형태소 분석
텍스트는 문장으로 구성되고, 문장은 단어들로 구성된다.
형태소 분석기 종류
- KoNLPy
- 꼬꼬마
- Komoran
텍스트 마이닝의 목적에 따라서 주관적으로 라이브러리를 선택한다.
TF-IDF의 의의
변수로서 역할을 하지 못하는 단어들을 제거하는 전처리 작업 필요
빈도수가 높은 단어가 중요한 단어인가?
TF는 기본적인 단어 중요도를 평가하는 스코어
TF 스코어란?
: 특정 문서에서 나오는 모든 단어의 빈도수에서 특정 단어의 빈도수가 차지하는 비율

모든 문서에서 자주 나오는 단어는 별로 중요한 단어가 아니다. 빈도수는 문서에 비례하여 증가하는 경향이 있어 좋은 척도라고는 볼 수 없다. 특별한 문서에 자주 등장하는 단어가 중요한 단어이다.
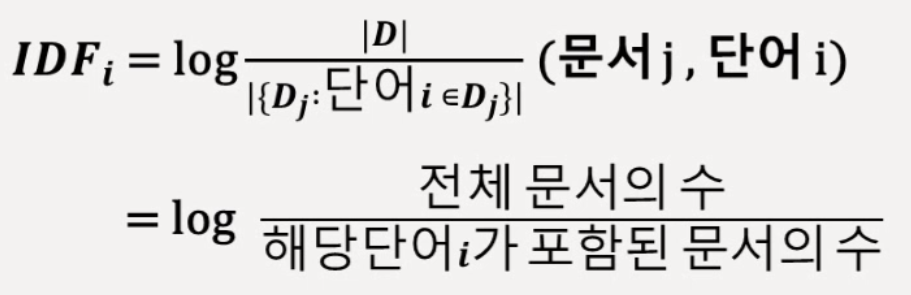
역문헌 빈도(IDF, Inverse Document Frequency)
: 전체 문서에서 특정 단어가 포함된 문서가 차지하는 비율의 역수로 표현
특별한 문서에 나타난 단어일수록 점수가 높게 나옴
역수를 취하면 공통 단어에서 멀어지기 때문에 중요한 단어란 뜻임
TF-IDF
- 특정 문서 내에서 빈도수가 높을수록 높아짐
- 전체 문서에서는 빈도수가 낮을수록 높아짐
텍스트 마이닝에서 자주 쓰이는 단어 중요 척도

하고싶은게 너무 많다