
📚 이진 힙(Binary Heap)
개념 : 노드가 왼쪽 부터 채워지는 완전 이진트리의 일종으로 우선순위 큐를 위해 만들어진 자료구조
이진 힙 특징
- 여러개의 값들 중 최솟값이나 최대값을 빠르게 찾도록 만들어진 자료구조
- 힙은 일종의 반정렬 상태(느슨한 정렬 상태)를 유지한다.
- 부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰(작은) 이진트리
힙트리에서는 중복된 값을 허용한다.이진 탐색 트리에서는 중복된 값을 허용하지 않는다.- 중복이 없어야 하는 이유?
검색 목적 자료구조인데, 중복이 많은 경우에 트리를 사용하여 검색 속도를 느리게 할 필요가 없음
(트리에 삽입하는 것보다, 노드에 count값을 가지게 하여 처리하는 것이 훨씬 효율적)
- 중복이 없어야 하는 이유?
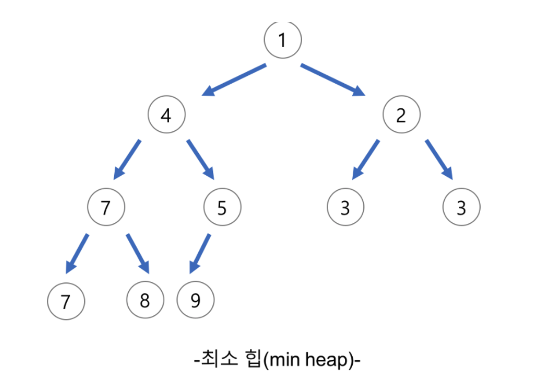
📚 최소 힙(Min Heap)
트리의 마지막 단계에서 오른족 부분을 뺀 나머지 부분이 가득 채워져 있는 이진 트리이며, 각 노드의 원소가 자식들 원소보다 작다.
- 즉 Key(부모 노드) <= Key(자식 노드)인 완전 이진트리의 가장 작은 값은 루트 노드이다.
최소 힙 삽입
: 새로운 요소는 힙의 마지막에 삽입되고, 부모 노드와 비교하면서 힙의 속성을 유지할 때까지 위로 이동합니다.
최대 힙 삭제
: 최솟값(루트 노드)은 쉽게 제거할 수 있습니다. 요소를 제거할 때는 마지막 요소를 루트로 이동시키고, 힙의 속성을 유지하기 위해 아래로 내려갑니다.
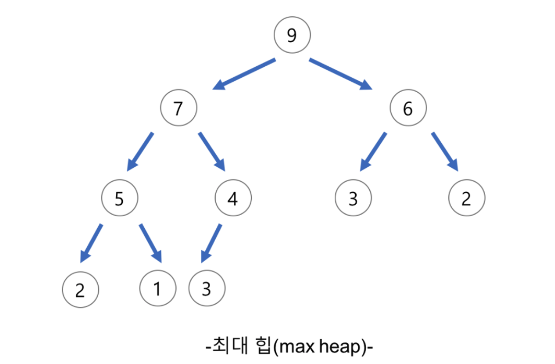
📚 최대 힙(Max Heap)
원소가 내림차순으로 정렬되러있다는 점만 최소힙과 다르다.
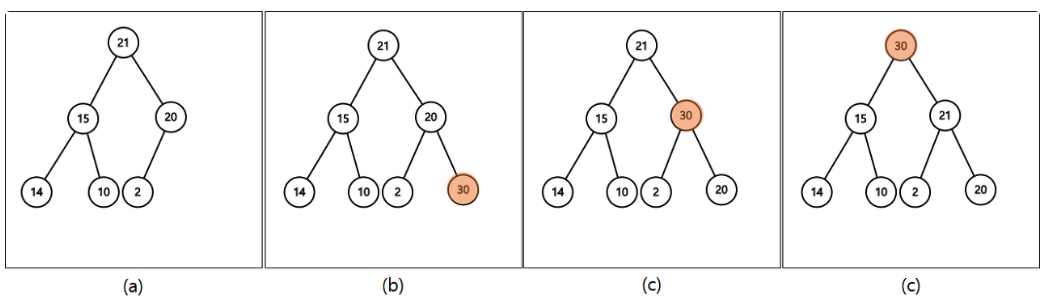
최대 힙 삽입
: 새로운 요소는 힙의 가장 마지막에 삽입되고, 부모 노드와 비교하면서 힙의 속성을 유지할 때까지 위로 이동합니다.
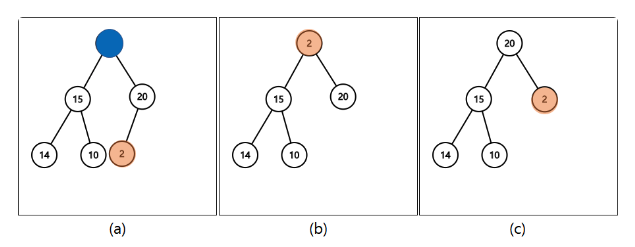
최대 힙 삭제
: 최댓값(루트 노드)은 쉽게 제거할 수 있습니다. 힙에서 요소를 제거하면 일반적으로 마지막 요소를 루트로 이동시키고, 힙의 속성을 유지하기 위해 아래로 내려갑니다.
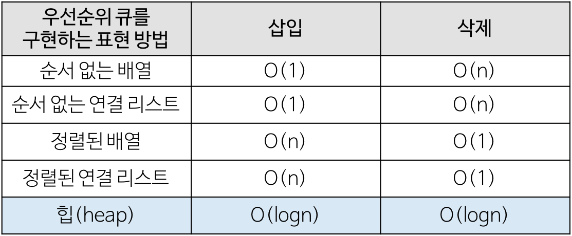
리스트와 힙의 차이점
- 우선순위가 가장 높은 것을 삭제하고 싶을 때 리스트에서는 모든 원소를 확인해야 하므로 O(N)의 시간이 소요
- 힙에서는 삽입할 때 O(logN)이 소요되지만 우선순위가 가장 높은 것을 찾아야 하거나 삭제할 때 O(logN)이 소요되어 리스트보다 효율적이다.
힙 VS 이진 탐색 트리
공통점 : 둘 다 이진트리
차이점
이진 탐색 트리의 노드 값의 크기는 오른쪽 자식 노드 > 부모 노드 > 왼쪽 자식 노드 순이다.
힙은 각 노드의 값이 자식노드보다 크거나 같다 또는 작거나 같다.
힙은 완전 이진 트리이므로, 무조건 왼쪽 자식 노드부터 데이터를 삽입한다.
힙은 데이터의 중복을 허용이진 탐색 트리는 탐색,
힙은 최대/최소값을 구하기 위한 자료구조.

의미있는 성장의 태도, 긍정적인 사고를 지닌 Deveolper