CSV란 무엇인가
- CSV는 CSV(영어: comma-separated values)는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일이다.(위키피디아)
- 필드에서 이미 눈치를 챘을지도 모르겠지만, 파이썬을 통해 이 python을 통해 내가 필요한 컬럼 값을 크롤링으로 긁어오는 것이 가능하며, 이를 csv로 저장하는것 또한 가능하다
- 또한 django의 ORM을 사용하면 이 CSV를 db에 입력하는것 또한 가능하다. 나는 이번 op.gg클론을 하면서 라이엇에서 JSON으로 뿌려주는 방대한 데이터중에 필요한 필드만을 크롤링하고, 거기에 필요한 이미지 소스의 url을 합쳐서 csv로 만든다음 db에 밀어넣는작업을 여러번 했다.
Json을 크롤링 해서 csv로 만들기
- 우선 request / json / csv 를 import 해준다
import request
import json
import csv- 나는 riot API에서 다음 id를 가진 챔피언들의 내용만 크롤링 해올것이기에 그들의 id값을 미리 리스트에 담아주었다.
champlist = [150, 39, 136, 145, 202, 266, 268, 164, 131, 245]- 변수를 한개 지정하고. csv를 오픈하여 쓰기를 시작한다.
f = open('output.csv', 'w', encoding='utf-8', newline='') ##파일 열기
wr = csv.writer(f) ##열린 파일 쓰기- 이제 requests모듈로 내가 크롤링 하기를 원하는 챔피언 아이디를 for문으로 돌려가며 필요한 내용을 기록한다.
for number in champlist:
a = requests.get(
f"""http://raw.communitydragon.org/latest/plugins/rcp-be-lol-game-data/global/ko_kr/v1/champions/{number}.json"""
) ##챔피언 id를 f-string으로된 url에 삽입하여 각 챔피언의 정보를 불러옴.
b = a.json() ##불러온 정보를 json화
wr.writerow([
b["id"],
b["name"],
b["alias"],
b["title"],
b["shortBio"],
b["passive"]["name"],
b["passive"]["description"],
b["spells"][0]["name"],
b["spells"][0]["description"],
b["spells"][1]["name"],
b["spells"][1]["description"],
b["spells"][2]["name"],
b["spells"][2]["description"],
b["spells"][3]["name"],
b["spells"][3]["description"],
]) ##writerow 메소드를 사용하여 필요한 정보를 입력- 이후 close를 해준다
f.close()구글 스프레드 시트(혹은 Excel)에서 열어보기
-
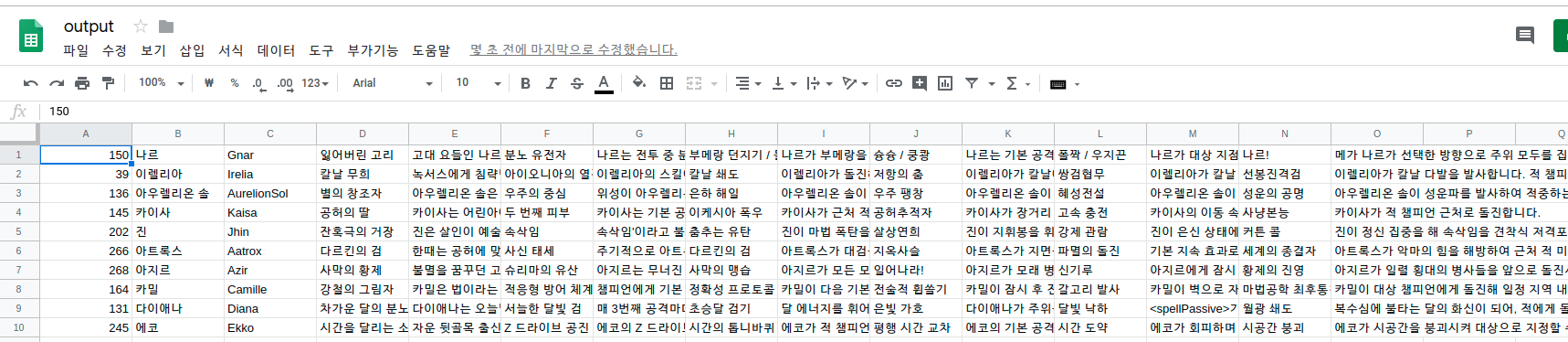
정상적으로 내가 원하는 정보가 크롤링 되었다면 아마도 내가 파이썬 파일을 실행시킨 폴더에 output.csv라는 파일이 생성되었을 것이다.
-
이 파일을 구글csv로 열어보면 다음과 같이 엑셀에서 보기좋게 열린다.
csv를 db에 밀어넣기
- 이번에는 구글 스프레드 시트로 만들어낸 csv를 db로 밀어넣는 법을 알아보려한다.
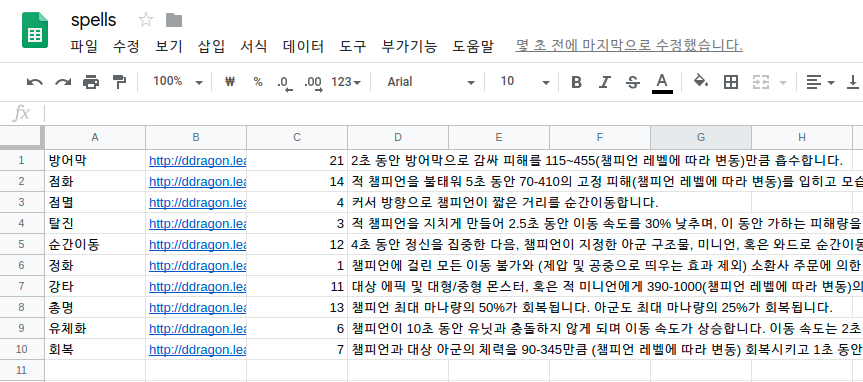
-
위 사진에 보이는 정보는 lol 소환사의 협곡 게임에서 쓰이는 소환사주문의 정보가 담긴 Google Spreadsheet이다
-
이 정보들을
파일 -> 다운로드 -> .csv를 선택하여 컴퓨터로 다운로드한다. -
다운로드 한 파일을 db로 밀어넣을 프로젝트의 최상위 디렉토리에 위치시킨다.
-
필요한 모듈을 임포트한다. django ORM을 사용해야하기 때문에 그와 과련된 모듈도 임포트해야한다.
import os
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'winforgg.settings')
import csv
import django
django.setup()
from spells.models import Spell- 이번에는 쓰기가 아닌 읽기이기때문에 reader메소드를 사용해야한다.
f = open('spells.csv', 'r', encoding='utf-8')
reader = csv.reader(f)- 각 열에 있는 값들을 db의 컬럼값과 매칭시킬수 있도록 다음과 같이 지정해준다.
for row in reader:
spell_name, spell_img_src, riot_spell_id, spell_desc = row
tuple = (spell_name, spell_img_src, riot_spell_id, spell_desc)
info.append(tuple)
f.close()- 읽어온 값들을 bulk_create를 통해 db에 입력해준다.
instances = []
for (spell_name, spell_img_src, riot_spell_id, spell_desc) in info:
instances.append(
Spell(
spell_name = spell_name,
spell_img_src = spell_img_src,
riot_spell_id = int(riot_spell_id),
spell_desc = spell_desc,
)
)
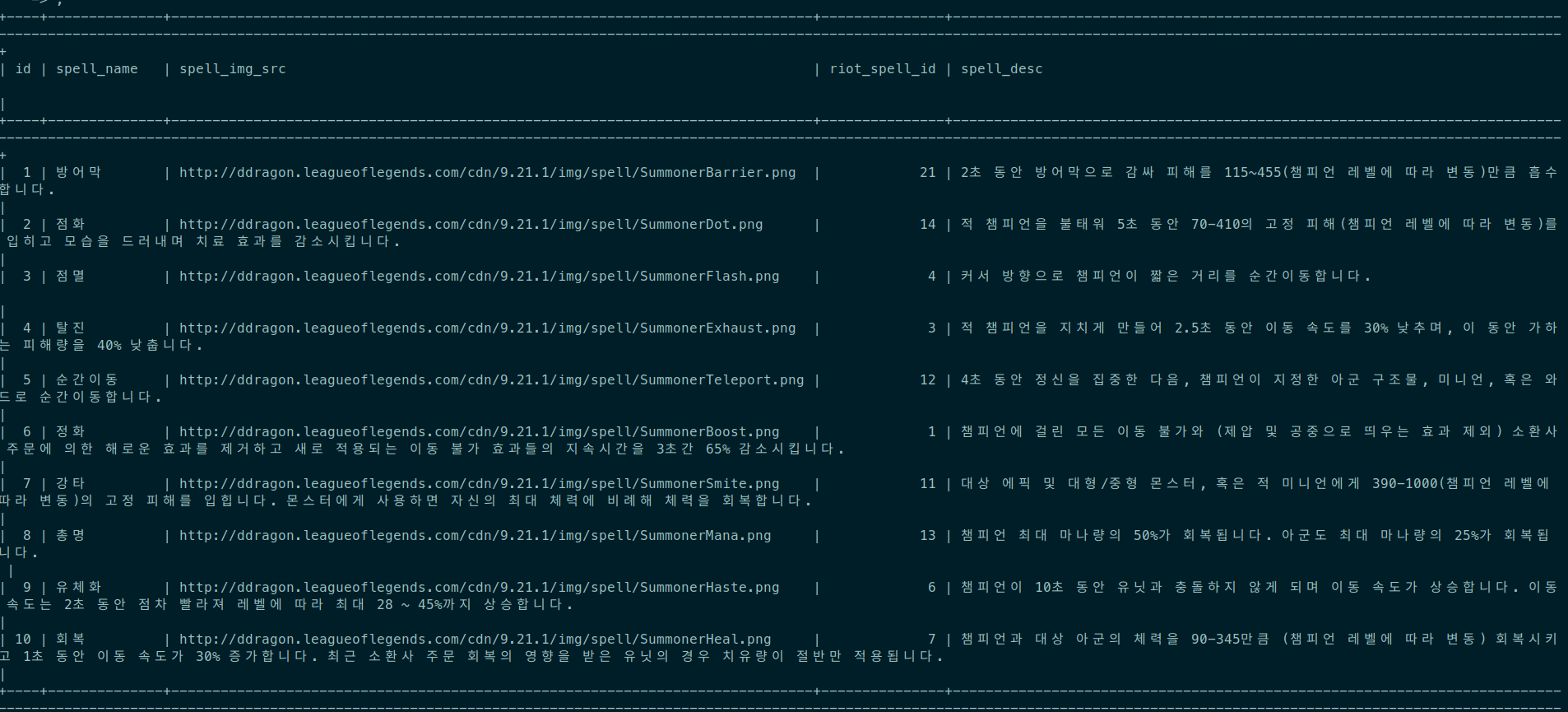
Spell.objects.bulk_create(instances)- 이후 디비에서 확인해보면 이렇게 아름답게 입력된 데이터를 확인할 수 있다.

Back-end Developer, pursuing to be a steadily improving person.