개인적으로 KUSF 러너 스포츠데이터 과정을 이수한 경험이 있는데, 이 때 프로젝트를 진행하면서 내가 했던 전처리를 복습해보려 한다.
나중에 프로젝트에 관해 따로 회고를 하면 좋을 것 같다.
당시 우리 팀은 잠실야구장에서 우천 취소가 된 날의 강수량이 궁금했다.
따라서 아래 순서대로 전처리를 진행했다.
- 기상청에서 송파구 강수량 데이터 수집
- KBO 경기 기록을 통해 언제 우천 취소되었는지 파악
- 우천 취소된 날의 강수량 데이터만 추출
데이터 수집
https://data.kma.go.kr/data/grnd/selectAwsRltmList.do?pgmNo=56
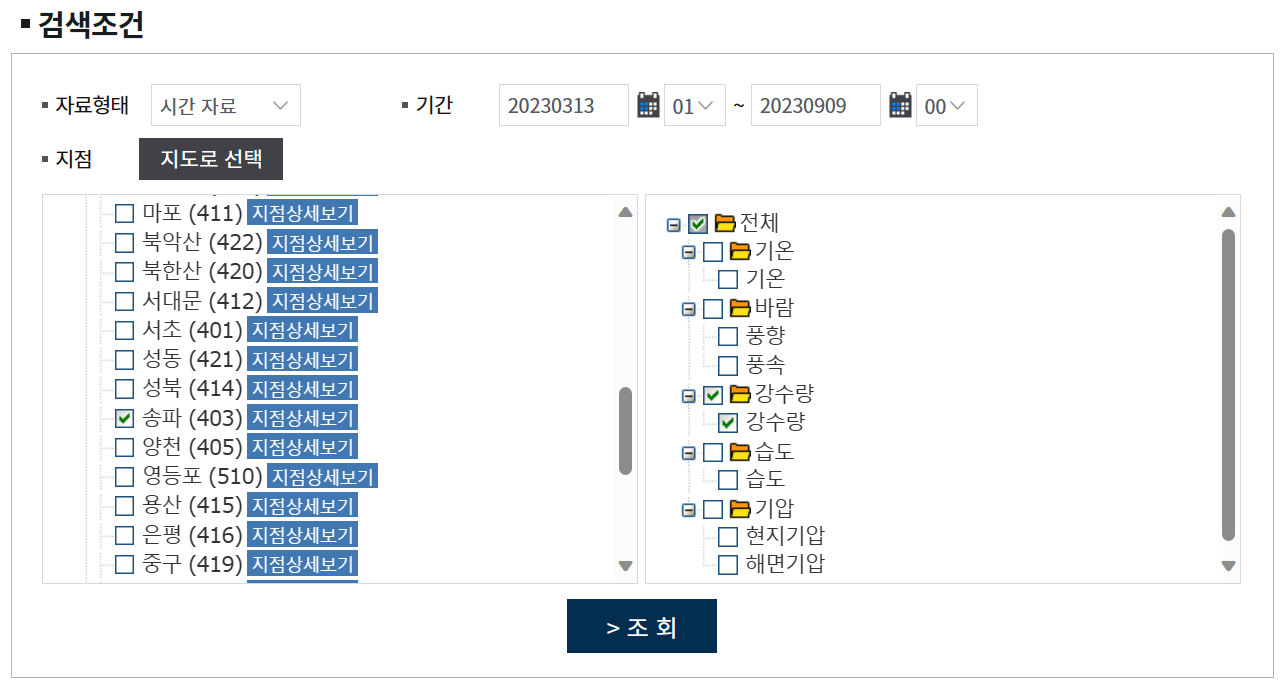
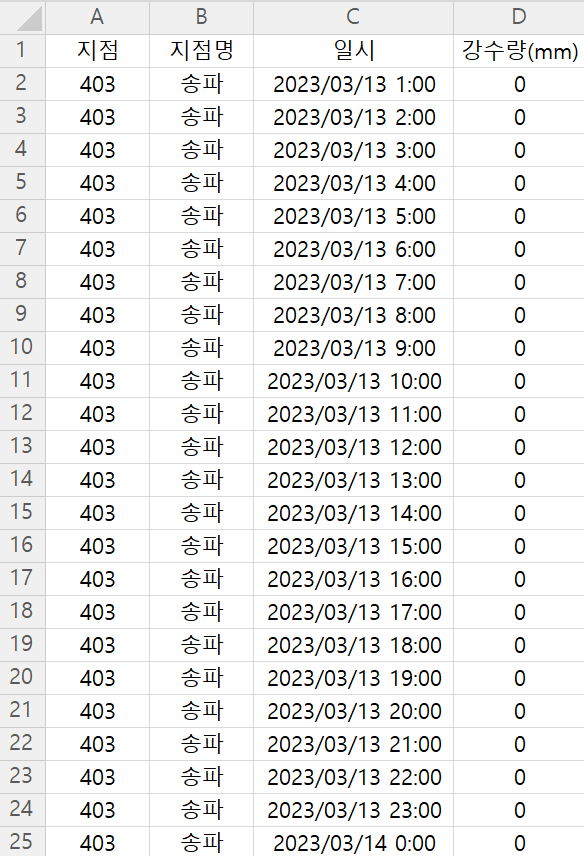 실제 프로젝트 당시 2010년 ~ 2023년 6월 30일까지 강수량 데이터를 처리했지만,
실제 프로젝트 당시 2010년 ~ 2023년 6월 30일까지 강수량 데이터를 처리했지만,
데이터 전처리 과정에 대한 복습을 할 것이기에
2023년 3월 13일 ~ 2023년 9월 9일까지의 강수량 데이터로 복습해 보겠다.
우천 취소일 파악
https://www.koreabaseball.com/Schedule/Schedule.aspx#none
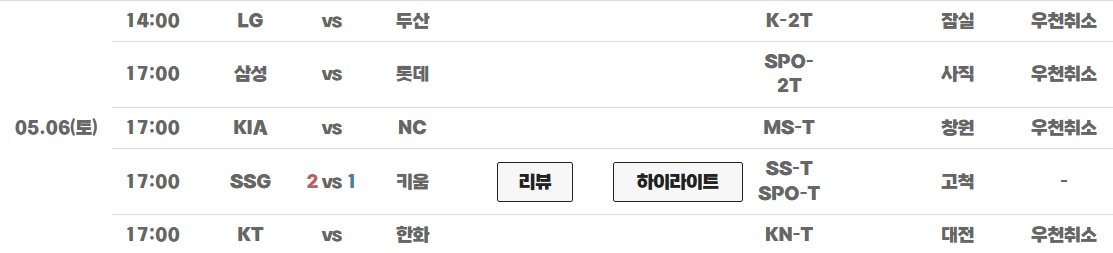 잠실야구장의 우천 취소일은 KBO 경기일정 웹 페이지를 통해 일일이 찾아봐야 했다.
잠실야구장의 우천 취소일은 KBO 경기일정 웹 페이지를 통해 일일이 찾아봐야 했다.
2023년 9월 10일 현재까지, 2023 정규시즌 잠실야구장의 우천 취소일은 이렇다.
'2023/05/06', '2023/05/27', '2023/05/28', '2023/06/29', '2023/07/04', '2023/07/11', '2023/07/13', '2023/07/22',
'2023/07/23', '2023/08/10', '2023/08/18', '2023/08/22', '2023/08/23', '2023/08/29', '2023/08/30', '2023/09/05'데이터 전처리
1. 기상청에서 받은 csv 파일 확인
import pandas as pd
songpa = pd.read_csv('songpa_rain.csv', encoding = 'cp949')
songpa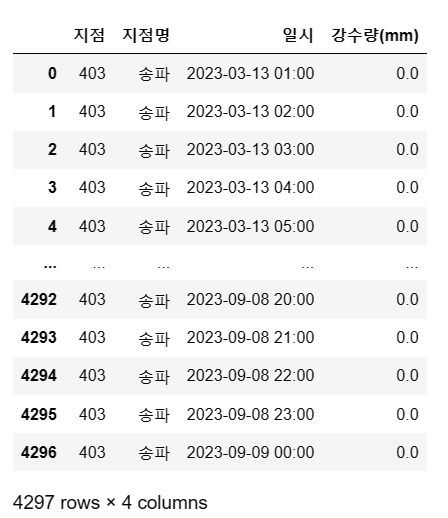
2. 우천 취소일 List 만들기
우천 취소일을 List로 만들어 isin() 메서드를 활용할 계획이었다.
진행하며 YYYY/MM/DD와 YYYY-MM-DD 형식을 통일하지 않아
"isin() 메서드가 왜 안되지" 하며 고통받는 시간도 있었다.
cancel_day = ['2023/05/06', '2023/05/27', '2023/05/28', '2023/06/29', '2023/07/04', '2023/07/11', '2023/07/13', '2023/07/22', '2023/07/23',
'2023/08/10', '2023/08/18', '2023/08/22', '2023/08/23', '2023/08/29', '2023/08/30', '2023/09/05']
# 'cancel_day' 리스트에 있는 날짜 문자열들을 datetime 형식으로 변환한 후
# 다시 문자열로 포맷팅하여 'YYYY-MM-DD'로 맞추기
cancel_day = [pd.to_datetime(date, format='%Y/%m/%d').strftime('%Y-%m-%d')
for date in cancel_day]
cancel_day
3. '날짜'와 '시간' 두 개의 열로 구분하고, '날짜' 열을 datetime 자료형으로 변환
# '일시' 열의 문자열을 공백을 기준으로 분리하여 '날짜'와 '시간' 열로 나누고 df에 추가
songpa[['날짜', '시간']] = songpa['일시'].str.split(' ', expand=True)
# '날짜' 열을 datetime 자료형으로 변환
songpa['날짜'] = pd.to_datetime(songpa['날짜'])
songpa.info()
songpa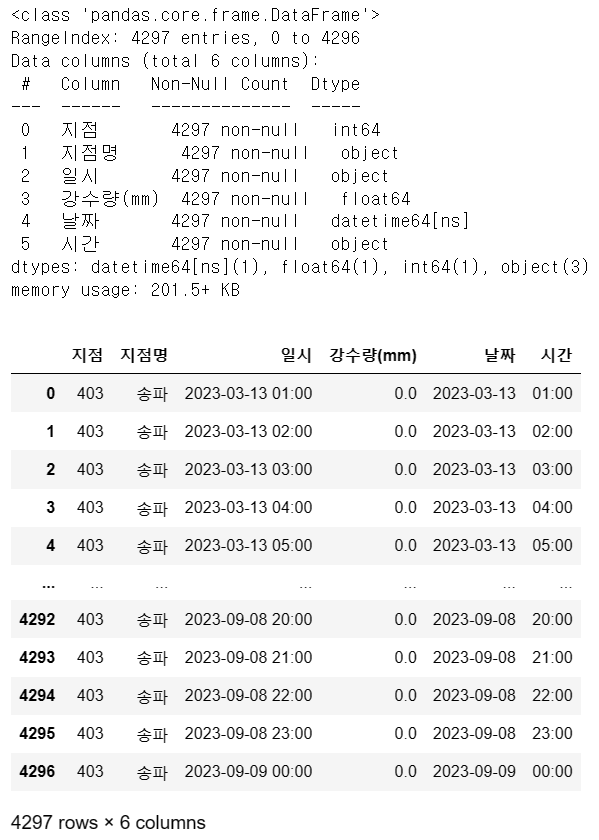
4. 필요한 열만 남기기
songpa = songpa[['날짜', '시간', '강수량(mm)']]
songpa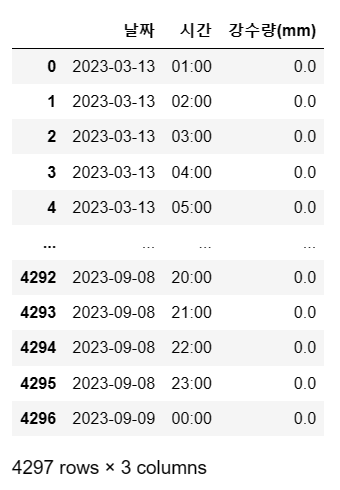
5. isin()메서드 활용
result = songpa[songpa['날짜'].isin(cancel_day)]
result.head(50)
result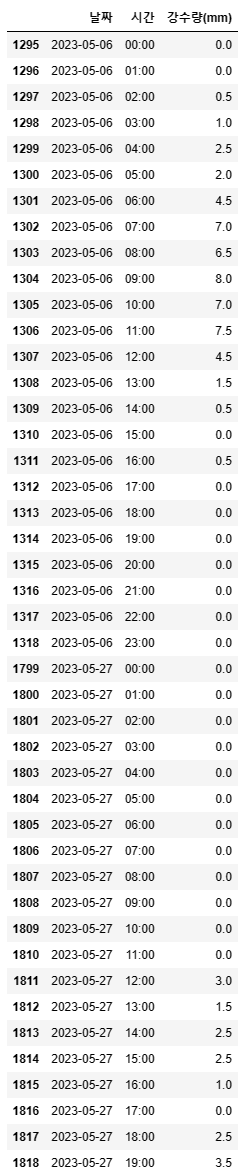
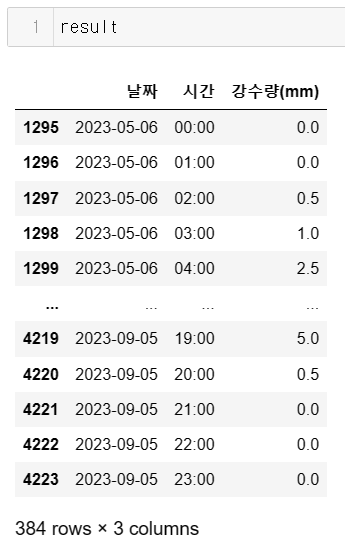
행이 384개인데, cancel_day 날짜가 16개이므로 16 * 24 = 384로 잘 처리된 것 같다.
처음부터 '일시' 열을 datetime 자료형으로 바꾸고 isin() 메서드를 활용하면 각각 00시 강수량만 추출되어 이 방법으로 전처리를 진행했다.
