딥러닝
딥러닝은 인공신경망을 여러 층으로 쌓아 데이터를 학습하는 방법이다.
입력 데이터를 받아 예측값을 만들고, 그 예측이 실제 정답과 얼마나 차이가 나는지 확인한 뒤 오차를 줄이는 방향으로 반복 학습한다.
머신러닝이 사람이 특징을 어느 정도 직접 정리해주는 방식이라면, 딥러닝은 데이터 안의 중요한 패턴을 모델이 스스로 학습한다는 점이 특징이다.
이미지, 텍스트, 음성처럼 복잡한 데이터를 다룰 때 특히 유용하게 활용된다.
파이토치(PyTorch)
파이토치는 딥러닝 모델을 만들고 학습할 때 사용하는 대표적인 라이브러리다.
모델 구조를 정의하고, 데이터를 불러오고, 손실을 계산하고, 가중치를 업데이트하는 과정을 비교적 직관적으로 구현할 수 있다.
특히 텐서 연산, 데이터 로딩, 손실 계산, 파라미터 업데이트를 하나의 흐름으로 연결해서 다룰 수 있다는 점이 핵심이다.
텐서(Tensor)
딥러닝 모델은 이미지나 문장을 그대로 이해하지 못하고, 결국 숫자로 이루어진 다차원 배열 형태의 데이터를 입력받는다.
이때 사용하는 기본 단위가 바로 텐서이다.
0차원은 스칼라, 1차원은 벡터, 2차원은 행렬이며, 3차원 이상은 고차원 텐서라고 볼 수 있다.
스칼라, 벡터, 행렬, 고차원 텐서 모두 텐서의 종류이다.
예를 들어 이미지 데이터는 보통 가로, 세로, RGB 채널 정보를 가지기 때문에 3차원 이상의 텐서로 표현된다.
MNIST 데이터셋
MNIST는 손으로 쓴 숫자 0부터 9까지의 흑백 이미지로 이루어진 대표적인 데이터셋으로, 숫자 분류 문제를 실습할 때 많이 사용된다.

구조가 비교적 단순하고, 숫자 분류라는 목표가 명확해 딥러닝 입문 실습에서 전체 학습 흐름을 익히기 좋은 예시로 자주 활용된다.
즉 MNIST를 공부할 때 중요한 것은 단순히 숫자를 맞히는 것이 아니라, 이미지 데이터를 텐서로 바꾸고, 신경망에 넣고, 학습과 평가를 반복하는 전체 과정을 연습하는 것이다.
인공신경망(Artificial Neural Network)
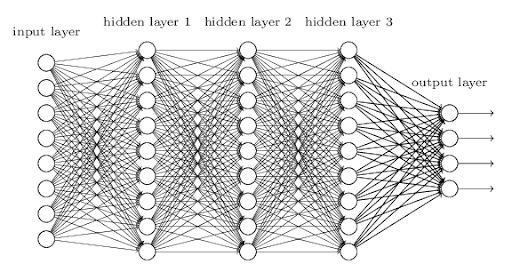
인공신경망은 인간의 뇌 신경세포인 뉴런이 신호를 주고받는 방식을 수학적으로 모방한 알고리즘이다.
데이터를 받아들이는 입력층(Input Layer), 데이터의 특징을 추출하고 학습하는 하나 이상의 은닉층(Hidden Layer), 그리고 최종 결과를 내놓는 출력층(Output Layer)으로 구성된다.
이 은닉층을 여러 층으로 깊게 쌓아 복잡한 패턴까지 학습할 수 있도록 만든 것이 딥러닝이다.
입력값이 들어오면 각 층에서 가중치와 편향을 이용해 계산이 이루어지고, 그 결과가 다음 층으로 전달된다. 이 과정을 거쳐 마지막에는 하나의 예측 결과가 만들어진다.
처음에는 가중치가 적절하지 않기 때문에 예측이 부정확하지만, 학습을 반복하면서 점점 더 정답에 가까운 방향으로 조정된다.
즉 인공신경망은 데이터를 입력받고, 계산하고, 수정하면서 점점 더 잘 맞추도록 만들어지는 구조이다.
단순한 이미지 분류부터, 자연어 처리 모델까지 다양한 분야에서 활용된다.
활성화 함수
활성화 함수는 신경망이 단순한 선형 계산만 반복하지 않도록 도와주는 요소이다.
이 함수가 있어야 모델이 복잡한 패턴을 학습할 수 있다.
대표적으로 많이 사용하는 함수는 ReLU이다.
ReLU는 입력값이 0보다 크면 그대로 두고, 0 이하이면 0으로 바꾸는 단순한 함수다.
활성화 함수가 없다면 여러 층을 쌓더라도 복잡한 문제를 학습하는 데 한계가 생기기 때문에 중요한 개념이다.
ReLU 외에도 Sigmoid, Tanh, Softmax 등 다양한 함수가 사용된다.
딥러닝 학습 과정
딥러닝 학습은 크게 네 단계로 이해할 수 있다.
순전파(Forward Propagation)
입력 데이터를 모델에 넣고 예측값을 만드는 과정이다.
예를 들어 MNIST 이미지가 들어오면, 모델은 이 이미지가 어떤 숫자인지 예측한다.
손실 함수(Loss Function)
모델의 예측값과 실제 정답 사이의 차이를 계산하는 함수이다.
예측이 틀릴수록 손실값은 커지고, 정답에 가까울수록 손실값은 작아진다.
역전파(Backpropagation)
손실값을 바탕으로 어떤 가중치를 얼마나 수정해야 하는지 계산하는 과정이다.
즉 오차를 뒤에서부터 거꾸로 전달하며 모델을 조정하는 단계이다.
옵티마이저(Optimizer)
계산된 결과를 바탕으로 실제 가중치를 업데이트하는 방법이다.
이 과정을 반복하면서 모델의 성능이 점점 좋아진다.
정리하면 딥러닝 학습은
데이터 입력 → 예측 → 오차 계산 → 가중치 수정
이 흐름을 반복하는 과정이라고 볼 수 있다.
에포크(Epoch), 배치사이즈(Batch Size), 이터레이션(Iteration)
배치사이즈(Batch Size)
: 한 번에 모델에 넣는 데이터의 개수
이터레이션(Iteration)
: 배치 하나를 사용해 한 번 학습하는 과정
에포크(Epoch)
: 전체 학습 데이터를 한 바퀴 모두 학습한 것
예를 들어 데이터가 60,000개 있고 배치사이즈가 100이면, 한 번에 100개씩 나누어 학습하므로 600번의 iteration이 모여 1 epoch가 된다.
