세줄 요약
- N+1문제를 해결하기 위해서, 지연 로딩으로 엔티티 연결 관계를 수정해야 한다.
- 지연 로딩에서도 결국 필요한 엔티티에 접근할 때마다 쿼리가 발생한다.
- 쿼리의 수를 줄이기 위해서는 일반 Join+DTO화, Fetch Join 등을 사용할 수 있는데, 단순 조회에는 일반Join을, 영속성 컨텍스트에 엔티티들을 올려야 할때는 Fetch Join이 유리하다.
테스트 환경
현재 유저-멘토-멘토링 가능 시간 이 각각 일대일, 일대다로 연결되어 있다.
즉시로딩이기 때문에 데이터가 적을 때는 크게 문제 없지만, 데이터가 많아진다면 N+1이슈로 성능에 크게 문제가 생길 수 있다.
이후에 연결된 엔티티들이 추가된다면, 해당 엔티티들까지 불러와지므로 로딩관계들을 지연 로딩으로 수정한 후, 필요한 데이터만 쿼리로 가져올 것이다.
테스트 환경은 500명의 유저가 모두 멘토로 가입하였고, 각자 3개의 멘토링 가능 시간을 가지고 있어 총 1500개가 존재하는 상태이다.
배포 서버에서 테스트하고 싶었지만, RDS의 용량을 고려하여 로컬환경에서 테스트를 진행하였다.
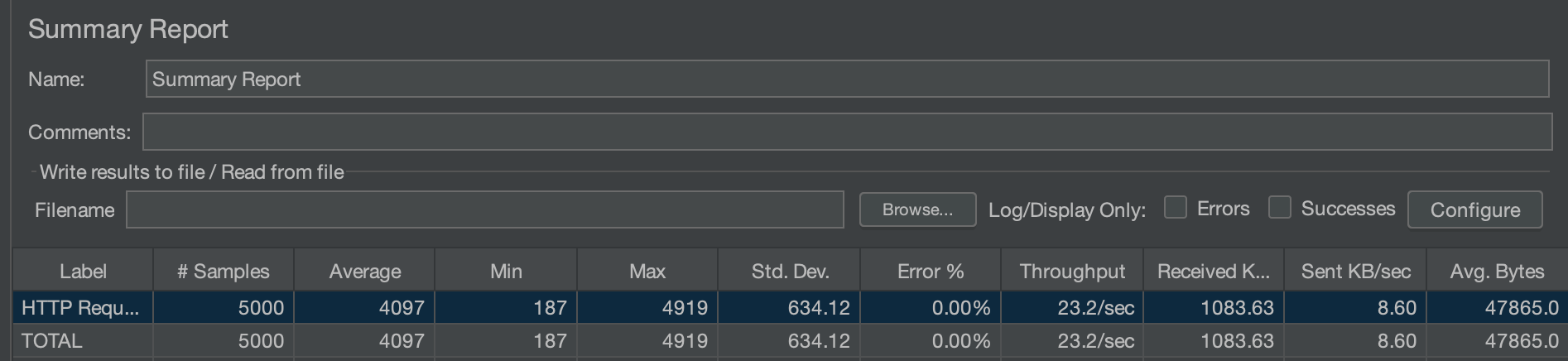
즉시로딩 상황의 테스트 결과
500명의 멘토 리스트를 불러오는 API를 100개의 쓰레드가 10초간 50번 실행한다.
평균적으로 응답시간이 4087MS가 소요되었으며, 멘토와 연관된 엔티티들이 로딩되었으므로 굉장히 응답시간이 많이 소모된 것을 확인할 수 있다.
기존의 멘토 리스트 불러오는 방법
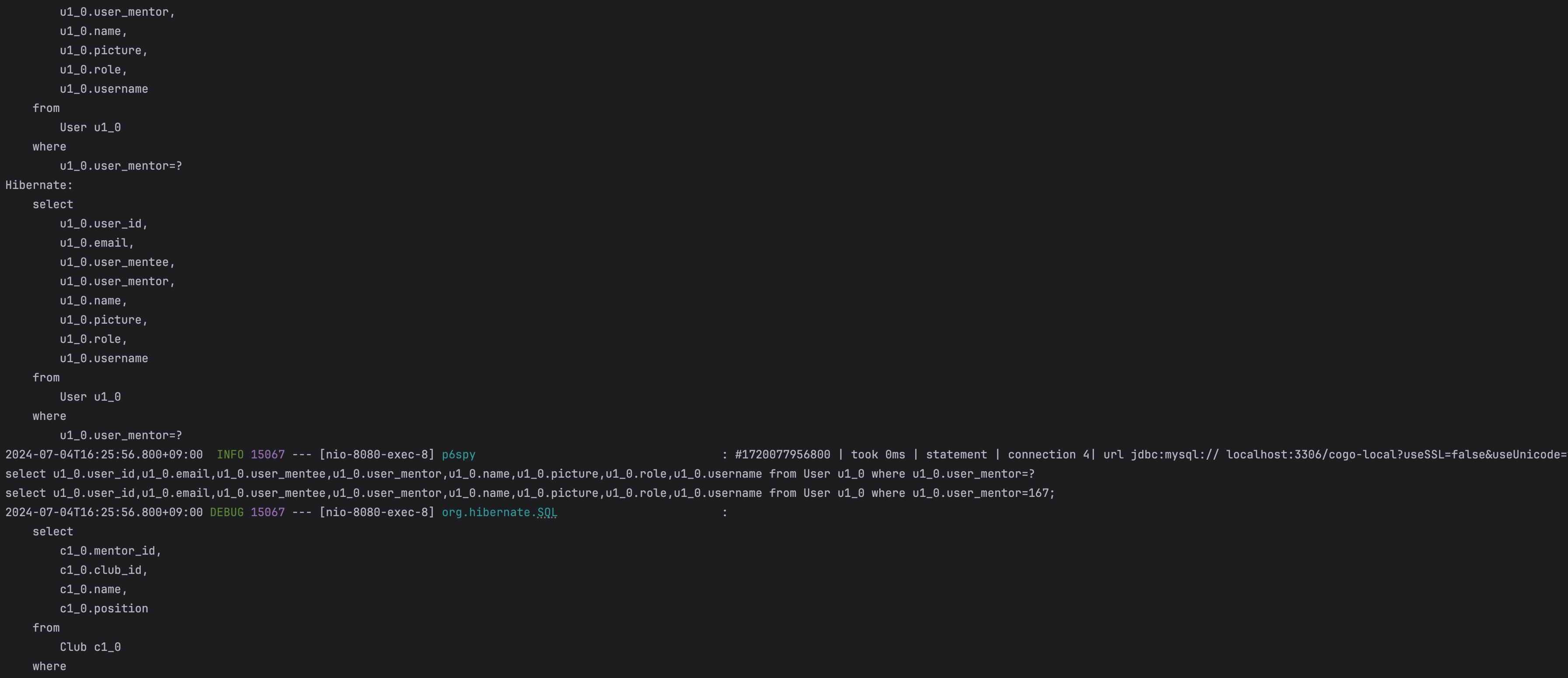
기존의 방법으로는 JPARepository에서 제공하는 메소드 이름으로 JPQL을 생성해주는 방식을 사용하였다.
public List<ResponseMentorListInfo> getMentorDtoListByPart(String part) { List<Mentor> mentorList = findMentorListByPart(part); //파트에 해당하는 멘토 전부 가져오기 List<ResponseMentorListInfo> dtoList = new ArrayList<>(); for (Mentor mentor : mentorList) { //찾아온 멘토들의 유저정보, 멘토정보를 가져와서 필요한 데이터들 dto로 생성 User user = userRepository.findByMentor(mentor); dtoList.add(ResponseMentorListInfo.toDto(mentor, user)); } return dtoList; }영속성 컨텍스트에 User엔티티와 Mentor엔티티들이 올라와있지 않으므로 멘토의 수대로 조회 쿼리가 발생한다.
스택 트레이스의 일부 사진이지만, 실제로 테스트 데이터베이스에서 가져온 멘토의 수대로 User 조회 쿼리가 발생하고 있음을 확인할 수 있다.테스트 코드
처음에는 fetch join을 사용할 수 있을까 라는 생각에 fetch join을 사용한 쿼리를 작성했다.
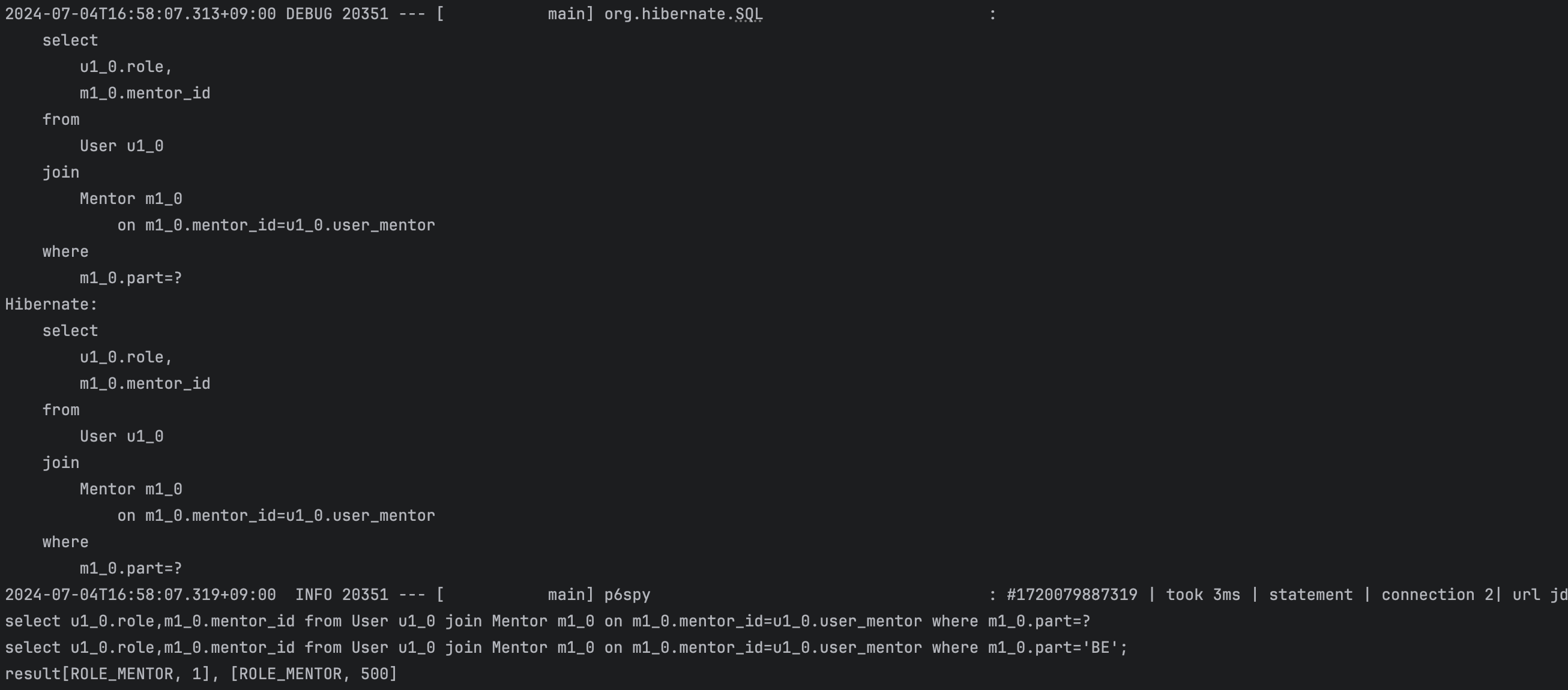
String part="BE"; List<Tuple> result= queryFactory .select(user.name, mentor.id) .from(user) .join(user.mentor, mentor).fetchJoin() .where(mentor.part.eq(part)) .fetch(); System.out.println("result"+ result.get(0)+", "+result.get(499));하지만 fetch join은 select문에 조인의 소유자가 포함되어야 한다.
그 이유는 Hibernate가 FETCH JOIN을 사용하여 엔티티와 그 관련 엔티티를 함께 로드하고, 이를 캐시에 저장하는데, 만약 조인의 소유자가 SELECT 목록에 포함되지 않으면, Hibernate는 이를 처리할 수 없다.두번째 테스트 코드
멘토 리스트를 불러오는 API에서 User전체 정보를 가져올 필요 없고, 일반 join을 사용하는 쿼리에서 필요한 정보들을 뽑아온다면 N+1문제가 발생하지 않을 것이기 때문에 일반 join을 사용하는 코드로 변경하였다.
@Test public void getMentorListByFetch(){ String searchPart="BE"; List<Tuple> result= queryFactory .select(user.role, mentor.id) .from(user) .join(user.mentor, mentor) .where(mentor.part.eq(searchPart)) .fetch(); System.out.println("result"+ result.get(0)+", "+result.get(499)); }아래는 테스트 코드의 결과이다.
실제로 한번의 쿼리만 발생하며, 2개의 Tuple이 잘 가져와지는 것으로 봐서 N+1문제가 발생하지 않음을 알 수 있다.세번째 테스트 코드
Fetch join이 위에서 에러가 난 이유는 조인의 소유자가 SELECT 목록에 들어있지 않아서였다.
그렇다면 소유자를 포함시키고 나온 결과물을 통해 DTO에 정보를 주입한다면 문제가 없을 것 같다.
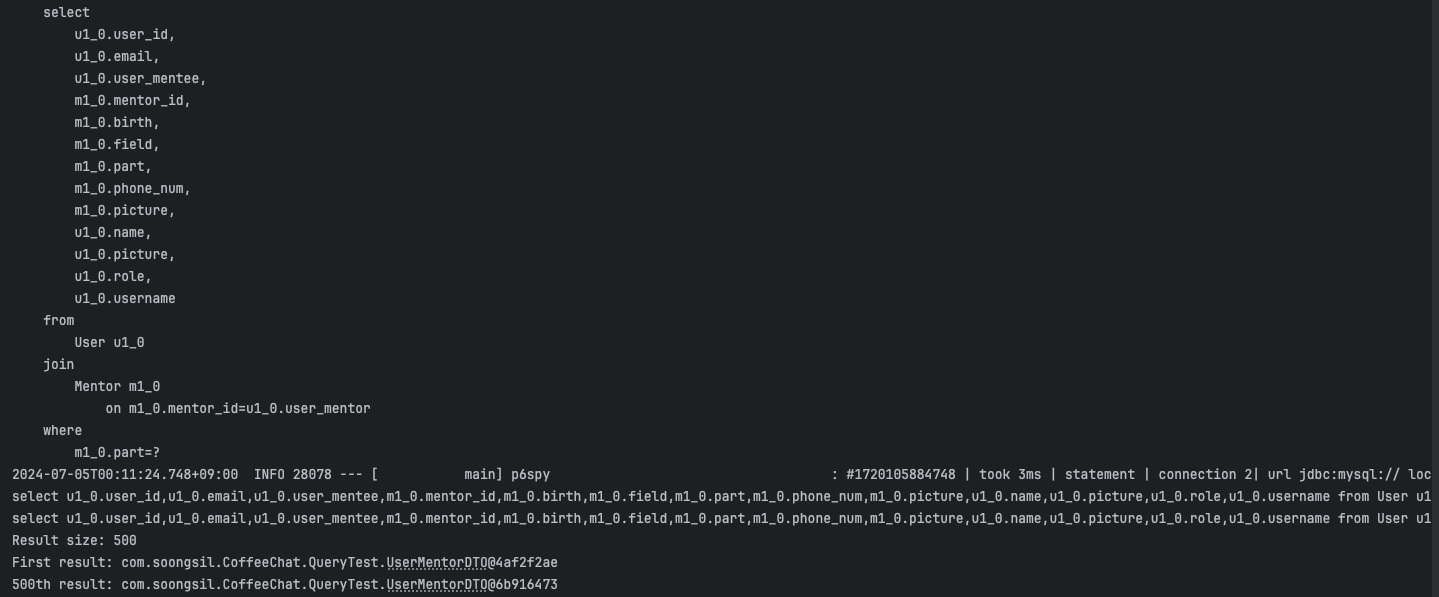
User와 Mentor가 지연로딩 관계이지만, 둘 다 한번에 로드되기 때문이다.@Test public void getMentorListByFetch() { String searchPart = "BE"; QUser user = QUser.user; QMentor mentor = QMentor.mentor; // Fetch join을 사용하여 엔티티를 로드 List<User> users = queryFactory .selectFrom(user) .join(user.mentor, mentor).fetchJoin() .where(mentor.part.eq(searchPart)) .fetch(); // 필요한 필드만 추출하여 DTO로 변환 List<UserMentorDTO> result = users.stream() .map(u -> new UserMentorDTO(u.getRole(), u.getMentor().getId())) .toList(); // 결과 크기 출력 System.out.println("Result size: " + result.size()); // 결과가 충분히 존재하는지 확인 if (result.size() > 0) { System.out.println("First result: " + result.get(0)); } if (result.size() > 499) { System.out.println("500th result: " + result.get(499)); } }다음은 테스트의 결과이다.
쿼리는 1회만 발생하였고, 결과물은 500개 모두 불러와지는 것을 확인할 수 있다.
성능 비교
2번째 방법(일반 Join)과 3번째 방법(Fetch Join)의 성능을 비교해보아야 한다.
간단하게 생각해보면 Fetch Join이 User엔티티와 Mentor엔티티를 통째로 영속성 컨텍스트에 로드하기 때문에 불필요한 데이터까지 영속성 컨텍스트에 로드하게 되고, 일반 Join이 더 좋은 성능을 낼 것이라고 생각된다.
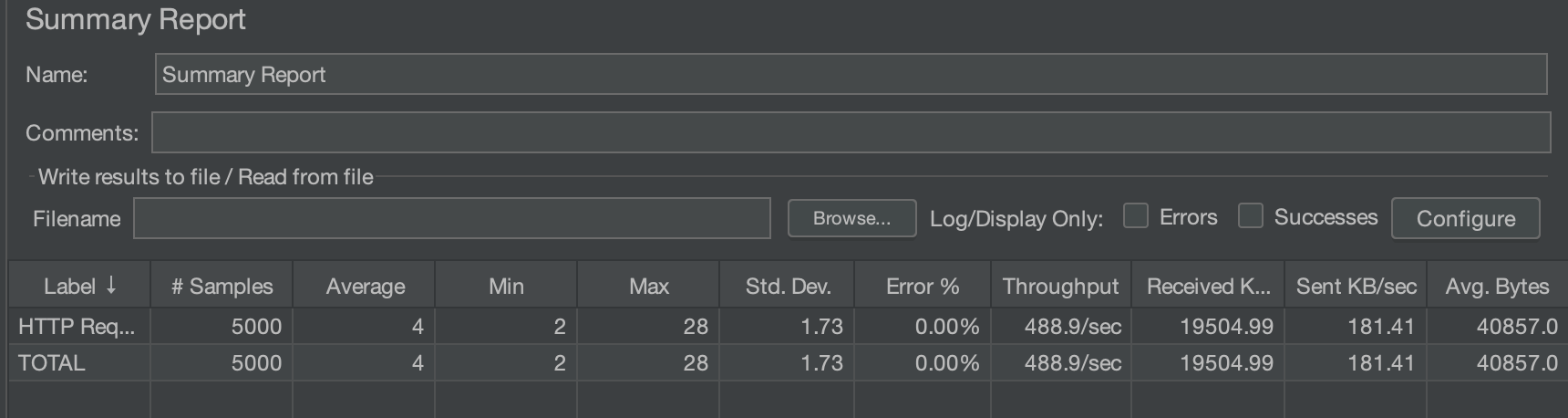
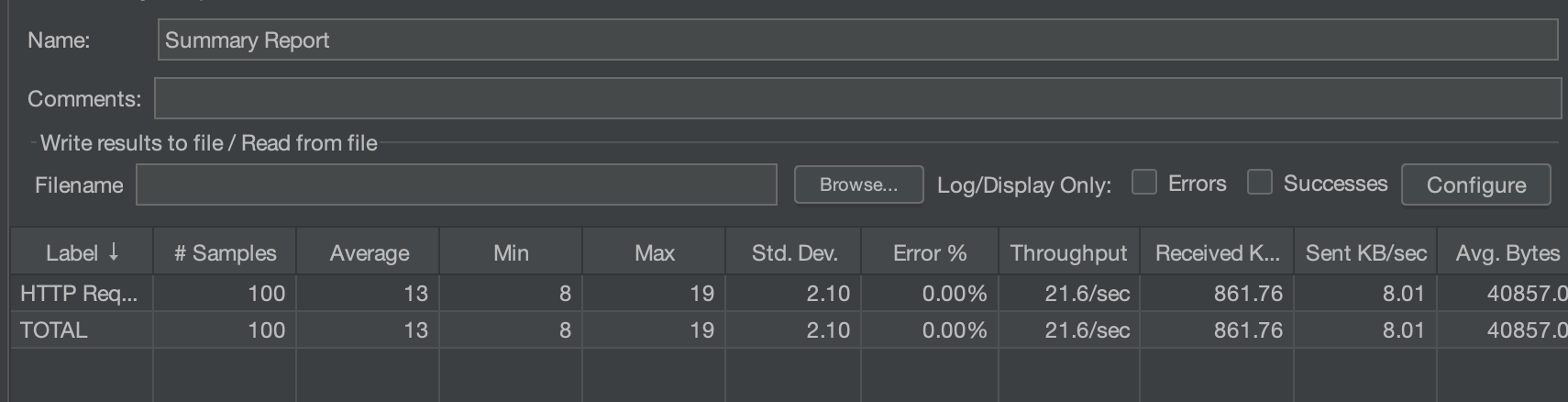
JMeter로 2가지 방법을 3가지 상황으로 비교해 보았다.일반 Join
100/10/50
10/5/10
200/60/120
코드(쿼리)public List<ResponseMentorListInfo> getMentorListByPart(String part) { return queryFactory .select(new QResponseMentorListInfo( mentor.picture, user.name.as("mentorName"), mentor.field, user.username, mentor.part)) .from(user) .join(user.mentor, mentor) .where(mentor.part.eq(part)) .fetch(); }
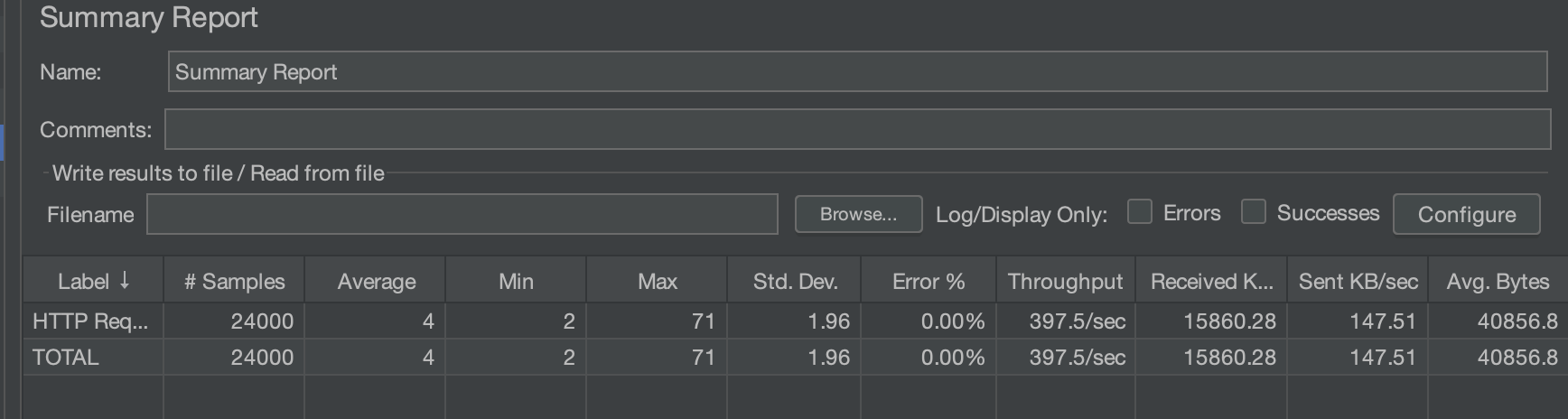
Fetch Join
100/10/50
10/5/10
200/60/120
레포지토리(쿼리)public List<ResponseMentorListInfo> getMentorListByPart2(String part) { List<User> users = queryFactory .selectFrom(user) .join(user.mentor, mentor).fetchJoin() .where(mentor.part.eq(part)) .fetch(); List<ResponseMentorListInfo> result=new ArrayList<>(); for (User user : users){ result.add(ResponseMentorListInfo.toDto(user.getMentor(), user)); } return result; }서비스(DTO로 옮기는 과정)
@Transactional public List<ResponseMentorListInfo> getMentorDtoListByPart(String part) { //return mentorRepository.getMentorListByPart(part); 일반join List<ResponseMentorListInfo> dtos=new ArrayList<>(); List<User> users=mentorRepository.getMentorListByPart2(part); for(User user:users){ dtos.add(ResponseMentorListInfo.toDto(user.getMentor(), user)); } return dtos; }레포지토리에서는 순수 데이터만 가져오고, DTO화하는 로직은 서비스단에서 처리하도록 수정하였다.
Fetch Join으로 User엔티티와 Mentor엔티티를 전부 영속성 컨텍스트에 올리기 때문에 추가적인 1개의 쿼리로 처리할 수 있었다.
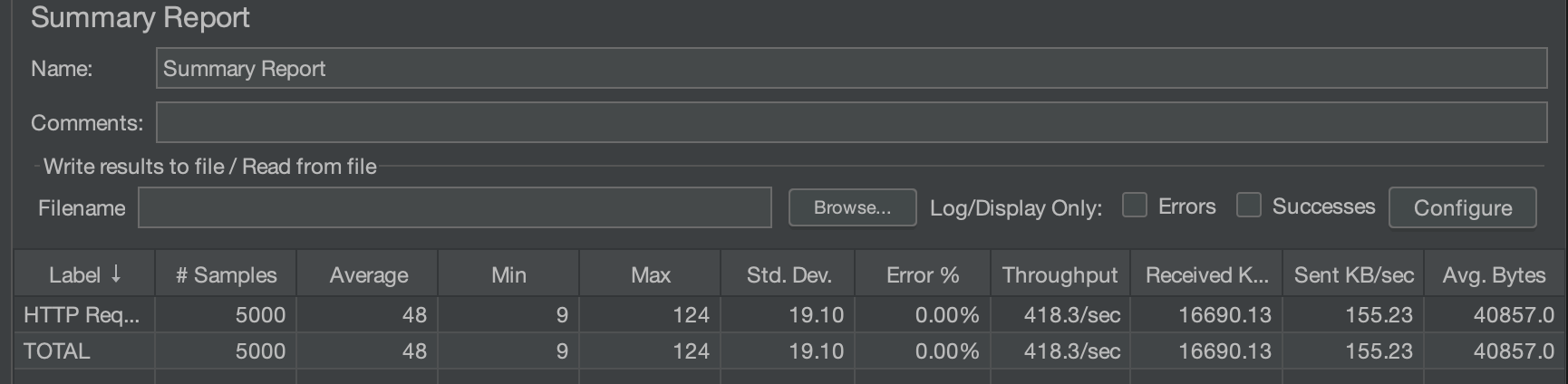
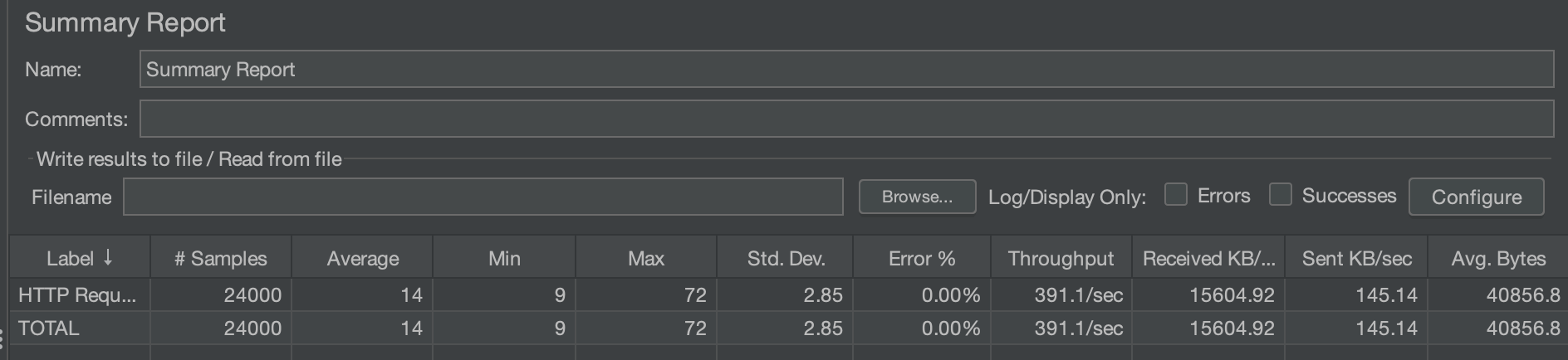
최종 결과
일단 2가지 방법 모두 기존의 즉시로딩 때보다 성능이 훨씬 좋아진 것은 자명하다.
하지만 생각보다 일반Join이 Fetch Join을 사용할 때보다 눈에 띌 정도의 성능차이를 만들어냈다.
원하는 필드만 select하여 로드하는 일반 join과 달리 mentor과 user의 모든 필드를 로드하는 fetch join이 성능 저하가 존재하기 때문이다.
즉, 일회적인 데이터 조회가 필요한 경우(ex. DTO) 일반 Join을 사용하고, 연관 엔티티들을 영속성 컨텍스트에 로드하여 작업을 해야 하는 경우 Fetch join을 사용하면 될 듯하다.
추가적으로, 실제 서비스에는 등록된 멘토의 수가 그렇게 많지 않을 것이므로 redis로 캐시에 올려둔 후 성능 비교를 진행해 보아도 좋을 것 같다.
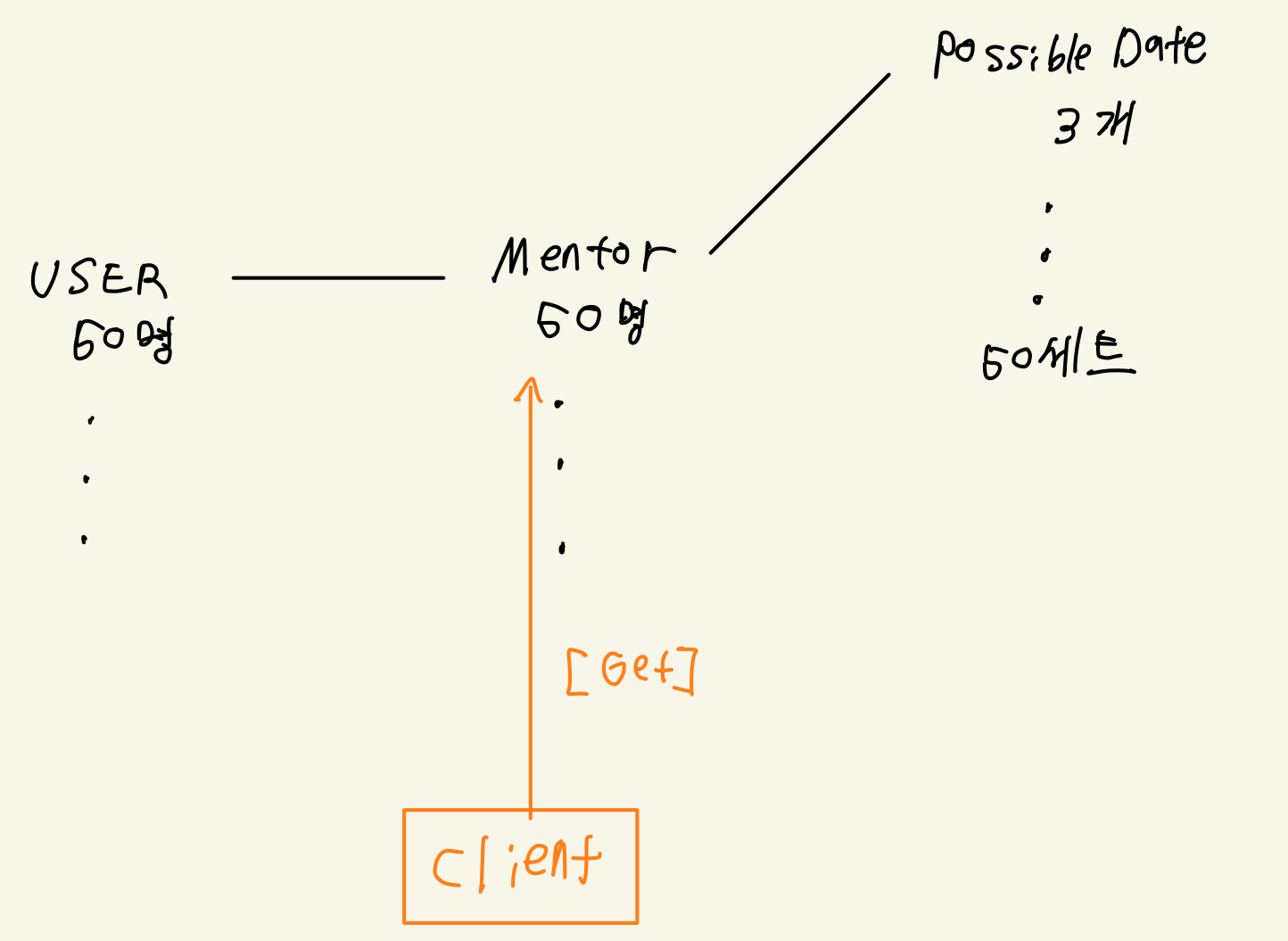
3개의 엔티티 join
현재 각 멘토가 등록해 놓은 커피챗 가능 시간대를 불러오는 API의 서비스 로직이다.
User user = userRepository.findByUsername(username); Mentor mentor = user.getMentor(); Set<PossibleDate> possibleDateSet = mentor.getPossibleDates(); Iterator<PossibleDate> iter = possibleDateSet.iterator(); List<PossibleDateRequestDto> dtoList = new ArrayList<>(); while (iter.hasNext()) { dtoList.add(PossibleDateRequestDto.toDto(iter.next())); } return dtoList;보다시피, 쿼리가 3회 발생한다.
1. findByUsername
2. user.getMentor()
3. mentor.getPossibleDates()
이전에 즉시 로딩으로 엔티티간의 관계들이 연결되어 있을 때는 제일 처음 1번 쿼리만 나가도 영속성 컨텍스트에 전부 로딩되었으므로 큰 상관 없었지만, 지연로딩으로 바꾼 지금은 쿼리가 3번 나가야 로딩이 된다.바꾼 로직
public List<PossibleDateRequestDto> getPossibleDatesByUsername(String username) { return queryFactory. select(new QPossibleDateRequestDto( possibleDate.date, possibleDate.startTime, possibleDate.endTime )) .from(user) .join(user.mentor, mentor) .join(mentor.possibleDates, possibleDate) .where(user.username.eq(username)) .fetch(); }user->mentor는 접근 가능해도, mentor->user은 접근하지 못하는 단방향 일대일 연결관계로 인하여 user에서 시작하여 possibleDate까지 join을 뻗어가도록 쿼리를 작성하였다.
수정 결과 쿼리 1번으로 데이터를 불러올 수 있었다.결과
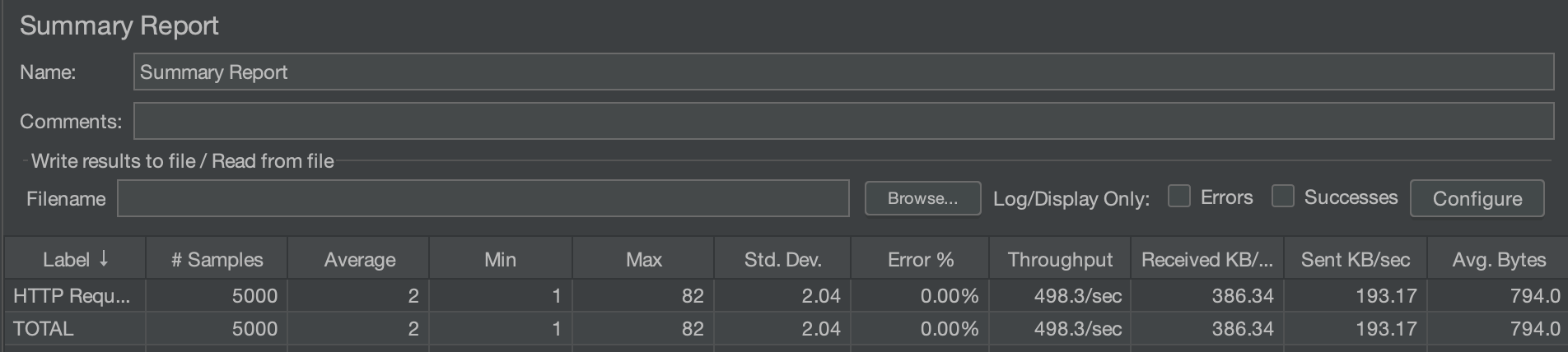
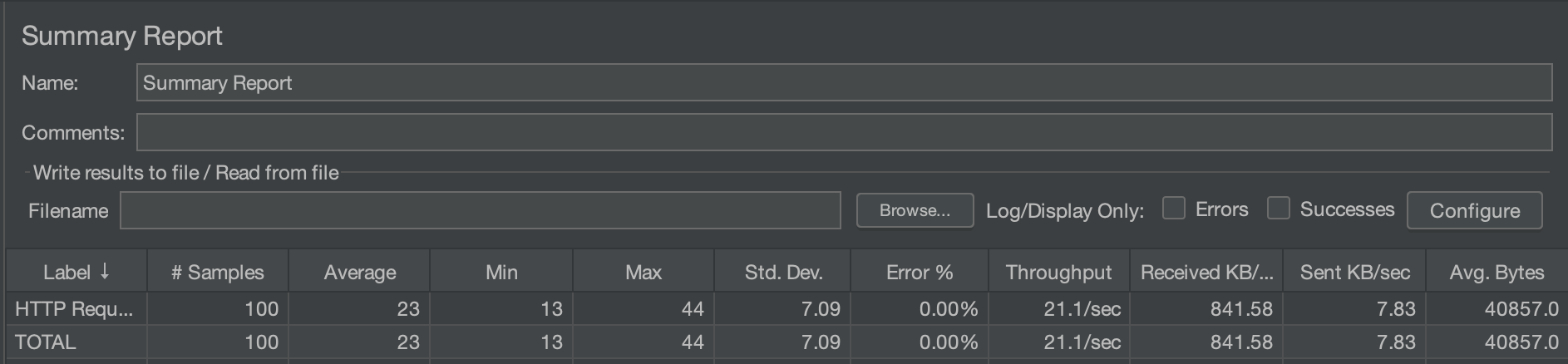
수정 전 (100/10/50)
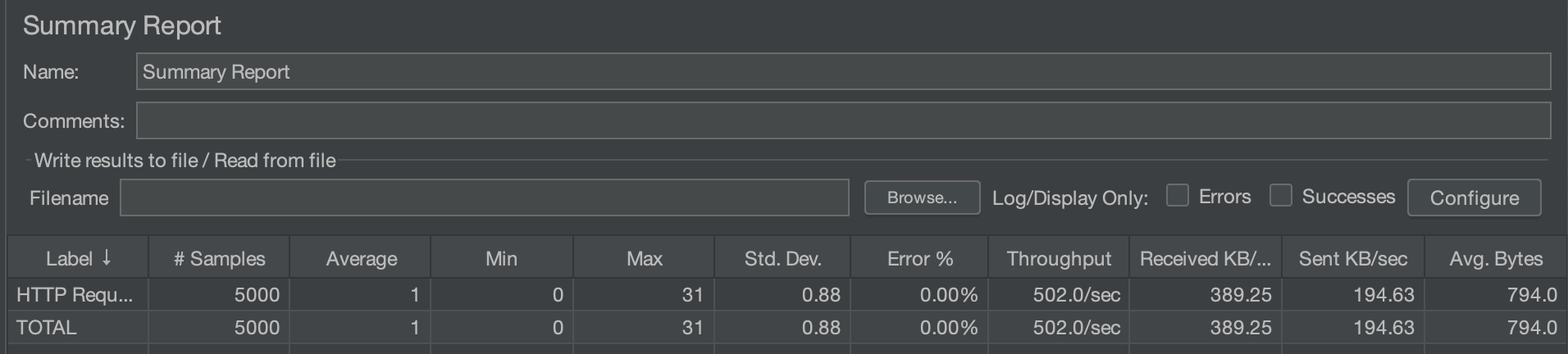
수정 후 (100/10/50)
사실 다이나믹한 차이는 없다.
Max값만 3배에 가까운 차이를 보이지만, 평균적인 시간 차이는 크게 차이나지 않는다.
테스트용 DB에 많은 더미데이터를 넣어두지 않았기 때문에 로딩되는 데이터의 갯수 자체가 적기 때문인 듯하다.
하지만 로직을 수정하는 데에 큰 시간을 투자하지 않았기 때문에 빠르게 수정할 수 있는 비효율적인 로직들은 전부 수정하고자 한다.