오늘 배운 개념 / 주제
- 딥러닝과 머신러닝의 차이
- 인공신경망 (ANN)
- 학습 파라미터: 배치 사이즈 (Batch Size), 에포크 (Epoch), 학습률 (Learning Rate)
- 학습 사이클: 순전파, 손실 계산(Loss), 역전파 (Backpropagation), 옵티마이저 (Optimizer)
- 딥러닝 모델
핵심 내용 요약 (내 언어로)
머신러닝 vs 딥러닝
머신러닝 : 사람이 특징을 직접 정해주는 방식으로 학습
딥러닝 : 많은 양의 데이터를 통해 스스로 특징을 발견하는 방식으로 학습
인공신경망 (ANN)
: 뇌의 뉴런 구조를 모방한 입력층 → 은닉층 → 출력층 구조
각 뉴런은 입력값(input) × 가중치(weight) + 편향(bias) 연산 후 활성화 함수(ReLU 등)를 거쳐 출력값을 출력한다.
최종적으로 출력값과 정답의 오차를 최소화 하는 가중치(weight)를 찾는 것이 목표이다.
활성화 함수를 통해 단순한 직선이 아닌 복잡한 비선형 패턴 학습 가능하다.
텐서 (Tensor)
:딥러닝에서 데이터를 담는 다차원 배열
PyTorch에서는 torch.Tensor 형태로 다루며, GPU형태로 연산이 가능하다는 장점이 있다.
주요 학습 설정값 (하이퍼파라미터)
Batch Size: 한 번에 모델에 넣고 학습할 데이터의 묶음 크기 (보통 32, 64, 128)
Epoch: 전체 학습 데이터를 처음부터 끝까지 반복 학습하는 횟수
Learning Rate: 가중치 업데이트 시 한 번에 이동할 보폭의 크기 (보통 0.001 시작)
학습 최적화 도구
Loss Function(손실함수): 모델의 예측값과 실제 정답의 차이를 수치화 (CrossEntropyLoss, MSELoss 등)
이 손실값을 최대로 줄이는 것이 딥러닝 학습의 목표이다.
Optimizer: 손실을 줄이는 방향으로 가중치를 업데이트하는 도구 (주로 Adam 사용)
딥러닝 모델 학습 4단계 사이클
① 순전파 (Forward Propagation)
입력 데이터를 모델에 통과시켜 1차적인 예측값 도출
② 손실 계산 (Loss Calculation)
모델의 예측값과 정답을 비교하여 오차 확인
③ 역전파 (Backpropagation)
출력층에서 입력층 방향으로 거꾸로 추적하며 어떤 가중치 때문에 틀렸는지 확인
④ 가중치 업데이트 (Weight Update)
Optimizer를 활용해 계산된 오차만큼 가중치를 수정
대표적인 딥러닝 아키텍처
CNN (Convolutional Neural Network)
필터를 이용해 이미지의 시각적 특징(선, 곡선 등) 추출
(활용 : 사진 분류, 자율주행)
RNN / LSTM
데이터의 순서와 맥락을 기억하며 흐름을 처리
(활용 : 주가 예측, 음성 인식)
Transformer
문장 전체를 조망하고 중요한 부분에 집중하는 Attention 메커니즘 사용
(활용 : ChatGPT, Claude, 번역, 이미지 생성 등 거의 모든 분야)
GAN
생성자와 판별자가 경쟁하며 진짜 같은 가짜 데이터 생성
(활용 : 얼굴 생성, 사진 스타일 변환)
AutoEncoder
데이터를 최대한 압축 후 복원하며 핵심 특징만 추출
(활용 : 노이즈 제거, 이상 탐지)
실습 / 과제 결과물
PyTorch를 활용해 MNIST 손글씨 숫자 분류 모델 구현하기
MNIST데이터 : 28*28의 흑백 손글씨 데이터
데이터 준비
ToTensor()와 Normalize()를 통해 텐서 변환과 정규화를 통해 데이터를 전처리하고, 학습용 데이터셋 60,000장과 테스트용 데이터셋 10,000장을 불러온다. 이를 batch_size = 64로 지정하여 64장씩 나누어서 학습을 하는 방식으로 진행한다.
모델 설계
입력 784개 → 은닉층 256개 → 은닉층 128개 → 출력 10개(0~9까지의 숫자 분류)
활성화 함수로는 ReLU를 사용했다.
과적합 방지 : nn.Dropout(0.2) 학습 중 뉴런의 20%를 랜덤으로 끄는 것
도구 설정
손실 함수: CrossEntropyLoss
옵티마이저: Adam (lr=0.001)
학습
에포크를 10으로 설정
순전파 → 손실 계산 → 이전 그래디언트 초기화 → 역전파 → 가중치 업데이트 순으로 진행
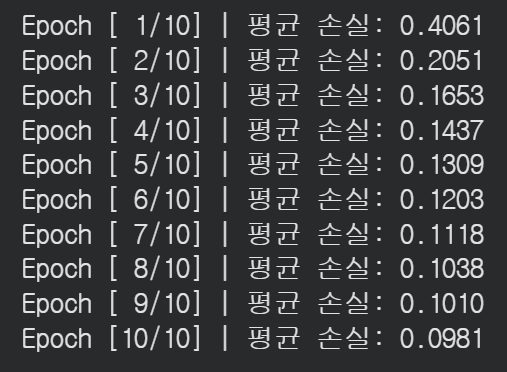
손실이 줄어드는 방향으로 학습이 잘 되고있음을 알 수 있다.
평가
테스트 데이터로 정확도 측정

(추가)
1. 학습 모델을 CNN으로 바꾸었을 때 정확도가 98.62%까지 상승하였다.
2. 학습률 (Learning Rate)를 lr = 0.01, 0.0001으로 바꾸어 보았다. 아래는 원래의 학습 곡선이다.
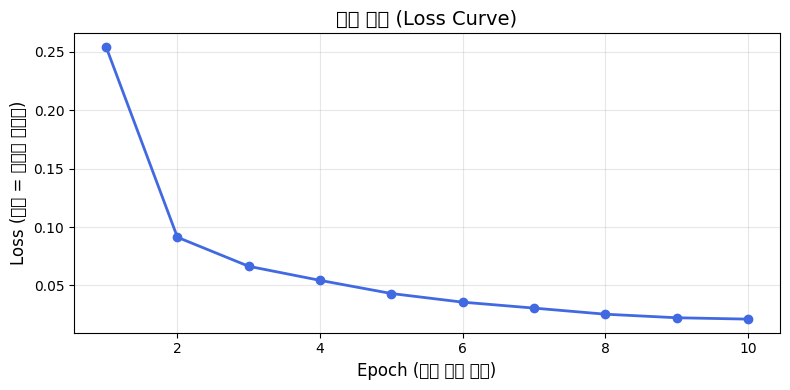
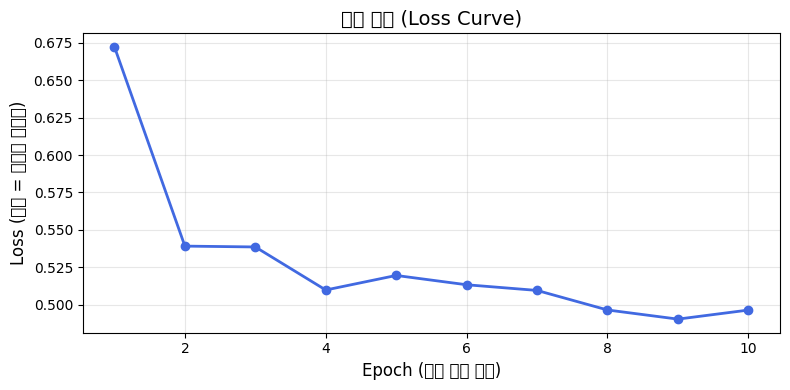
lr = 0.01일 때는 학습 곡선이 위아래로 요동치는 형태를 보이며 정확도가 92.68%로 떨어졌다.
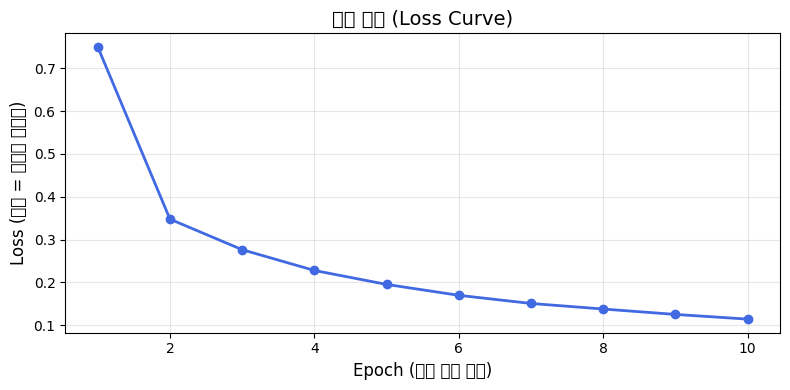
lr = 0.0001일 때는 보폭이 작아 정확도가 낮아질 것으로 예상하였지만, 정확도는 비슷하였고, optimizer를 adam을 사용했기 때문에 상쇄되었다고 생각한다.
3. 배치 사이즈 변경
배치사이즈를 16으로 바꾼 결과, 학습 시간이 길어졌다.
배치 사이즈를 256으로 바꾼 결과, 학습 시간이 줄었으며 학습 곡선도 잘 표현되었다.
4. FashionMNIST 데이터 셋으로 변경
단순히 데이터만 적용하였을 때에는 정확도가 88.23%로 낮게 나왔다.
여기에 1번의 CNN 모델을 적용하니 정확도가 90.95%가 나왔다.
이미지 데이터이기 때문에 CNN모델과 함께 사용했을 때 정확도가 훨씬 높게 나왔다.
느낀 점 / 배운 점 / 다음 목표
- 딥러닝 모델을 여러가지 공부할 필요성을 느끼게되었다. 딥러닝 모델에 대해서는 아직 잘 모르기 때문에 상황에 따른 적절한 모델을 여러가지 활용하며 공부해야겠다고 느꼈다.
- 머신러닝까지만 다뤄보고 딥러닝 모델은 안다뤄봤는데, 머신러닝 보다 훨씬 다양한 프로젝트를 진행할 수 있을 것 같아 기대된다.
- 다음엔 모델들을 더 깊고 완벽하게 공부하여 프로젝트에 활용할 수 있도록 노력할 것이다.
