데이터를 분석하고 해석할 때 중요하고, 기본 개념인 분산(Variance)과 표준편차(Standard Deviation)에 대해 간단히 정리하고자 한다.
분산과 표준편차를 정의하기에 앞서, 산포도는 변량이 흩어져있는 정도를 말한다.
변량들이 평균에 모여 있으면 산포도가 작다고 하고,
변량들이 평균으로부터 떨어져있으면 산포도가 크다고 한다.
산포도를 수치로 나타내는 방법으로 분산과 표준편차가 주로 쓰인다.
개념정리
편차 = 변량 - 평균
분산 = 편차²의 합 / (변량의 개수 - 1)
표준편차 = √분산
지난 학기 전공 수업에서 사용했던 data로 Pandas와 Excel에서 실습을 해보려 한다.
실습(Pandas)
import pandas as pd
df = pd.read_csv('Global_Superstore_Orders_2016.csv', encoding = 'cp949')
df
해당 DataFrame의 'Profit' 열로 실습
# Profit 열만 추출
df = df['Profit']
variance = df.var()
std_deviation = df.std()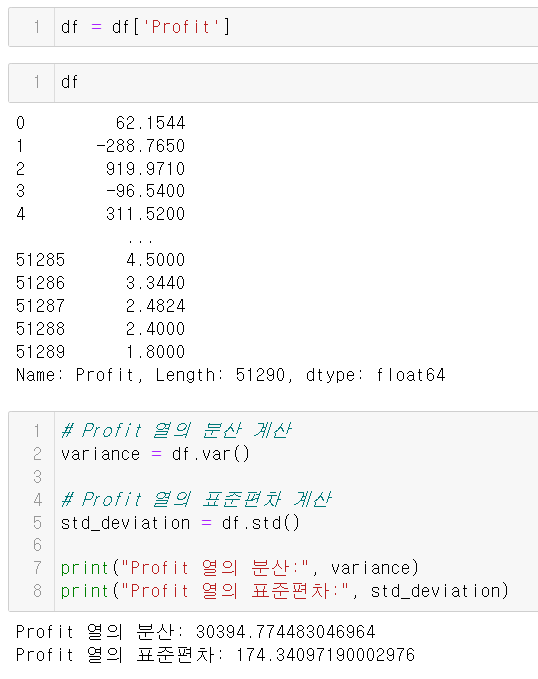
분산이 약 30394.774, 표준편차가 약 174.341임을 확인했다.
이제 Excel에서 실습하며 이와 일치하는지 확인하려 한다.
실습(Excel)
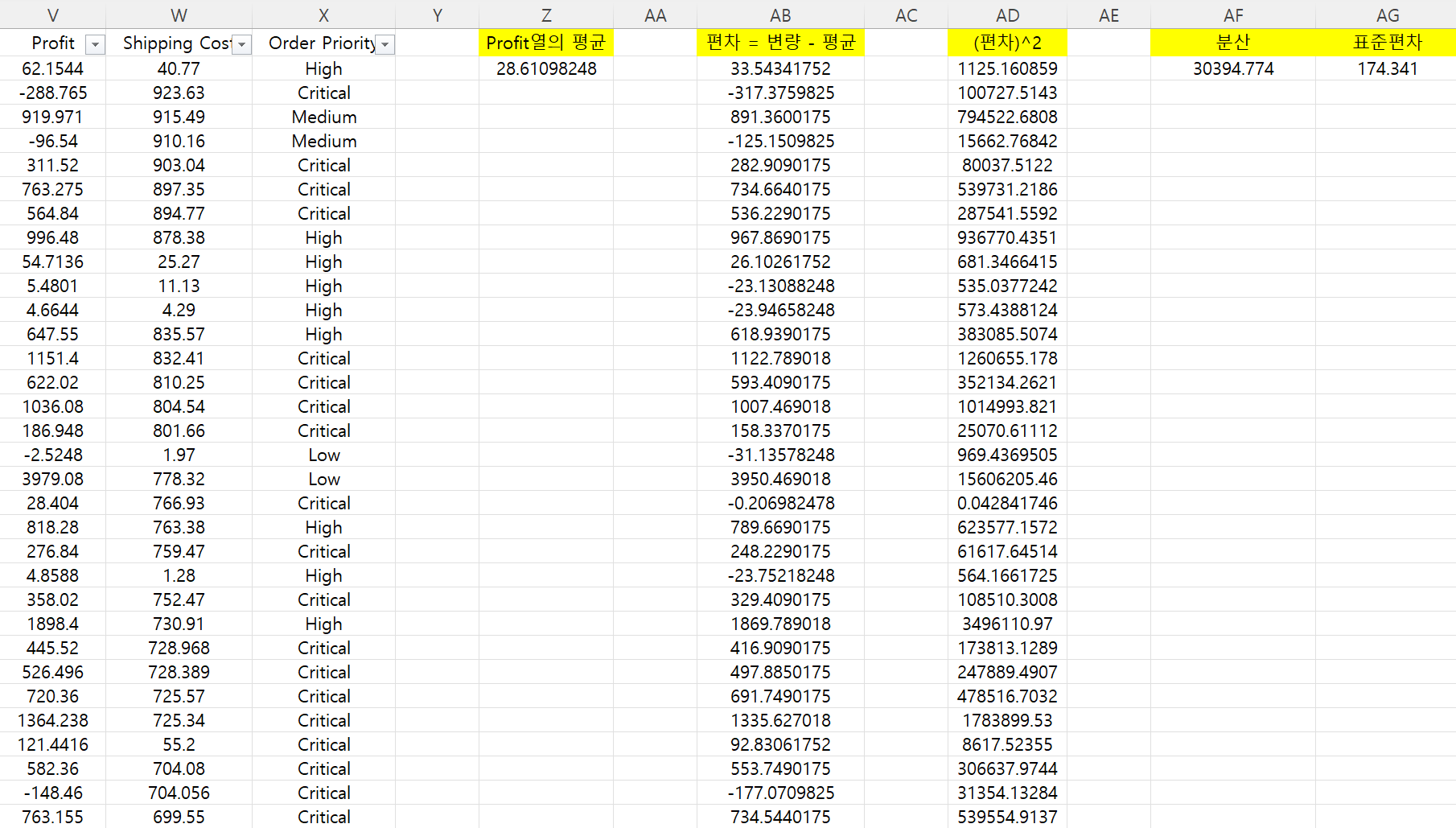
결과를 먼저 보자면, AF열과 AG열을 통해 앞서 Pandas를 통해 구한
분산, 표준편차 값과 일치함을 확인했다.
아래는 Excel에서 분산과 표준편차를 구한 과정이다.
1
편차 = 변량 - 평균
평균 = AVERAGE(V2:V51291)
편차 = V2-$Z$2, V3-$Z$2, V4-$Z$2 ...
2
분산 = 편차²의 합 / (변량의 개수 - 1)
편차² = AB2^2, AB3^2, AB4^2 ...
분산 = SUM(AD2:AD51291) / (COUNT(AD2:AD51291) - 1)
3
표준편차 = √분산
표준편차 = SQRT(AF2)
