
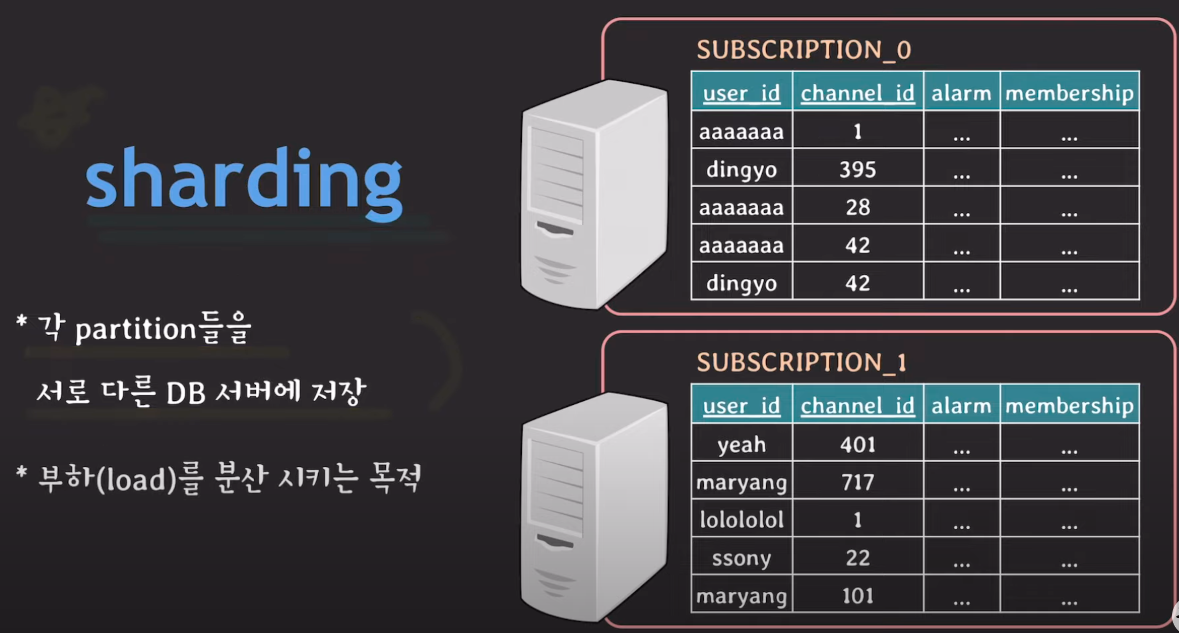
샤딩이란(Sharding)이란?
개념 : 샤딩(Sharding)은 DB 트래픽을 분산할 수 있는 중요한 수단이다.
추가적으로 특정 DB의 장애가 전면 장애로 이어지지 않게 하는 역할도 한다.
즉, 샤딩은 각 DB 서버에서 데이터를 분할하여 저장하는 방식이다.
Q) 샤딩 왜 필요한가 ?
- 기존의 데이터베이스 시스템은 단일 서버에서 모든 데이터를 처리하므로 데이터 양이 많아질수록 성능 저하나 확장에 어려움을 겪을 수 있습니다.
- 이에 비해 샤딩은 데이터를 분산시킴으로써 여러 대의 서버를 사용하고 병렬로 처리함으로써 확장성과 성능을 향상시킬 수 있습니다.
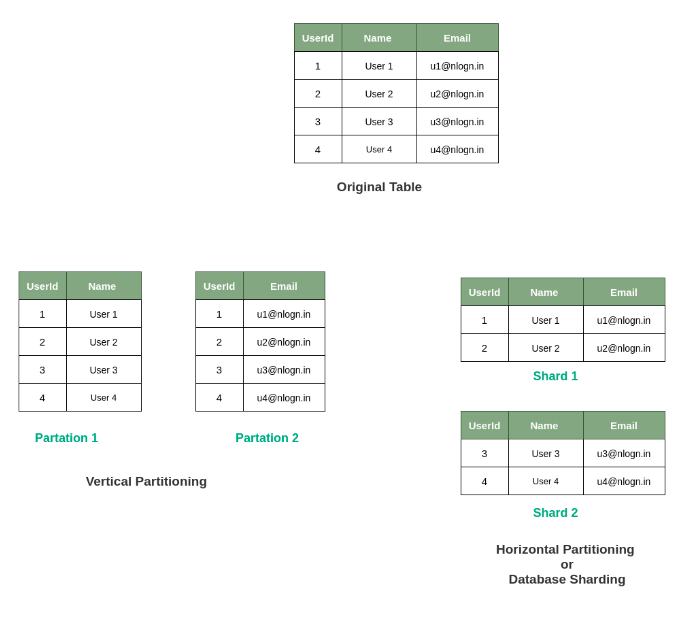
수평적 파티셔닝 vs 샤딩
샤딩은 수평 파티셔닝의 일종으로 볼 수 있다.
그러나,
수평적 파티셔닝은 동일한 DB 서버 내에서 테이블을 분할하는 것이고샤딩은 DB 서버를 분할한다는 것이다.
즉, 샤딩은 DB 서버의 부하를 분산할 수 있다는 것이고, 샤딩은 데이터베이스 차원의 수평 확장(scale-out)인 셈이다.
샤딩의 장단점
샤딩의 장점
- Scale-Out이 가능
- 스캔 범위를 줄여서 쿼리 반응 속도를 빠르게 함
- 장애가 샤드 단위로 발생함
샤딩의 단점
- 프로그래밍 복잡도가 증가
- 데이터가 한 쪽 샤드로 몰릴 경우(Hotspot), 샤딩이 무의미 해짐
- 잘 못 사용할 경우 risk가 큼
- 한번 샤딩 사용시 샤딩 이전의 구조로 돌아가기 힘듬
- 샤딩은 위와 같이 프로그래밍, 운영적 복잡도가 높아지는 단점이 있습니다. 따라서 가능하다면 샤딩을 피하는 방법을 사용하는 것이 좋습니다.
- 대표적인 방법으로는 데이터베이스 서버의 Scale-Up, Read의 부하가 클 경우 Cache 사용 및 Database Replication, 테이블의 일부 컬럼만 주로 사용할 경우 Vertical Partitioning 등의 방법이 있습니다.
샤딩 종류
1. 모듈러 샤딩(Modular Sharding)
모듈러 샤딩(Modular Sharding)은 PK를 모듈러 연산한 결과로 DB를 라우팅하는 방식이다.
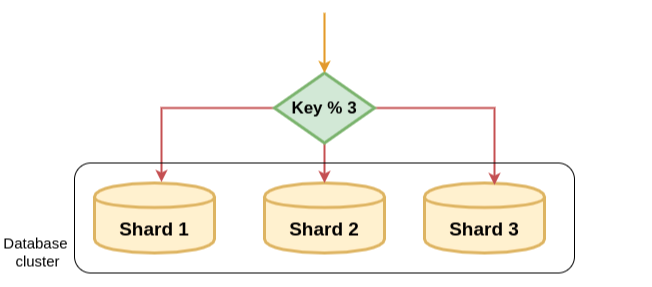
모듈러 샤딩 특징
- 레인지 샤딩에 비해 데이터가 균일하게 분산된다.
- DB를 추가 증설하는 과정에서 이미지 적재된 데이터의 재정렬이 필요하다.
- 데이터가 일정 수준에서 예상되는 데이터 성격을 가진곳에 적용할 때 어울린다.
데이터가 늘어남에 따라 샤딩을 추가적으로 해야하는 상황이 자주 생기면 큰 부하가 발생하기 때문임
데이터가 균일하게 분산된다는 점은 트래픽을 안정적으로 소화하면서도 DB 리소스를 최대한 활용할 수 있다는 것을 의미한다.
2. 레인지 샤딩(Range Sharding)
레인지 샤딩(Range Sharding)은 PK의 범위를 기준으로 DB를 특정하는 방식입니다.
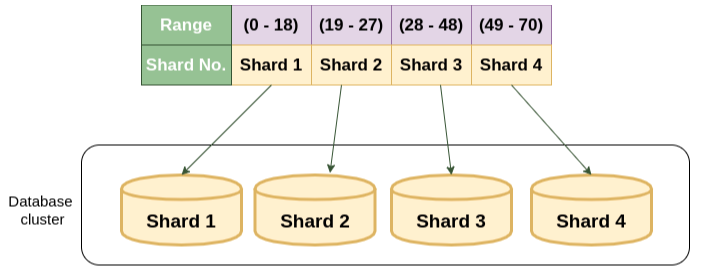
레인지 샤딩 특징
- 모듈러 샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않는다.
- 일부 DB에 데이터가 몰릴 수 있다.
레인지 샤딩의 가장 큰 장점은 증설 작업에 드는 큰 비용이 들지 않는다는 점이다. 데이터가 급격히 증가할 여지가 있다면 레인지 방식은 좋은 선택이 될 것이다.
다만 활성 유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있다. 그러면 또 몰리는 DB는 분산시키고 트래픽이 저조한 DB는 통합시키는 과정이 필요하다. 따라서 적절한 Range 기준을 잡는 것이 중요하다.
3. 디렉토리 샤딩(Directory Sharding)
디렉토리 샤딩(Directory Based Sharding)은 별도의 조회 테이블을 사용해서 샤딩을 하는 경우다.
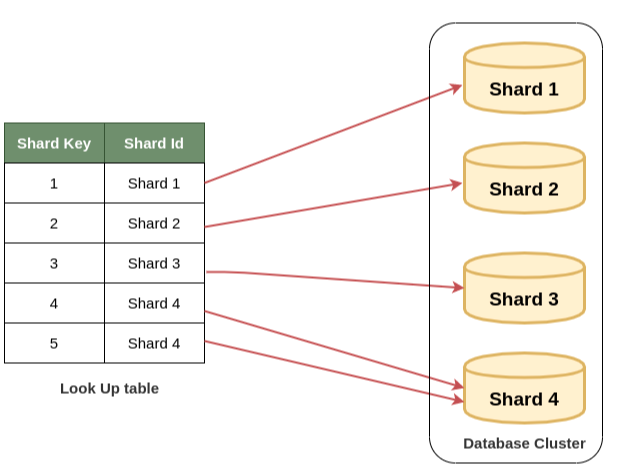
디렉토리 샤딩(Directory Sharding) 특징
- 샤딩에 사용되는 시스템이나 알고리즘을 사용할 수 있다.
- 샤드를 동적으로 추가하는 것도 비교적 쉽다.
- 모든 읽기 및 쓰기 쿼리 전에 조회 테이블을 참조해야 하므로 오버헤드가 발생한다.
결론 및 주의할 점
데이터를 물리적으로 독립된 데이터베이스에 각각 분할하여 저장하므로, 여러 샤드에 걸친 데이터를 조인하는 것이 어렵다. 또한, 한 데이터베이스에 집중적으로 데이터가 몰리면 Hotspot이 되어 성능이 느려진다. 따라서 데이터를 여러 샤드로 고르게 분배하는 것이 중요하다.
Reference & Additional Resources


글이 잘 정리되어 있네요. 감사합니다.