v.capacity() << endl;
v.shrink_to_fit();
cout << "v의 사이즈는 " << v.size() << " v의 용량은 " << v.capacity() << endl;
}

11. shrink_to_fit 함수
: 사용되지 않는 내부 메모리를 size크기만큼 줄이는 역할을 한다. 즉 메모리 단편화를 예방한다.
1) 위에서 처럼 모두 사용된 메모리를 제거하는 용으로도 사용되지만,
2) push_back이나 emplace_back으로 인해 재할된 메모리 영역중 사용되지 않는 메모리를 해제하는 역할도 한다.
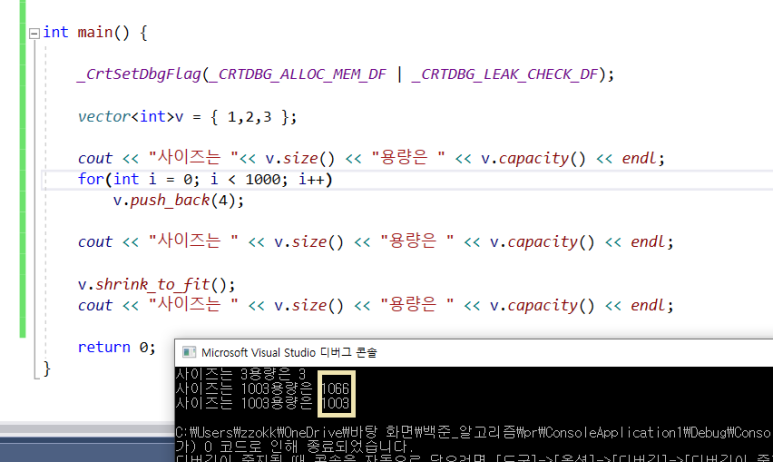
사용되는 size만큼만 용량이 축소된 것을 확인할 수 있따.
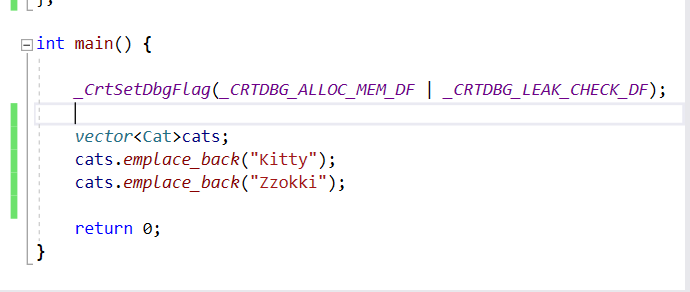
12. push_back vs emplace_back
: 차이점 push_back은 임시객체를 생성해서 move나 copy를 통해 벡터에
삽입을 하지만, emplace_back은 임시객체 생성 없이 벡터에 직접적으로
삽입이 가능하다.
1) push_back
: 임시 공간이 만들어지고 move나 copy를 통해
벡터의 마지막 공간으로 들어가는 것이다.
그림을 통해서 push_back은 임시 객체가 있어야 한다는 것을 확인할 수 있다.
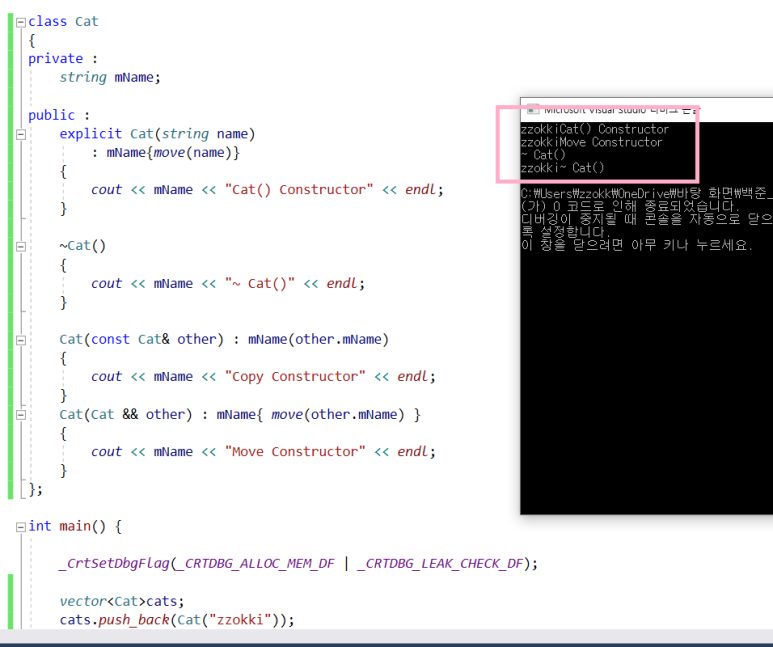
임시객체가 만들어지고 move되는 것을 확인할 수 있따.
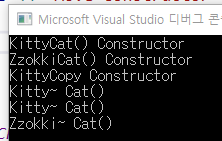
2) emplace_back
: emplace_back은 임시객체 생성, move동작없이 벡터 삽입이 가능한것이다. - 아래 그림을 통해 확인 가능하다.
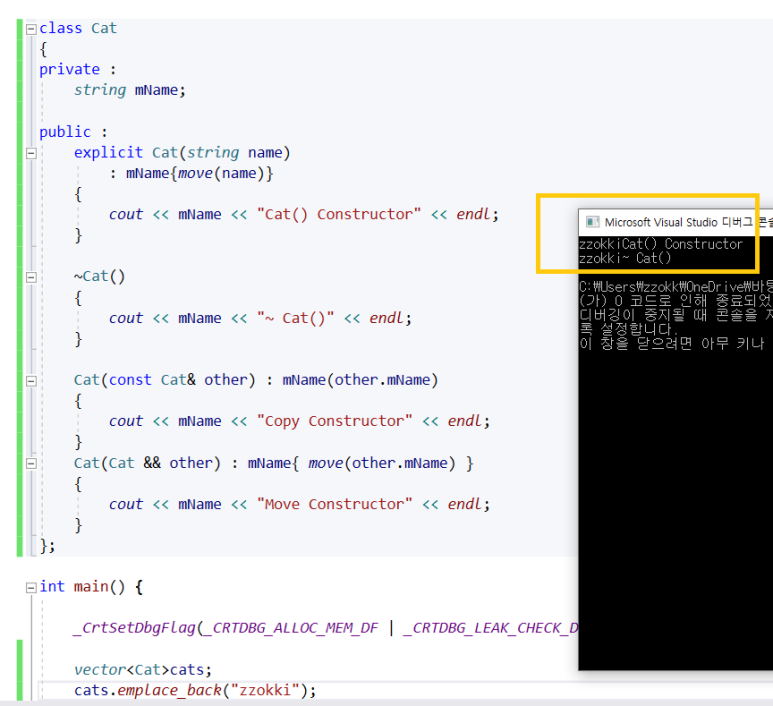
어떻게 만들어진 오브젝트를 가리킬수 있는지에 대한 문제가 잇는데
c++17부터는 레퍼런스로 받을 수 있따.
//비주얼스튜디오 c++17 설정해야 한다.
#include <iostream>
#include <string>
#include <iostream>
#include <vector>
using namespace std;
class Cat
{
public :
Cat(string name, int age)
:mName{ std::move(name) }, mAge{age}
{
}
void speak() const {
cout << "meow " << mName << " " << mAge << endl;
}
private :
string mName;
int mAge;
};
int main() {
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);
vector<Cat>cats;
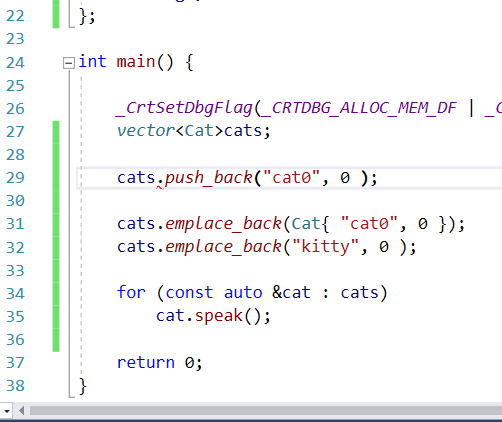
//cats.push_back("cat0", 0 );
cats.emplace_back(Cat{ "cat0", 0 });
Cat& Kitty = cats.emplace_back("kitty", 0 );
for (const auto &cat : cats)
cat.speak();
Kitty.speak();
return 0;
}
3) emplace로 객체를 넘길 경우
- L-value가 들어오면 copy가 발생하고,
- R-value가 들어오면 move가 발생한다.
13. 접근 : at() vs [] 인덱스 접근
: 궁극적인 차이는 범위 점검을 하느냐, 안하느냐 이다.
[] 연산자는 범위점검을 하지않고, at()함수는 범위 점검을 한다.
[]연산자 접근 도중 범위 초과시 디버깅 에러 발생하며,
at() 사용 중 범위 초과시 예외처리 에러가 발생한다.
https://blog.naver.com/kimwontae466/222405084275
14. for 문의 3가지 형태 - 코드 없는 프로그래밍 참고
-
index, iterator, ranged_based 총 3가지가 있는데 효율은 비슷하다.
-
반드시 index로 for문을 사용해야하는 경우가 있다.
: for문 안에서 size의 값이 증가하는 경우에는 반드시 index for문을 사용해야 한다.
1) index로 돌렸을때
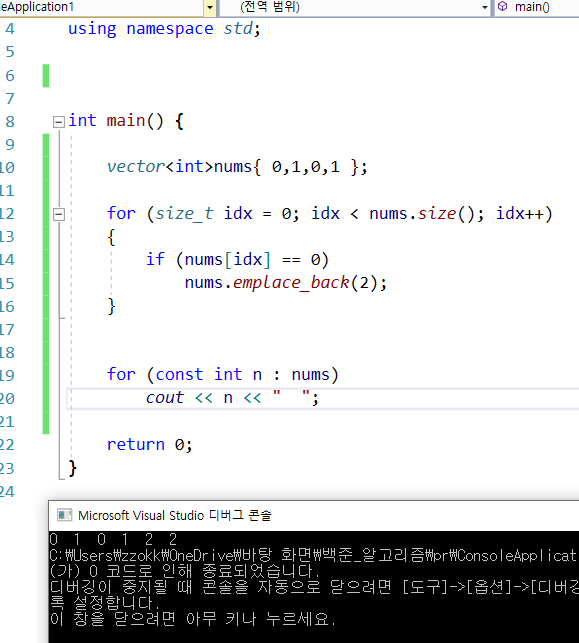
2) iterator로 돌렸을 때
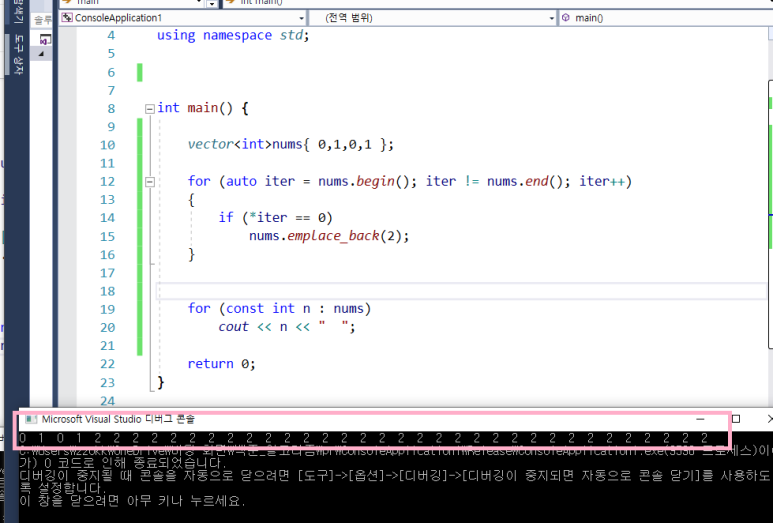
-> 어라??
3) ranged_base for 문
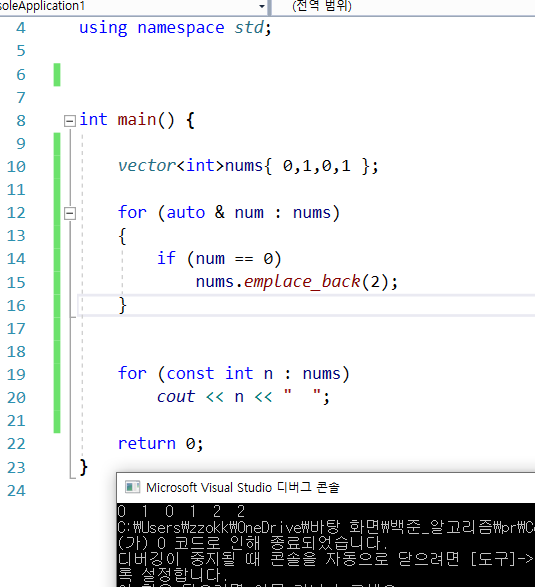
-> 라이브러리 마다 다르다고 한다.
=> iterator에서 삽입이 왜이리 많이도 일어난 이유??
: 벡터의 사이즈가 증가하면서 capacity와 동일하면 새로운 메모리가 생기고 move 및 복사가 일어나는데 interator의 경우에는 새롭게 생긴 메모리로 옮겨지는 것이 아니고,
기존 메모리를 계속해서 가리키고 있는 상태에서 증감이 되는 것이다.
end()값은 복사된 메모리의 끝을 가리키고 있다.
그래서 재할당이 일어날수록 삽입이 더 많이 발생한다.
- 인덱스 for 문이 이상 없는 이유는 포인터가 새로운 메모리를 가리키고,
갱신되는 인덱스 값을 통해서 갱신된 메모리에서의 인덱스 값을 보기 때문에 이상이 없다
결론 : for문 안에서 size의 값이 증가하는 경우에는 반드시 index for문을 사용해야 한다.
15. 이터레이터로 erase() 사용하기
주의할 점 : interator로 제거하면 해당 컨테이너를 재활용할 수 없다!
알아야 할점 : 반환값으로 다음 컨테이너를 가리킨다.
1) 문제 없는 상황
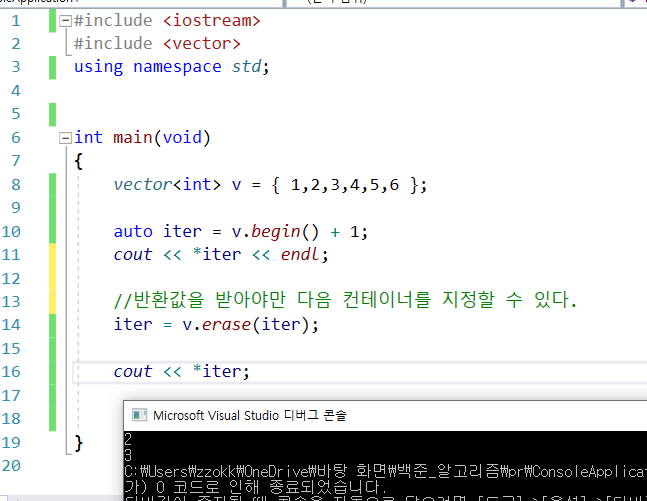
반환 받아서 출력이 정상적으로 나왔다.
증감 연산하지도 않았는데, 제거된 값의 다음 컨테이너가 출력됨을 확인할 수 있다.
2) 문제 발생하는 코드 - 1
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int>v = { 1,2,3,4,5 };
auto iter = v.begin() + 1;
cout << *iter << endl;
v.erase(iter);
cout << *iter << endl;
return 0;
}

erase된 데이터를 다시 참조하려고 해서 문제가 발생한 것이다.
2) 문제 발생하는 코드 2
: 해결해봐라~
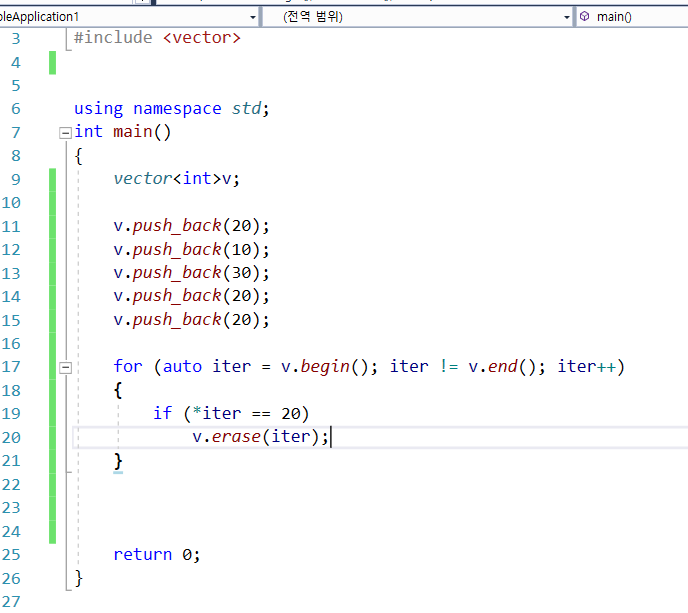
찾는 데이터가 없어짐과 동시에 이터레이터 방향 손실이다.
해결방법
가) 이터레이터로 해결하기 : 알아야 할 점들이 많다.
for문에서 증감식을 제거한 후, 예외처리해야 한다.
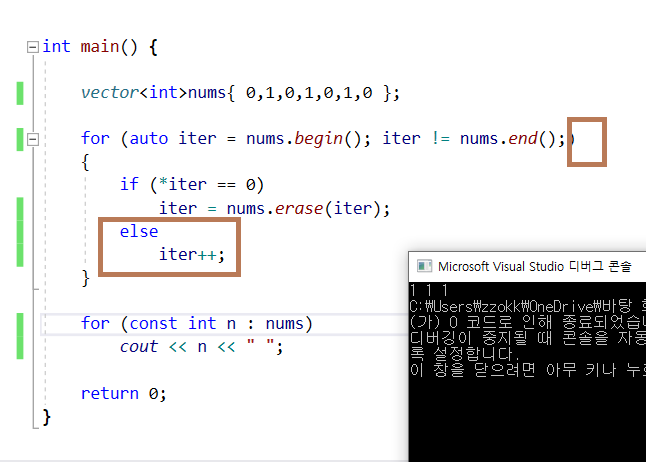
- 증감식이 for문 끝에 있으면 에러 발생한다.
1) erase 를 제거 한후 반환값으로 다음 이터레이터를 반환하게 된다.
2) for문 뒤에 증감이 있을 경우, 다음 이터레이터에 대한 증감 연산자로 인해 우리들이 예상하지 못하는 건너 뛰는 문제가 생길 여지가 있다.
예를 통해 확인해보자.
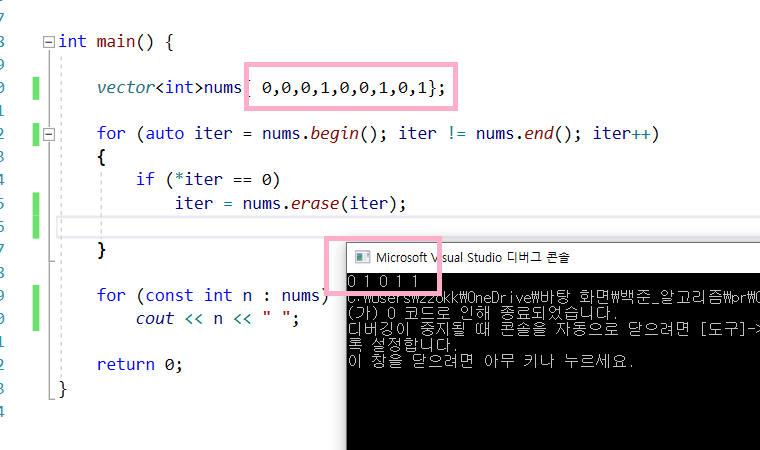
삭제된 0 바로 옆에 인접한 0값이 삭제되지 않는 것을 확인할 수 있다.
- 추가 예 : 마지막 컨테이너에 0이 있을 경우
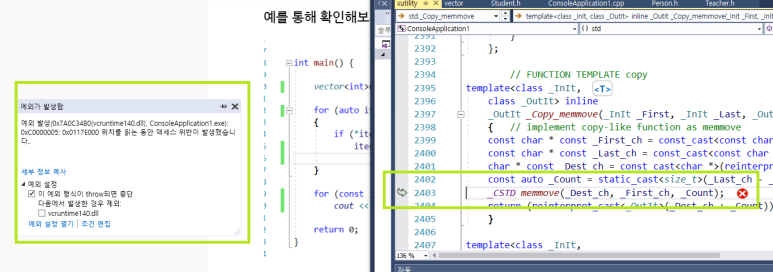
end() 연산자 넘어서 데이터를 접근하려고 해서 문제 발생
=> 정말 주의해야 한다.
나) 인덱스로 해결하기 : 안전하다.
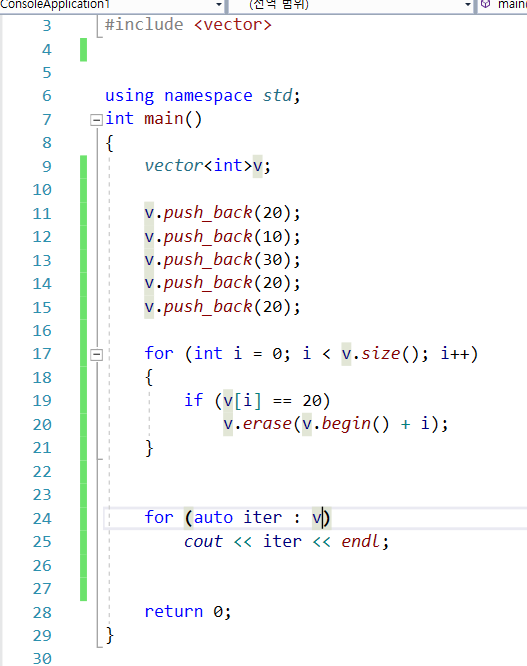
하지만, erase의 시간복잡도는 O(n)으로 효율이 꽝이다 라는 것을 생각하고, 사용을 줄이자.
😜16. erase / remove : 정말 중요!
: 코드 없는 프로그래밍 참고 / 복습 많이 해야한다.
가) erase 함수는 시간 복잡도는 O(n)이다.
왜냐하면 사이즈가 10인 벡터가 있는데 인덱스 2번값을 지운다면
인덱스 3~ 9까지의 값을 앞으로 한칸씩 이동해야 하므로
만약에 for문에서 여러번의 erase가 진행되면 할때마다 O(n)이
발생하므로 성능이 좋지 않다.
나) remove 함수의 시퀀스
😜 알게 된점 : 그림을 참고하자!
1) 3번째 인자값과 일치한 포인터와 일치하지 않는 컨테이너를
가리키는 포인터 2개가 만들어져서 진행된다.
-> erase와는 다르게 제거된 자리로 이후의 컨테이너들이 자리를 이동하는 시퀀스가 아니라, 2번째 포인터가 가리키는 밸류가 제거된 자리로 move, copy가 일어난다.
2) 일반적인 int형은 move가 아닌 복사가 진행된다고 한다.

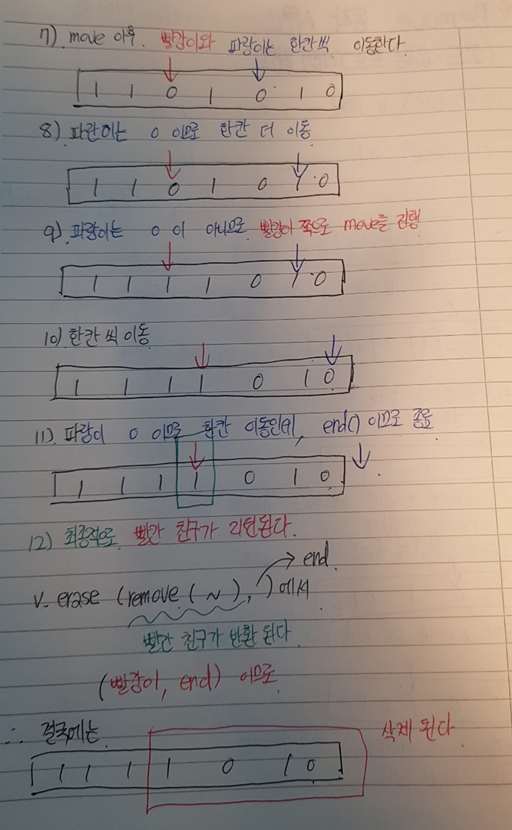
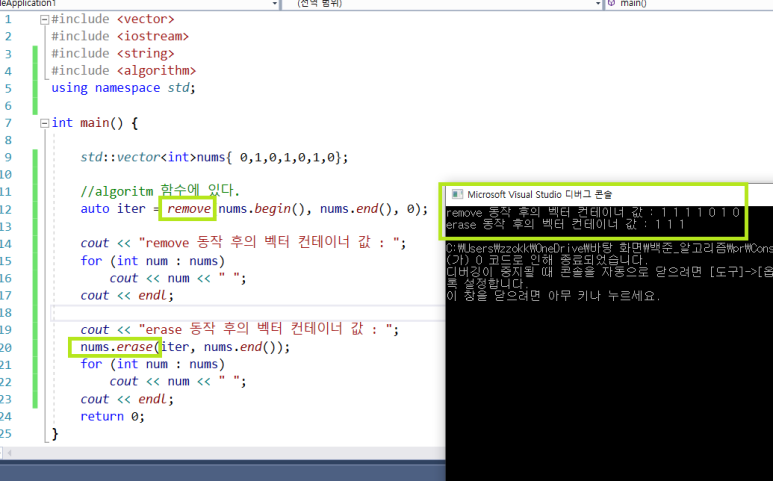
결과 값과 그림의 결과값이 일치한다는 것을 확인할 수 있다.
다) erase와 remove를 함께 쓰면 좋은 점 .
: 가)에서 erase 한번 콜될때 마다 O(n)이 여러번 발생하지만,
erase와 remove를 함께 쓰면 O(n)이 한번만 발생하게 된다.
17. 연산자 오버로딩을 이용한 삽입
: ㅇㅇㅇ
18. resize vs reserve
- resize는 데이터의 개수와 내부용량 변경
- reserve는 내부 용량을 변경
장점
1) 인덱스 접근이 가능하므로 순차 stl 중에서 빠른 데이터 접근이 가능하다. O(1)이다.
2) 정적인 배열과는 다르게 유저의 수요에 따라 데이터 사이즈 확장이 가능해서 크기가 정해진 배열보다는 사용적이 면에서 좋다.
단점
1) size와 capacity가 동일한 상태에서 삽입이 일어난다면 메모리 재할당 과 복사 , 기존 메모리 제거에 대한 문제가 있다.
2) 앞이나 중간에 insert, erase를 통해 데이터 삽입, 삭제 시
기존의 데이터를 옆의 공간으로 복사해야 하는 문제가 있어서 효율이 좋지 않다.
정리
1) push_back의 경우 임시 객체 생성 및 move가 발생하므로
임시객체 생성 및 move가 발생하지 않는 emplace_back 을 사용하자.
2) shrink_to_fit으로 메모리 단편화를 예방하자.
3) reserve를 사용해서 메모리 재할당 , 복사를 예방하자.
4) 알고리즘에서는 데이터를 받을 경우, 선언과 동시에 초기화를 하자.
5) iterator로 erase 할때는 정말 주의해야 한다.
