① 오늘 배운 개념 / 주제
- 데이터 전처리
- 결측치
- 인코딩
- 스케일링
- 이상치
② 핵심 내용 요약 (내 언어로)
결측치 처리
- 결측치 제거 - dropna() 함수 사용
print(df.isnull().sum()) #결측치 확인
df_dropped = df.dropna() #결측치 포함 행 제거
df_droped_age = df.dropna(subset=['나이']) #특정 칼럼에 빈칸 제거- 결측치 대체 : 평균값 or 중앙값 or 최빈값 중 적절한 것으로 대체 - fillna() 함수 사용
범주형 데이터 인코딩
-
라벨 인코딩 : 카테고리마다 고유한 숫자 부여, 숫자의 크기를 가치나 순위로 오해할 가능성 있음
-
원-핫 인코딩 : 카테고리 종류만큼 컬럼을 만들고 해당하는 컬럼에는 1, 나머지는 모두 0을 채우는 방식, 카테고리 종류가 많으면 너무 커짐
df_encoded = pd.get_dummies(df, columns=['성별', '탑승항구'], dtype=int)스케일링
- Min-Max Scaler : 0부터 1사이의 소수점으로 모든 값을 맞춰줌, 원래 분포 모양 유지 가능
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)- Standard Scaler : 데이터의 평균을 0으로, 표준편차를 1로 변환, 이상치 영향을 덜 받음
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)test data 스케일링 시에는 scaler.transform(X_test) 사용
이상치 처리
- 이상치 확인 : boxplot을 통해 튀는 값 눈으로 확인
- 이상치 처리 : IQR을 통해 처리하기 (제3 사분위수 - 제1 사분위수)
③ 실습 / 과제 결과물
실습 결과물 링크
타이타닉 데이터를 이용해 데이터 전처리 후 모델학습 결과 확인
- 결측치 처리 : 결측치 현황을 확인한 뒤, age는 중앙값으로, Embarked는 최빈값으로, Cabin은 컬름을 삭제하는 방식으로 결측치를 처리했다.
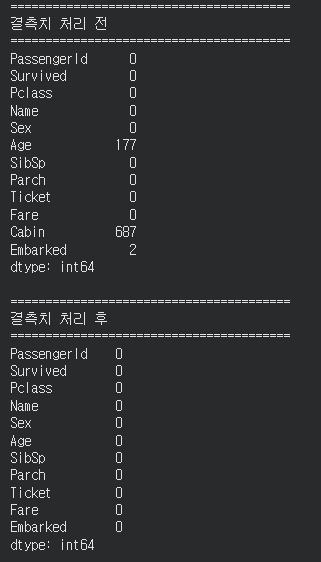
-
이상치 처리 : 박스플롯으로 이상치를 확인한 뒤, IQR을 구하여 이상치를 제거하였다.
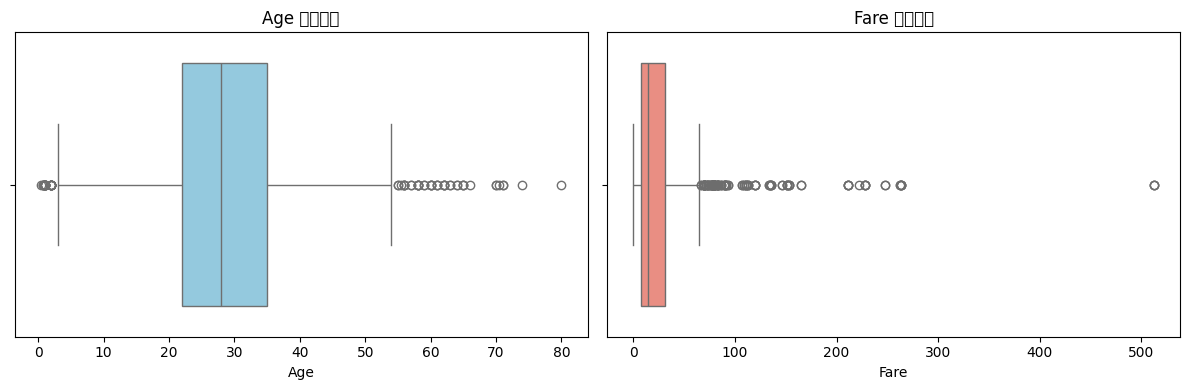
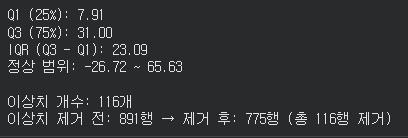
-
인코딩 : 성별(Sex)는 두가지 범주형 변수이므로 라벨인코딩을 진행하였고, Embarked 변수는 범주가 3가지 이기 때문에 원-핫 인코딩을 진행했다.

-
스케일링 : standardscaler를 진행하였다.

- 모델 학습 & 예측 : 불필요 칼럼 제거하고 x와 y를 분리하고 학습용과 테스트 데이터도 분리한다. 그 후 랜덤 포레스트 모델을 사용하여 예측을 수행한다.

- 전처리 유무에 따른 정확도 차이 비교
④ 느낀 점 / 배운 점 / 다음 목표
- 데이터 전처리를 깔끔하고 정석적으로 수행하는 방법을 이해하게 되었다.
- 다양한 전처리 기법과 관련 패키지를 상황에 맞게 선택하는 기준을 알게 되었다.
- 전처리가 모델 전체 정확도의 정말 많은 부분을 결정한다는 것을 알고는 있었지만 정확히 얼마의 차이가 나는지 실습에서 눈으로 확인할 수 있어 좋았다.
- 프로젝트 당시에 깔끔하지 못한 코드를 사용해서 전처리를 했었는데, 이 방법을 사용해서 새로운 공모전에서 발전된 성적을 얻고 싶다.
