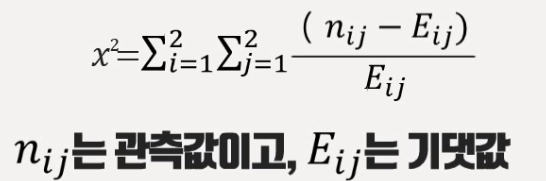
의사결정트리(Dcision Tree)
엔트로피의 이해
분류 문제의 사용
- 분류 문제를 풀기 위해 Tree 모양의 Map을 만드는 것이 효과적임
- 나무 모양을 만들어내는 알고리즘을 의사결정트리라고 함
의사결정트리를 만드는 과정
1. 엔트로피가 가장 많이 줄어드는 방법으로 데이터를 나눈다
2. 다른 속성 기준으로 다시 데이터를 나눈다
3. 엔트로피가 0이 될 때까지 나눈다.
4. leaf에 도달한다.
- 엔트로피가 0이 될때까지 계속 반복하지는 않음
줄어든 엔트로피 차이가 정보의 이득
정보이득이 최대가 되도록 가지치기를 하여 데이터를 나누어야함
데이터 분기 후 데이터 분포 바뀜-> 다시 엔트로피 계산 -> 정보 이득 가장 높은 속성 값 찾음
target 값이란 목표값
클래스 범주형 데이터에 회귀분석을 결합시켜 연속값 예측 가능
회귀분석의 개수 값을 예측하도록 결합
범주형 데이터를 예측 하는 것 의사결정트리의 가장 기본적인 역할
의사결정트리 알고리즘의 특징
1. 엔트로피를 이용함
2. 지니계수를 이용함
3. 데이터를 나누는 방법에 이용함
4. 가장 영향력이 큰 속성을 이용함
데이터의 불순도 평가 기준
엔트로피 , 지니계수, 카이제곱 스퀘어
카이제곱 스퀘어
2개 범주의 데이터를 나눌 때 상관관계가 0에 가까운지 검정하는 '독립성 검정'의 용도로 쓰임
상관관계가 가장 적도록 나누는 방법
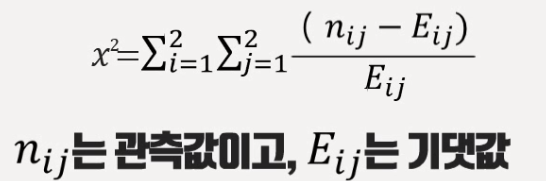
지니계수 사용시 속도를 빠르게 할 수 있음
<실습>
1. 데이터 읽어오기
2. 모델 만들기
3. 예측하기
4. 평가하기
이 과정에 계속 반복~
sklearn
tree 함수 사용하여 엔트로피를 이용해서 의사결정트리를 만드는 방법이 녹아 있음
모델평가하는 함수가 metrics
digits을 타겟과 이미지로 나눔
label 9
그림을 수치로 나타냄
(8,8)
분류 알고리즘
n_samples의 2/3을 트레인 데이터로 사용
훈련할때는 fit 함수 사용 depth
모델을 만드는 과정 - 모델을 이용하여 예측(다른데이터 사용) = trian_size 부터
실제값은 expected에 저장
실행하면 정확도 매트릭중에서 가장 간단한 방법, 정확하지는 않음
Accuracy 함수를 통해 실제 값과 예측값
-> Decision tree로 숫자를 인식할 수 있구나 정도로
혼돈행렬 confision matrix(expected, Predicted)
대각선에 숫자가 모여있을수록 좋은 모델
