
| 구분 | 내용 |
|---|---|
| 제목 | LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS |
| 저자 | Edward Hu 외 7인 (Microsoft Corporation) |
| 학회 | International Conference on Learning Representations (ICLR, 2022) |
| 연도 | 2022 |
| 주제 | 대규모 언어 모델의 효율적인 미세 조정 |
| 소재 | Low-Rank Adaptation (LoRA), Low-Rank Decomposition |
1. 개요
1.1. 배경
자연어 처리 분야에서 대규모 pre-trained 모델을 특정 작업이나 도메인에 적용하는 것은 중요한 패러다임이다. 그러나 전체 모델을 재학습시키는 full fine-tuning은 학습과 저장 등 모든 면에서 현실적으로 실행하기 어렵다. (task마다 실행하려면 개인 연구/개발자에겐 불가능한 수준)
1.2. 문제 정의 및 목표
본 논문은 LLM의 fine-tuning을 효율적으로 수행하는 것을 목표로 한다. 저자들은 가중치 업데이트가 낮은 "내재적 랭크(intrinsic rank)"를 가질 것이라는 가설을 세우고, LoRA(Low-Rank Adaptation)를 제안한다.
LoRA는 사전 학습된 모델의 가중치를 고정한 채, 각 트랜스포머 레이어에 학습 가능한 랭크 분해 행렬을 주입함으로써, 학습 가능한 매개변수의 수를 획기적으로 줄인다.
1.3. 효과
LoRA는 기존의 미세 조정 방식에 비해 뛰어난 효율성을 보여준다.
- GPT-3 175B 모델에 적용했을 때, 학습 가능한 매개변수의 수를 10,000배 이상, GPU 메모리 요구량을 3배까지 줄일 수 있었다.
- 동시에 RoBERTa, DeBERTa, GPT-2, GPT-3 모델에서 모델 품질 면에서 미세 조정과 동등하거나 더 나은 성능을 달성하였다.
- 특히 LoRA는 어댑터 기반 방법과 달리 추가적인 추론 지연 시간을 유발하지 않으며, 학습 처리량도 더 높다. 또한, GPT-3 175B 모델에서 미세 조정 대비 학습 속도를 25% 향상시켰다.
2. Method
2.1. PROBLEM STATEMENT
pre-trained LLM을 라고 할 때, 모델의 파라미터는 이다. full fine-tuning 시, 모델은 로 업데이트된다.
이 방식은 의 차원이 와 동일한 새로운 매개변수 집합을 학습해야 한다는 점이다. (Large Language Model이기 때문에 parameter가 매우 많다.) 따라서 저자들은 를 훨씬 작은 크기의 로 인코딩하는 방식을 제안한다. 이에 따라 새로운 최적화 식은 다음과 같이 정의된다:
2.2. LOW-RANK-PARAMETRIZED UPDATE MATRICES
아래 architecture를 보면 쉽게 이해할 수 있다. 모델 학습 시 더해지는 를 Encoder-Decoder 구조처럼 생긴 로 대체하겠다는 아이디어다.
전체 output이 기존 LLM path (좌측)과 LoRA path (우측)을 합쳐 추출되는 방식이다.
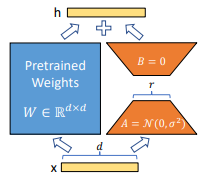
, 라고 할 때, 모델 학습을 로 표현할 수 있고, 이 때의 랭크 은 나 보다 훨씬 작은 수이다.
학습 중에는 를 고정하고, 와 만 학습한다. 수정된 forward-propagation은 다음과 같다.
는 랜덤 가우시안 분포로 초기화하고, 는 0으로 초기화하여 학습 시작 시 가 0이 되도록 한다. 또한 는 로 스케일링하는데, 이를 통해 을 변경할 때 하이퍼파라미터를 재조정할 필요성을 줄인다.
배포 시에는 를 계산해 저장할 수 있기 때문에, full fine-tuning 모델보다 추론 시간이 지연되지 않는다.
2.3. APPLYING LORA TO TRANSFORMER
원칙적으로 LoRA는 신경망의 모든 Dense 레이어에 적용할 수 있다. 이 논문에서는 특히 트랜스포머 아키텍처의 self-attention 모듈에 있는 네 개의 가중치 행렬()에 적용했다.
이를 통해 모델 학습 중 VRAM 사용량과 체크포인트 크기 등을 매우 크게 줄일 수 있다. 이는 적은 수의 GPU로도 학습이 가능하게 하며 I/O 병목 현상을 피할 수 있게 한다.
또한, LoRA 가중치만 교체하면 되므로 배포된 환경에서 작업 전환 비용을 크게 낮출 수 있다. 하지만, 서로 다른 작업을 위한 입력 배치를 단일 순방향(forward) 패스에서 처리하기 어려운 제한점도 존재한다.
3. Additionals
3.1. 기존엔 어떤 방식이 사용되었는가?
- Adapter-based Method
: Transformer의 feed-forward network들 사이에 Adpater라는 작은 NeuralNetwork를 추가하는 방식. LoRA와 마찬가지로 기존 weight는 학습하지 않지만, Adapter들은 순차적으로 학습되어야 하고, Adapter는 LoRA처럼 저차원이 아니기 때문에 계산량이 많다. - Prefix-based Method
: 모델의 input sequence 앞에 Prefix라고 부르는 학습 가능한 virtual tokens를 추가하여 fine-tuning하는 방식. 모델의 input sequence에 가상 토큰이 포함되므로, 실제 사용자 입력에 할당할 수 있는 공간이 줄어들게 된다는 단점이 있다.
각 Method의 대표적인 논문
- Adapter-based Method: Parameter-Efficient Transfer Learning for NLP
- Prefix-based Method: Prefix-Tuning: Optimizing Continuous Prompts for Generation
3.2. 결국 Weight에 같은 차원의 vector를 더해주는 방식이면, LoRA parameter를 왜 Encoder-Decoder 형태의 구조로 설정했는가? (단순 Linear Layer면 안되나?)
- Linear Layer 사용: 만약 차원의 선형 레이어 하나로 구현한다면, 이 레이어의 학습 파라미터 수는 . (full fine-tuning과 동일한 수의 파라미터)
- LoRA의 Encoder-Decoder 구조 (BA) 사용: 와 두 개 행렬의 총 파라미터 수는 로, 에 비해 훨씬 적음.
3.3. LoRA parameter 를 어디에 더해준다는 것인가?

실험을 통해 에 다양하게 적용해본 결과, Query와 Key Weight ()에 적용해주었을 때가 가장 효과가 좋았다고 한다.
