Sequence-to-Sequence 란?
시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) 는 입력된 시퀀스(시계열)로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델입니다. 예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translation)이 그러한 대표적인 예인데, 입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇으로 만들 수 있고, 입력 시퀀스와 출력 시퀀스를 각각 입력 문장과 번역 문장으로 만들면 번역기로 만들 수 있습니다. 그 외에도 내용 요약(Text Summarization), STT(Speech to Text) 등에서 쓰일 수 있습니다.
Seq2seq의 원리
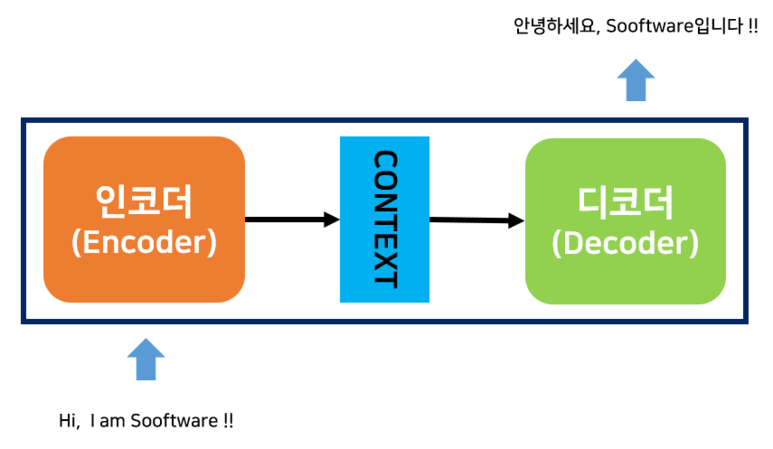
Seq2seq를 Encoder-Decoder 모델이라고도 많이들 부릅니다.
이름이 말해주듯이 2개의 모듈, Encoder와 Decoder가 등장합니다.
Encoder : 시계열 데이터 -> 컨텍스트 벡터 (Context Vector)
Decoder : 컨텍스트 벡터 (Context Vector) -> 다른 시계열 데이터
인코더(Encoder)
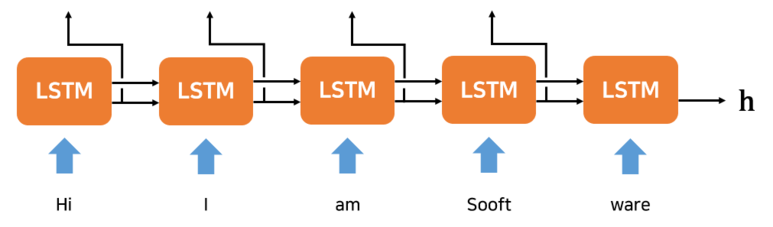
위의 그림처럼 Encoder는 RNN (or LSTM, GRU) 을 이용하여 데이터를
h(Hidden State Vector)로 변환합니다.
Encoder가 출력하는 벡터 h는 마지막 RNN 셀의 Hidden State 입니다.
즉, Encoder는 그냥 RNN을 이어놓은 것에 불과합니다.
여기서 주목할 점은 Encoder가 내놓는 Context Vector는 결국 마지막 RNN 셀의
Hidden State므로, 고정 길이 벡터라는 사실입니다.
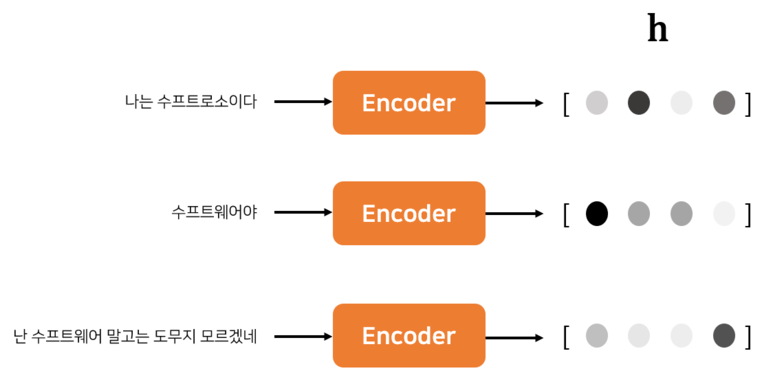
그래서 인코딩 한다라는 말은 결국 임의 길의의 시계열 데이터를 고정 길이 벡터로 변환하는 작업입니다.
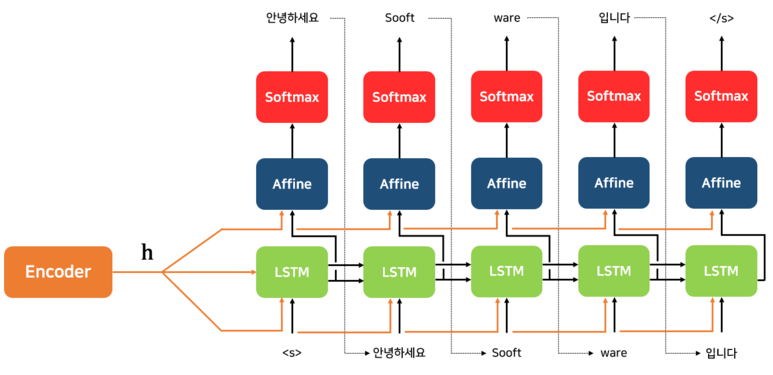
디코더(Decoder)
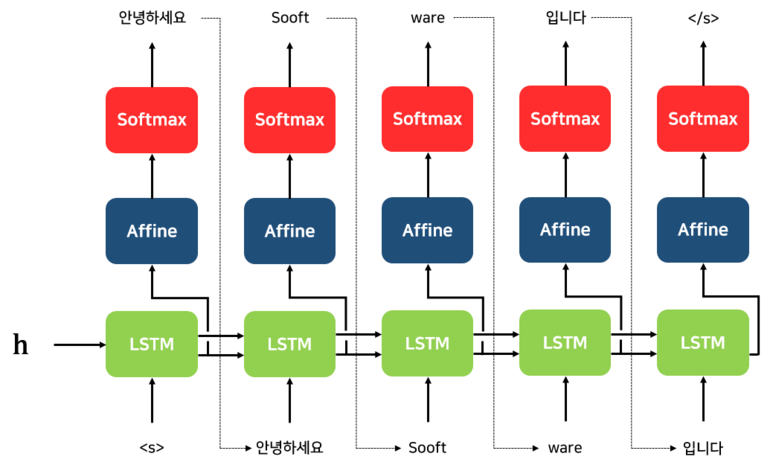
Decoder는 Encoder로부터 Context Vector (h)를 넘겨받습니다.
그리고 첫 입력으로 문장의 시작을 의미하는 심볼인 [s]가 들어갑니다.
([s]는 [sos], [bos], [Go] 등 많은 이름으로 불림)
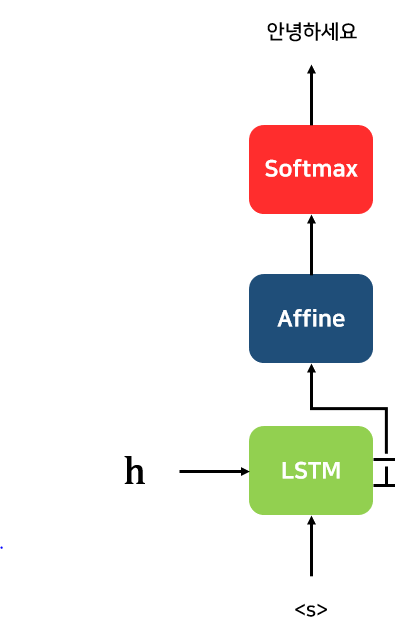
Decoder의 첫번째 RNN 셀은 h (Context Vector)와 <s> 이 2개의 입력을 바탕으로 새로운 Hidden State를 계산하고 이를 Affine 계층과 Softmax 계층을 거쳐서 다음에 등장할 확률이 높은 "안녕하세요"를 예측합니다.
(Affine 계층 : Hidden State를 입력으로 받아 분류 개수로 출력해주는 피드포워드 네트워크)
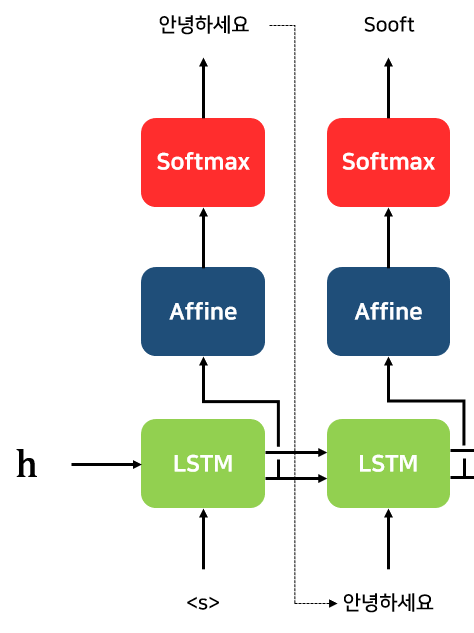
새로운 Hidden State와 예측한 "안녕하세요"를 입력으로 해서 2번째 예측을 수행합니다.
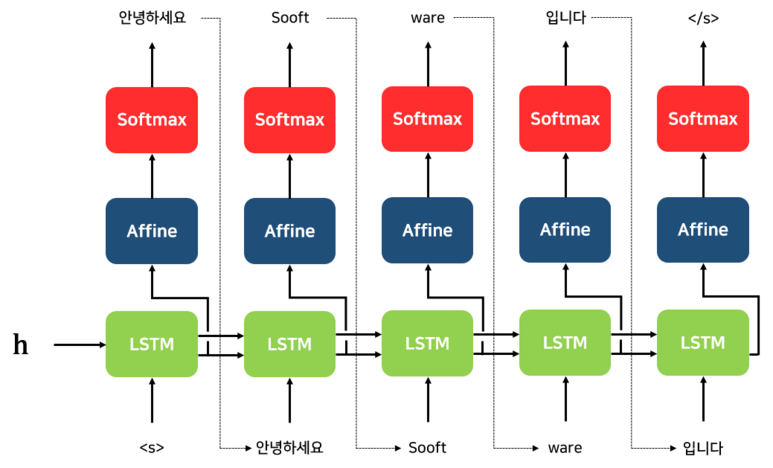
위의 과정을 문장의 끝을 의미하는 심볼인 [/s] 가 다음 단어로 예측될 때까지 반복한다.
([/s]는 [eos], [end] 등 많은 이름으로 불림)
Seqseq의 전체 모습
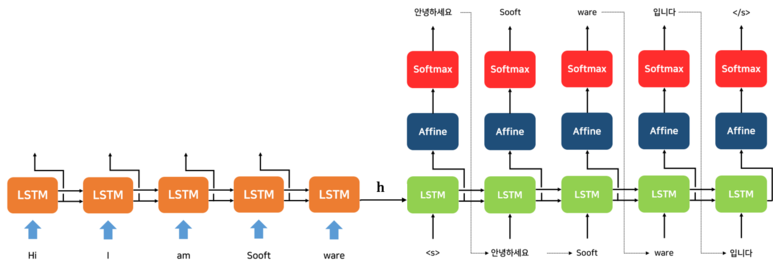
위는 Encoder와 Decoder를 연결한 Seq2seq의 전체 그림입니다.
위의 그림에서 볼 수 있듯이, Encoder의 마지막 Hidden State가 Encoder와 Decoder의 순전파와 역전파를 이어주는 다리가 됩니다.
Seq2seq 개선
앞에서 본 기본적인 Seq2seq 구조를 조금 개선하는 효과적인 기법이 몇 가지 존재하는데 그 중 2가지를 살펴봅시다.
1. 순서 반전
아주 손 쉬운 방법으로 위 그림에서 보듯이 입력 데이터의 순서를 반전시키는 것입니다.
위의 트릭은 「“Sequence to sequence learning with neural networks.” Advances in neural information processing system. 2014.」 논문에서 제안했습니다.
이 트릭을 사용하면 많은 경우 학습이 빨라져서, 최종 정확도도 좋아진다고 합니다.
그렇다면 왜 입력 데이터를 반전시키는 것만으로 학습이 빨라지고 정확도가 향상되는 걸까요?
직관적으로는 Gradient의 전파가 원활해지기 때문이라고 볼 수 있습니다.

“나”라는 단어가 “I”까지 가는 것보다 데이터를 반전시켰을 때 Gradient 전파가 잘 될 것입니다.
물론 평균적인 거리는 그대로이지만,
시계열 데이터는 관련 문제에서는 앞쪽 데이터에 대한 정확한 예측이 선행되면
뒤의 예측에서도 좋은 결과로 이어지는 경우가 많기 때문에 더 좋은 결과가 나오지 않을까 싶습니다.
매우 간단한 트릭이기 때문에 한 번 시도해보는 것을 추천합니다.
2. Peaky Seq2seq
앞서 배운 Seq2seq의 동작을 다시 한 번 살펴보게 되면,
Encoder는 입력 데이터를 고정 길이의 컨텍스트 벡터로 변환합니다.
Decoder 입장에서는 이 컨텍스트 벡터만이 예측을 하는데에 제공되는 유일한 정보인 셈입니다.
그러나 이 중요한 정보를 기본 Seq2seq에서는 최초 RNN 셀에만 전달이 됩니다.
이러한 점을 수정해서 중요한 정보가 담긴 컨텍스트 벡터를
디코더의 다른 계층들에게도 전달해주는 것입니다.
이러한 아이디어는 「”learning phrase representation using RNN encoder-decoder for statistical machine translation” Cho, Kyunhyun 2014.」 논문에서 제안되었습니다.
Peeky Seq2seq는 기본 Seq2seq에 비해 꽤나 더 좋은 성능을 보인다고 알려져있습니다.
하지만 Peeky Seq2seq는 기본 Seq2seq에 비해 파라미터가 더 늘어나기 때문에 계산량 역시 늘어나게 됩니다.
그리고 Seq2seq의 정확도는 하이퍼파라미터에 영향을 크게 받으므로,
실제 문제에서는 어떤 성능을 낼지 미지수입니다.
다양한 Seq2seq
[중간에 Fully-Connected Layer를 둔 Seq2seq]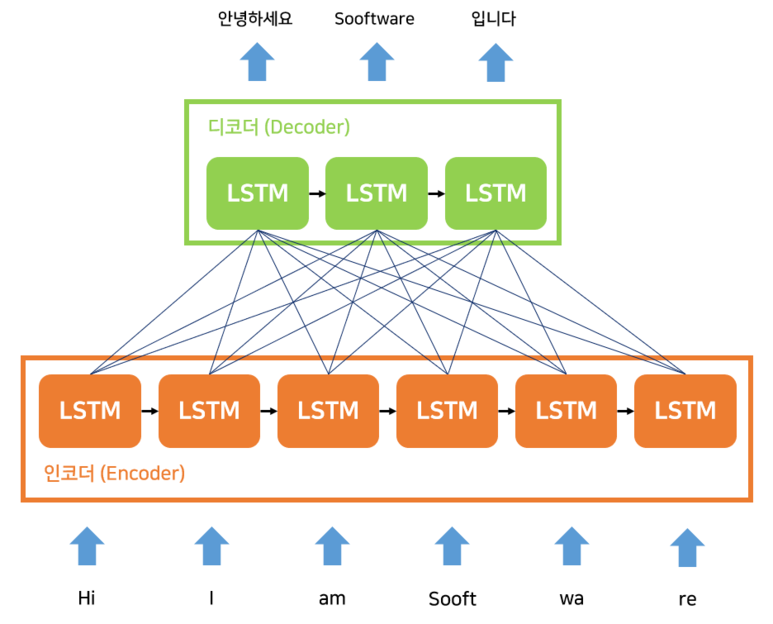
단순히 마지막 RNN 셀의 Hidden State만을 넘겨주는 방법이 아닌,
Encoder와 Decoder 사이에 Fully-Connected Layer를 둔 모델도 있으며
[Encoder의 출력을 Decoder의 입력에 추가하는 Seq2seq]
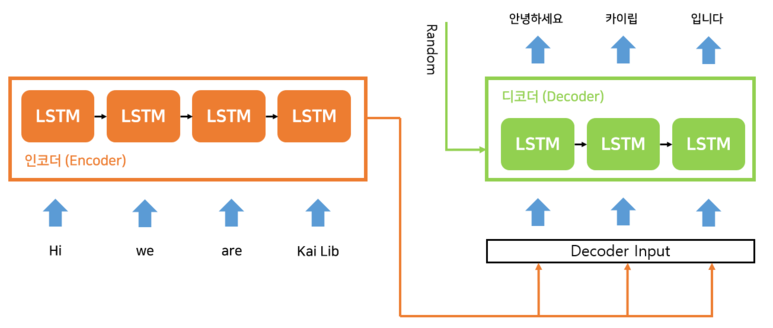
인코더가 만든 Context Vector를 모든 디코더의 입력에 concatenate하는 방식의 모델도 있습니다.
Seq2seq의 한계
하지만 이러한 기본적인 Seq2seq에는 한계점이 존재합니다.
입력 데이터가 길어지게 되면 성능이 확연하게 떨어진다는 것입니다.
이러한 Seq2seq의 한계를 극복하기 위해 제안된 Attention Mechanism이 있습니다.
개인 공부 기록용 블로그입니다.
틀린 부분이 있을 수 있습니다. :)
정말 좋은 정보 감사합니다!