[논문 리뷰] Safe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models
논문 리뷰

| 구분 | 내용 |
|---|---|
| 제목 | Safe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models |
| 저자 | Chia-Yi Hsu, Yu-Lin Tsai, Chih-Hsun Lin, Chia-Mu Yu, Pin-Yu Chen, Chun-Ying Huang |
| 학회 | NeurIPS |
| 연도 | 2024 |
| 주제 | LLM fine-tuning 시 발생하는 안전 문제 완화 |
| 소재 | Safe LoRA, LoRA, Alignment Matrix, Post-hoc Projection |
이번 논문은 선형대수를 기반으로 이론적인 설명이 필요한 부분이 많다.
이러한 내용은 '3.Additionals'에 기재했으니, 자세한 설명은 해당 내용을 참고하기 바란다.
1. 개요
1.1. 배경
LLMs을 특정 데이터셋이나 도메인에 맞게 fine-tuning할 때, full fine-tuning은 막대한 자원을 요구하기 때문에 LoRA와 같은 효율적인 파라미터 미세 조정(PEFT) 기술이 등장했다.
LoRA는 전체 파라미터 미세 조정과 유사한 성능을 달성하면서도 자원 소모를 크게 줄일 수 있지만, 최근 악의적인 콘텐츠가 없는 데이터로 fine-tuning을 진행하더라도 LLM의 안전성을 약화시킬 수 있음이 발견되었다.
1.2. 문제 정의 및 목표
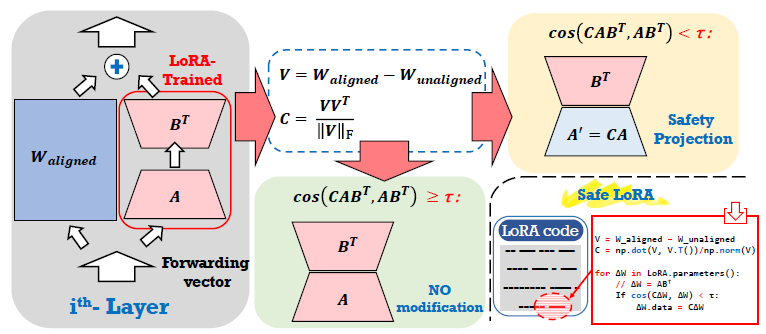
본 논문은 LLM fine-tuning 시 Safety Guardrail이 손실되는 문제를 해결하고자 한다. 연구진은 기존 LoRA 구현에 간단한 'one-liner patch'를 추가하는 Safe LoRA를 제안한다.
이는 선택된 레이어의 LoRA 가중치를 safety-aligned subspace으로 투영하여, LLM fine-tuning 과정에서 발생하는 안전 위험을 효과적으로 줄이면서도 유틸리티를 유지하는 것을 목표로 한다.
Safe LoRA는 기본 모델과 정렬된 모델의 가중치 정보만을 필요로 하는 'training-free & data-free' 접근법이다.
1.3. 효과
- Safe LoRA는 순수하게 악의적인 데이터로 fine-tuning할 경우에도 원래의 정렬된 모델과 유사한 안전 성능을 유지하는 효과를 보였다.
- 양성 및 악성 데이터가 혼합된 데이터셋으로 fine-tuning할 때에도 악성 데이터가 초래하는 부정적 영향을 완화하면서 다운스트림 작업 성능을 보존했다.
- 특히 Llama-2-7B-Chat 모델에 대한 실험에서, Safe LoRA는 기존의 LoRA 미세 조정으로 인해 4.66까지 상승했던 Harmfulness Score를 1.055로 크게 낮추는 동시에, MT-Bench 유틸리티 점수를 6.34로 유지하여 다른 방어 방법론들(SafeInstr, BEA)을 능가하는 성능을 보였다.
2. Method
본 논문에서는 모델의 weight vector로 표현할 수 있는 vector space인 'weight space(모델 가중치 공간)'이라는 개념을 이용한다.
저자들은 정렬된 모델(aligned)과 정렬되지 않은 모델(unaligned)의 가중치 차이 vector로 표현할 수 있는 vector space에 Weight를 projection시키면 모델의 정렬성이 높아진다는 아이디어를 제안했다.
(여기서 aligned는 '친절하게 답변'하라거나 '위험한 표현을 자제'하라는 등의 지시를 학습했다는 의미)
2.1. Constructing Alignment Matrix
정렬된 모델()과 정렬되지 않은 모델()의 가중치 차이로 alignment matrix 를 계산한다.
여기서 와 는 각각 i번째 레이어의 정렬된 모델과 정렬되지 않은 모델의 가중치를 나타낸다.
저자들은 이 정렬 행렬이 base 모델을 대화형 챗봇으로 훈련시키는 과정에 포함된 명령어 튜닝과 safety에 관련된 alignment를 내포하고 있다고 본다. (쉽게 말해 는 aligned model weight과 unaligned model weight의 차이이므로, aligned 모델에서의 alignment를 담당하는 영역이라는 의미)
alignment matrix에 Weight를 projection 시키기 위해, projection matrix 를 다음 공식에 따라 각 레이어에 대해 생성한다.
이 식을 Weight에 곱하면 Weight를 에 projection하는 것과 동일하게 된다.
2.2. Post-hoc Fine-tuning Projection
이후 alignment matrix 로 LoRA 가중치 를 projection한다.
이때, 모든 LoRA 가중치를 투영하는 대신, 원래의 LoRA 가중치 와 projection된 가중치 의 코사인 유사도가 일정 threshold() 보다 작은 레이어만 projection을 진행한다.
(LoRA Weight와 alignment matrix로 projection된 LoRA Weight가 유사하지 않다는 것은 LoRA fine-tuning 과정에서 alignment가 깨졌다는 의미)
이 과정은 다음 공식으로 표현된다.
여기서 는 Frobenius 내적을, 는 Frobenius norm을 나타낸다.
일부 Weight만 projection하는 이유?
1. projection 전/후가 유사한 Weight는 alignment가 깨지지 않았기 때문에 굳이 projection을 할 필요가 없다. 불필요한 computation을 줄이기 위함
2. alignment와 utility는 trade-off 관계. alignment를 깨트리지 않는 경우에는 관여하지 않음으로써 fine-tuning의 원래 목적인 utility 성능을 최대한 보존하기 위함
2.3. Rationale for Post-Hoc Projection
Post-hoc projection의 근거(가정)는 다음과 같다.
- 저자들은 가중치 공간이 잘 구조화되어 있으며, 를 에서 빼면 안전 관련 벡터()를 추출할 수 있다.
- 이 벡터를 사용하여 투영 행렬 를 구성하면, 원래의 벡터 공간 내에 안전 관련 개념을 나타내는 부분 공간을 생성할 수 있다.
- 안전 개념 공간을 벗어난 LoRA fine-tuned Weight만 projection하여 유틸리티와 안전성을 동시에 증진시킬 수 있다.
2.4. A Faster Alternative
기존의 투영 방법은 각 레이어에서 역행렬 연산을 포함하기 때문에 시간이 많이 소요된다. 이를 개선하기 위해 논문은 다음과 같은 근사 투영 행렬()을 제안하였다.
이 근사 방식은 기존 방식보다 투영 행렬 생성 속도가 250배 이상 빠르며, 실험 결과 유해성 점수와 유틸리티 측면에서 원래의 방법과 유사하거나 때로는 더 나은 성능을 보여주었다. 이는 자원 효율성과 성능의 균형을 잘 맞춘 실용적인 대안으로 제시된다.
전체적인 Architecture는 아래 그림과 같다. LoRA weight가 projection된 weight와 유사도가 보다 작으면 LoRA로 alignment가 깨졌다는 의미이므로 projection한 weight 사용, 그렇지 않으면 pass.
3. Additionals
3.1. projection matrix 의 의미
(이거 나중에 추가하자.)
3.2. Faster Alternative의 근거
LoRA의 학습 파라미터 를 orthonormal 또는 매우 작은 값으로 설정한 뒤, 작은 gradient step으로 학습하기 때문에 alignment matrix 도 orthonormal과 유사할 것이라는 가정이 들어간 것 같다.
- 가 orthonormal일 경우, 이므로, 로 생략하여 를 로 대체할 수 있다.
- 경험적/실험적으로 대체해도 성능이 유사하다.
3.3. Safe LoRA의 실용성
대부분의 오픈소스 LLM(Llama, Mistral 등)은 base 모델과 chat/instruct 모델을 함께 공개한다. Safe LoRA는 이 두 모델을 바로 사용해서 alignment matrix를 구성할 수 있다.
따라서 사용자 입장에서 별도의 alignment 학습 과정 필요 없기 때문에 “plug-and-play 안전 보강”, "training-free", "data-free"라고 표현할 수 있다.
