오늘은 기업협업 때문에 크롤링을 하다가 발견한 셀레늄의 조건걸기 기능을 개인적인 정리차 포스팅한다.
1. Xpath만 써서는 해결할 수 없는 데이터 발견
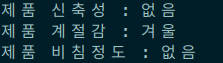
다음은 내가 크롤링해야할 모 의류브랜드의 상품의 상세정보에 대한 페이지 중 일부이다.
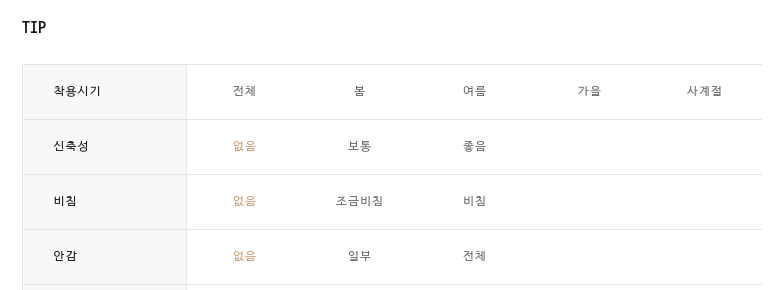
만약 저 데이터중 내가 "신축성 : 없음, 비침 : 없음" 등의 데이터를 긁어와야 한다면 어떻게 해야할까? 단순히 생각했을 때는 해당 페이지의 색깔이 다른 부분만 개발자도구로 Xpath를 긁어오면 되는것 아닌가 라고 생각할 수도 있다. 하지만 만약 내가 저 페이지 뿐만아니라 다른 모든 상품의 비침과 신축성에 대한 데이터를 긁어올 필요가 있다면? 각 의류마다 비치는 정도도, 신축성도 다를 가능성이 있는데 앞에서 말한 방식을 유지한다면 나는 내가 크롤러로 방문하는 모든 페이지에서 "없음, 없음" 이라는 텍스트만 긁어오게 된다. 이를 해결하기 위해 단순히 Xpath로만 긁는것이 아닌, 다른 조건이 더 필요해진다.
2. xpath의 인덱스를 없애고 contains로 조건 추가
그렇다면 저렇게 어떤 부분에 스타일이 바뀔지 알 수 없는경우는 어떻게하면 좋은것일까라고 생각하며 다중조건을 거는 방법을 확인하다가 다음을 발견했다.
우선 내가 긁어와야하는저 누리끼리한 없음의 Xpath와 html 태그는 다음과 같다.
//*[@id="detail1"]/div[2]/table/tbody/tr[2]/td[1]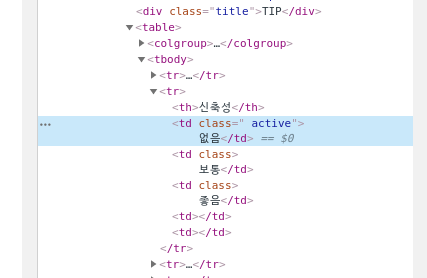
'보통' 이라고 쓰여진 부분의 Xpath와 html 태그는 다음과 같다.
//*[@id="detail1"]/div[2]/table/tbody/tr[2]/td[2]
두 태그의 차이가 보이는가? 바로 클래스 이름이다. 결국 //*[@id="detail1"]/div[2]/table/tbody/tr[2]에 포함된 html td 태그중에, 클래스 명이 "active"인 td태그의 내용을 가져오면 된다.
이때는 contains를 사용하게 된다.
driver.find_element_by_xpath('//*[@id="detail1"]/div[2]/table/tbody/tr[2]/td[contains(@class, "active")]')
인덱스를 없애면 셀레늄은 기본적으로 내가 입력한 패턴에 해당하는 데이터를 모두 가져온다.
find_element_by_xpath를 사용하면 그중에 처음것 하나만, find_elements_by_xpath를 사용하면 여러개를 리스트로 가져오게된다.
이렇게 긁어온 후 .text를 추가하여 텍스트로 변환시켜보면, 누리끼리한 색의 데이터만 들어오는것을 알 수 있다.
(find_elements_by_xpath를 사용한 경우는 selenium이 리스트 자료형으로 데이터를 가져다 주기 때문에 for loop이나 list comprehension을 사용하여 각 데이터에 .text를 붙여줘야만 변환이 된다.)