데이터거리
거리행렬의 산정방법
- 거리가 무엇인지 정확히 정의해야함
- 수식으로 나타낼 수 있어야 함
가장 많이 쓰이고 기초적인 거리는?
- 유클리드 거리
- 맨하튼 거리
- 민콥스키 거리
군집분석의 3가지 종류
<계층형>
: 가장 가까운 거리의 데이터부터 차례대로 그룹을 이루어 나가면서 최종적으로 하나의 그룹으로 합치는 방식으로 트리 구조를 만드는 방법
▶ Dendrogram : 거리 행렬을 통해 데이터 포인트를 모두 계산
많은 메모리를 필요로 함
대체적으로 큰 규모의 데이터에서는 사용하기 힘듦
<비계층형>
: 계층형이 아닌 방법
▶ K-means : 데이터끼리의 평균 벡터 이용
군집의 평균을 매번 계싼하여 움직이지 않을 때까지 군집을 결정하는 방법
원 형태의 군집에 최적화
길쭉한 형태의 군집은 잘 잡아내지 못함
▶ DBSAN: 밀도가 높은 부분을 군집으로 평가
데이터의 밀집된 밀도를 기준으로 군집을 나누는 방법
노이즈를 자동으로 잡아낼 수 있음
길쭉한 형태의 군집도 잘 잡아냄
양군집
1. 최단연결법
2. 최장연결법
3. 평균연결법 군집 AB의 거리 + 군집 C의 거리
4. 중심연결법
5. 워드연결법: 2개의 군비을 합칠 때 오차제곱합의 거리가 가장 짧은 거리
공통점: 가장 짧은 거리의 군집을 결합하면서 서로 하나씩 융합시키는 것
붓꽃은 서로 비슷한 속성끼리 군집 형성
K-means 알고리즘
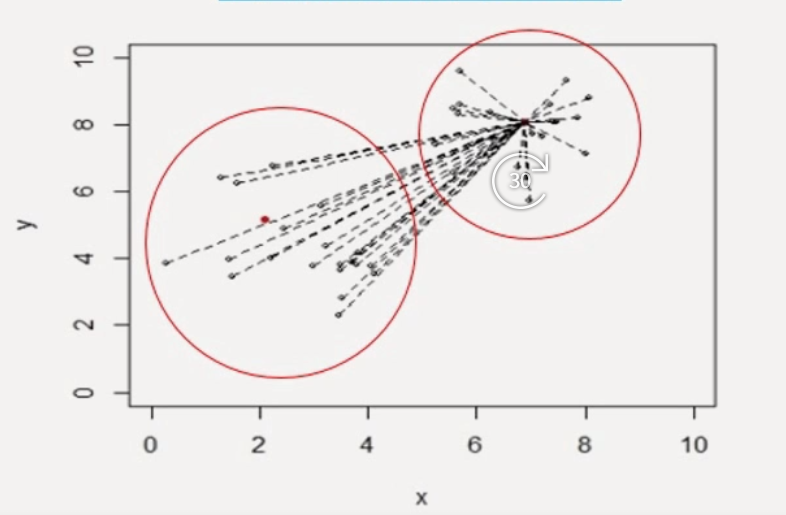
1. 임의(k개)의 학습데이터를 평균벡터로 설정
군집중심에서 모든 접과의 거리 계산
각각의 점에 해당되는 가장 가까운 군집 중심 확인
데이터마다 하나씩 군집 배정
같은 군집의 점들끼리 평균 벡터를 구함
변동된 중심과 모든 점과의 거리 계산
2. 데이터들을 k개의 벡터에 대하여 분류
3. 분류된 데이터에 대하여 평균벡터(군집중심)를 구함
4. 2번~3번 계속적으로 반복
5. k개의 평균벡터가 변함이 없을때까지 반복
