LangChain Agent - 4. Middleware편
LangChain Agent

Intro
Langchain, Langgraph의 Agent는 기본적으로 매우 단순한 구조입니다.
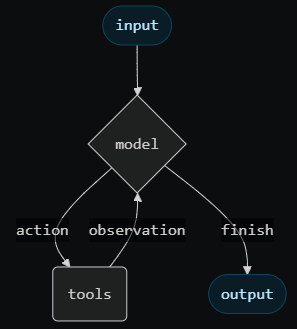
따라서 실제로 MCP tool을 붙여서 사용하려고 하면 에이전트 제어가 매우 어렵고, 제어를 위해 system prompt의 Instruction을 너무 길게 쓰게 되어 context window가 부족해지는 문제가 발생합니다.
이번 포스팅에서는 LangChain Agent에서 Context Engineering을 더욱 적극적으로 수행하고, 성능 좋은 로직은 재활용까지 할 수 있는 Middleware에 대해 소개합니다.
특히, LangChain Academy 강의에서 다루지 않은 다양한 pre-built Middleware 이외에도, 직접 원하는 Custom Middleware를 생성하는 방법 등을 구체적으로 소개합니다.
이미지 출처: LangChain 공식 Docs
1. Middleware란?
Middleware는 에이전트의 세부적인 제어권을 개발자들에게 부여하는 context engineering 도구입니다. Middleware는 Agent의 노드에 포함된 개념이 아니고, 에이전트 루프를 그래프 외부로 인터셉트해서 모델 호출의 전, 중, 후에 원하는 동작/기능을 부여합니다.
기본적으로 라이브러리 내에 pre-built middleware가 포함되어 있기 때문에, 간단한 구현에서는 이를 활용해보시는 방법도 좋을 것 같습니다.
개인적으로 프로덕션 레벨의 에이전트에는 아래 Middleware들은 설정해주시는 것이 좋다고 생각합니다.
SummarizationMiddleware: 토큰 관리HumanInTheLoopMiddleware: 위험 작업 승인 (HITL)ModelCallLimitMiddleware: 비용/무한루프 방지PIIMiddleware: 개인정보 보호
Middleware 커스텀은 기본적으로 데코레이터를 활용하여 간단히 구현할 수 있으며, 조금 더 구체적이고 세부적으로 구현하기 위해서는 Class를 직접 구현하여 적용할 수 있습니다.
2. Agent Flow와 Middleware
2.1. Middleware (데코레이터) 위치
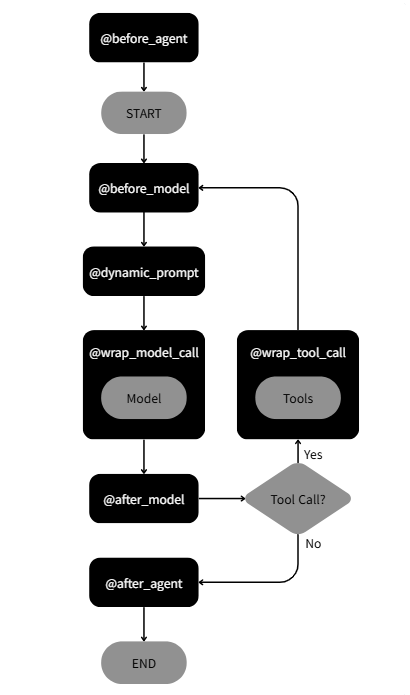
2.2. 데코레이터별 실행 횟수
| 데코레이터 | 실행 횟수 | 위치 |
|---|---|---|
| @before_agent | 1회 | 에이전트 시작 직후 |
| @before_model | N회 (매 루프) | LLM 호출 직전 |
| @dynamic_prompt | N회 (매 루프) | LLM 호출 직전 |
| @wrap_model_call | N회 (매 루프) | LLM 호출을 감싸서 |
| @after_model | N회 (매 루프) | LLM 응답 직후 |
| @wrap_tool_call | M회 (도구당) | 도구 실행을 감싸서 |
| @after_agent | 1회 | 에이전트 종료 직전 |
3. Pre-built Middleware
3.1. pre-built Middleware 종류
| 미들웨어 이름 | 주 훅 타입 | 설명 |
|---|---|---|
| SummarizationMiddleware | before/after_model/agent, wrap_model/tool_call | 토큰 제한에 근접하면 컨텍스트를 요약하여 상태를 유지함. 모델 호출 전·후 및 에이전트 라이프사이클 전반에 걸쳐 훅을 구현하는 정책형 미들웨어 |
| HumanInTheLoopMiddleware | after_model, wrap_tool_call | 모델 응답 이후 사람의 승인/개입을 요구하거나 인터럽트를 발생시키며, 실제 도구 호출을 래핑하여 실행을 제어 |
| ModelCallLimitMiddleware | before_model | 모델 호출 전에 호출 횟수 제한을 검사하여 초과 시 실행을 차단 |
| ToolCallLimitMiddleware | before_model | 도구 호출 횟수를 사전에 검사하여 제한 조건을 초과하지 않도록 제어 |
| ModelFallbackMiddleware | wrap_model_call | 모델 호출 실패 시 fallback 모델로 자동 재시도하도록 모델 호출을 래핑 |
| PIIMiddleware | before_model, after_model | 민감정보(PII)를 모델 호출 전 마스킹하거나, 응답 후 재검사 및 제거 |
| TodoListMiddleware | before_model | 복합 작업을 단계별 Todo 형태로 관리·추적하며, 주로 모델 호출 전 상태를 수정 |
| LLMToolSelectorMiddleware | before_model, wrap_model_call | 사용 가능한 도구 후보를 사전에 정리하거나, 선택 결과에 따라 모델 요청을 재구성 |
| ToolRetryMiddleware | wrap_tool_call | 도구 실행 실패 시 자동 재시도를 수행하도록 도구 호출을 래핑 |
| ModelRetryMiddleware | wrap_model_call | 모델 호출 실패 시 자동 재시도를 수행하도록 모델 호출을 래핑 |
| LLMToolEmulatorMiddleware | wrap_tool_call | 실제 도구 대신 LLM이 도구처럼 동작하도록 시뮬레이션 |
| ContextEditingMiddleware | before_model | 모델 호출 전에 컨텍스트를 편집·삭제하여 입력 상태를 정제 |
| ShellToolMiddleware | wrap_tool_call | Shell 명령 실행 도구를 안전하게 감싸 실행 |
| FilesystemFileSearchMiddleware | wrap_tool_call | 파일 시스템 기반 검색 도구 호출을 래핑하여 실행 |
3.2. Middleware 중복 등록 시 실행 순서
같은 훅을 가지는 데코레이터를 여러 개 설정했을 때 실행 순서는 어떻게 될까요?
대부분 데코레이터의 동작이 다르기 때문에 순서에 크게 영향을 받지는 않지만, 등록한 순서에 따라 아래와 같이 실행됩니다.
만약 Custom Middleware에서 중복된 state를 다루는 등의 작업을 수행할 때 참고하시면 좋을 것 같습니다.
- before_* 훅: 먼저 등록한 미들웨어부터 실행
[M1, M2, M3]등록 :M1 -> M2 -> M3 - after_* 훅: 마지막에 등록된 미들웨어부터 실행
[M1, M2, M3]등록 :M3 -> M2 -> M1 - wrap_* 훅: 먼저 등록한 미들웨어가 가장 바깥에서 실행
[M1, M2, M3]등록 :M1 -> M2 -> M3 -> (Model/Tool) -> M3 -> M2 -> M1
4. Custom Middleware 구현 (decorator)
4.1. Node-style
Node-style Middleware는 langgraph node와 같이 특정 시점에 실행되는 middleware입니다.
state, runtime argument를 활용하며, state_schema를 사용할 수 있습니다. (state에 새 필드 추가, state_schema는 해당 invoke 루프에서만 유효)
주요 활용
@before_agent: 초기화, 세션 설정@before_model: 검증, 로깅, 상태 수정@after_model: 응답 검증, 변환@after_agent: 정리, 분석 저장
state 활용 예시
@before_model
def check_before_llm(state, runtime):
print(f"LLM에 보낼 메시지: {len(state['messages'])}개")
return Noneruntime 활용 예시
@before_agent
async def init_session(state, runtime):
# 스트리밍으로 상태 알리기
runtime.stream_writer({"type": "status", "message": "준비 중..."})
# 상태에 값 추가하고 싶으면 dict 반환
return {"user_id": "abc123"}4.2. Wrap-style
Wrap-style Middleware는 파이썬의 데코레이터처럼 실행 자체를 감싸는 middleware입니다.
request, handler argument를 활용합니다.
주요 활용
@wrap_model_call: 재시도, 폴백, 캐싱@wrap_tool_call: 모니터링, 에러 처리
request 활용 예시
@wrap_model_call
def use_cheap_model(request, handler):
from langchain_openai import ChatOpenAI
cheap = request.override(model=ChatOpenAI(model="gpt-4o-mini"))
return handler(cheap)handler 활용 예시
@wrap_tool_call
def truncate_result(request, handler):
from langchain_core.messages import ToolMessage
result = handler(request)
if len(result.content) > 1000:
return ToolMessage(
content=result.content[:1000] + "... [잘림]",
tool_call_id=result.tool_call_id
)
return result4.3. Convenience
Convenience는 동적 시스템 프롬프트를 생성하는 편의 기능 middleware입니다.
state, runtime argument를 활용합니다.
주요 활용
@dynamic-prompt: 동적 시스템 프롬프팅
예시
@dynamic_prompt
def contextual_prompt(state, runtime):
base = "당신은 친절한 AI 어시스턴트입니다."
# 시간에 따라 다른 인사
hour = datetime.now().hour
if hour < 12:
base += " 좋은 아침입니다!"
elif hour < 18:
base += " 좋은 오후입니다!"
else:
base += " 좋은 저녁입니다!"
# 사용자 정보 기반 커스터마이징
user_role = state.get("user_role", "일반")
if user_role == "개발자":
base += " 기술적인 답변을 선호합니다."
return base # 문자열 반환5. Custom Middleware 구현 (Class)
주요 활용
여러 훅 동시 사용, 설정 값(class attribute) 활용, 복잡한 로직 구현, 재사용 등
예시
from langchain.agents.middleware import AgentMiddleware
from langchain_core.messages import AIMessage
class MessageLimitMiddleware(AgentMiddleware):
"""메시지 한도 체크 + 로깅 미들웨어"""
def __init__(self, max_messages: int = 50, enable_logging: bool = True):
super().__init__()
self.max_messages = max_messages
self.enable_logging = enable_logging
def before_model(self, state, runtime):
"""메시지 한도 체크"""
count = len(state["messages"])
if count >= self.max_messages:
return {
"messages": [AIMessage(content="대화 한도 초과")],
"jump_to": "end"
}
if self.enable_logging:
print(f"[BEFORE] 메시지: {count}/{self.max_messages}")
return None
def after_model(self, state, runtime):
"""응답 로깅"""
if self.enable_logging:
last = state["messages"][-1]
print(f"[AFTER] 응답: {last.content[:50]}...")
return None
# 사용: 인스턴스 1개로 등록
agent = create_agent(
model="gpt-4o",
middleware=[MessageLimitMiddleware(max_messages=30, enable_logging=True)]
)Outro
LangChain Agent를 빌드할 때, 상황/기능에 따라 모델과 프롬프트를 동적으로 갈아끼워가며 활용할 수 있습니다.
제가 실제로 회사에서 업무를 수행할 때도, system prompt나 tool description을 고정으로 사용하면 작성해야 할 양도 많아지고 에이전트의 지능도 떨어지는 점을 많이 느꼈습니다.
따라서 다음 포스팅(5. Dynamic Agent편)에서는 Dynamic Models, Prompts, Tools에 대해 다뤄보도록 하겠습니다.
(Middleware에서 활용되는 args들에 대한 설명이나, Middleware를 조금 더 동적으로 사용하기 위한 decorator parameters에 대한 설명은 Appendix를 참고해주시면 좋을 것 같습니다.)
(can_jump_to는 꼭 읽어보시길 추천..)
Appendix
Middleware Args
state: langgraph의 각 노드에서 공유하는 장기 상태. (messages 등)runtime: 실행 중에만 존재하는 컨텍스트. (config, callback 등)request: 외부에서 들어오는 입력handler: 실제 실행 로직 (노드, 툴 호출부)
데코레이터 params
can_jump_to
Middleware의 실행 이후 루프 진행을 skip하고 원하는 노드로 jump하는 기능입니다.
파라미터를 설정하면 이름 그대로 'jump_to를 사용할 수 있게 되는것'이고, 실제 jump 로직은 return 값으로 설정해야 합니다.
@before_model(can_jump_to=["model", "end"])
def jump_middleware(state, runtime)
return {"jump_to": "end"} # 에이전트 종료
return {"jump_to": "model"} # LLM 다시 호출
return {
"messages": [AIMessage("검열됨")],
"jump_to": "end"
}
return {
"jump_to": "tools",
"messages": [AIMessage(tool_calls=[...])]
}state_schema
Middleware 전용 커스텀 상태입니다. 여러 Middleware의 state_schema는 자동으로 병합됩니다.
class PlanningState(AgentState):
todo_list: list[str]
current_step: int
@before_model(state_schema=PlanningState)
def planning_middleware(state: PlanningState, runtime):
# 이 미들웨어는 todo_list, current_step이 필요함
todos = state.get("todo_list", [])
step = state.get("current_step", 0)
...tools
Middleware 전용 도구입니다. 여러 Middleware의 tools는 자동으로 병합됩니다.
@tool
def special_tool(query: str) -> str:
"""특별한 도구"""
return f"결과: {query}"
# 이 미들웨어가 도구를 추가함
@before_model(tools=[special_tool])
def add_tool_middleware(state, runtime):
# special_tool이 자동으로 에이전트에 추가됨
return None