들어가며
친절함은 왜 때로는 과잉이 되는가
LLM과 대화하다 보면, 종종 지나치게 장황하다는 느낌을 받는다. 분명히 한 문장으로 대답해도 되는 쉬운 질문을 던졌는데, 돌아오는 답은 세 단락이나 된다. 간단한 사실만 확인하고 싶었는데, 모델은 배경 설명을 덧붙이고, 주의사항을 붙이고, 마지막에는 정리와 후속 질문까지 추천해준다. 이 답변은 대개 틀리지는 않는다. 그런데도 어딘가 불편하다. 꼭 이렇게 말을 많이 해야 하나 싶은 생각이 든다.
LLM을 둘러싼 논의는 대체로 정확성, 환각(hallucination), 추론(Reasoning), 정렬(alignment) 같은 문제에 집중해 왔다. 물론 이런 주제는 중요하다. 다만 실제 사용 경험에서 사용자가 자주 부딪히는 문제는 '틀린 답변'만은 아니다. '너무 긴 답변'도 때때로 문제가 된다.
이 현상은 단순히 스타일의 문제가 아니다. 길고 친절한 답변은 더 나은 답처럼 보이기 쉽다. 정보가 많을수록 성실해 보이기 때문이다. 설명이 길수록 똑똑해 보이기도 한다. 그러나 대화는 정보를 가능한 한 많이 쏟아내는 행위가 아니다. 좋은 대화는 상대가 지금 필요로 하는 만큼만, 적절한 밀도와 길이로 정보를 건네는 행위다. 그런 점에서 LLM의 장황함은 단순히 수다스러운 말버릇이 아니라, 대화의 기본 원리를 자주 놓치는 방식이라고 볼 수 있다.
이 지점에서 언어학, 그중에서도 화용론(Pragmatics)은 매우 유용한 관점을 제공한다. 화용론은 문장의 사전적 의미만이 아니라, 발화가 실제 대화 속에서 어떻게 기능하는지를 묻는다. 화용론은 '누가 말하는가', '누구에게 말하는가', '무엇을 물었는가', '어디까지 말해야 충분한가', '무엇은 생략해도 되는가'와 같은 질문을 던진다. 그리고 이 질문들은 오늘날 LLM의 응답을 이해하는 데도 적용될 수 있다.
특히 이 글이 주목하고자 하는 개념은 그라이스(Grice)의 양의 격률(Maxim of Quantity)이다. 양의 격률에 따르면, 필요한 만큼만 말해야 한다. 필요 이상으로 말해서도 안 된다. 같은 질문이더라도 어떤 상황에서는 한 문장의 답변만으로도 충분하고, 어떤 상황에서는 자세한 설명이 필요하다. 즉, 양의 격률은 발화의 길이를 일괄적으로 줄이라는 규칙이 아니라, 정보량을 맥락에 맞게 조절하라는 원칙이다.
이 관점에서 보면, LLM의 장황함은 조금 다르게 보이기 시작한다. 문제는 모델이 너무 많이 안다는 데 있지 않다. 문제는 모델이 질문이 요구한 정보량을 자주 초과한다는 데 있다. 예를 들어, 사용자는 실행 가능한 한 줄을 원했는데, 모델은 배경지식과 예외사항까지 붙인다. 이때 모델은 틀리지 않을 수 있다. 그러나 협력적인 대화를 하고 있다고 보기는 어렵다.
LLM은 왜 이렇게 정보량을 초과하는 방향으로 응답하게 되었을까. 이것은 단순히 말투의 문제가 아니라, 선호 학습(Preference Learning), 직접 선호 최적화(Direct Preference Optimization, DPO), 보상 모델(Reward Model)의 길이 편향(length bias), 그리고 추론 예산(reasoning budget) 같은 학습 구조와 연결된 문제일 수 있다. 다시 말해, 장황함은 우연한 출력 습관이 아니라, 오늘의 정렬된 모델이 학습해 온 방식의 결과일 가능성이 크다. [1] [3] [4]
이 글에서는 먼저 양의 격률이 무엇인지 간단히 살펴본다. 그다음 LLM의 장황함이 실제로 어떤 현상으로 나타나는지 정리한다. 이어서 왜 이런 현상이 생겨났는지를 최근 연구를 바탕으로 살펴본다. 마지막으로, 모델이 필요한 말만 하게 만들기 위해 연구자들이 어떤 해결책을 제안하고 있는지도 함께 본다.
1. 양의 격률(Maxim of Quantity)
왜 적당히 말해야 좋은 대화인가
우리는 보통 좋은 대화를 '많이 말하는 대화'라고 생각하지 않는다. 질문이 간단하면 답도 간단해야 한다. 설명이 필요한 상황이라면 그만큼 자세해져야 한다. 즉, 대화 맥락에 따라 전달하는 정보량을 적절하게 조절해야 좋은 대화라고 할 수 있다.
이것을 설명하는 대표적인 개념이 그라이스(Grice)의 협력 원리(Cooperative Principle)다. 그라이스는 대화가 단순히 문장을 주고받는 일이 아니라, 서로 협력하면서 의미를 조정하는 과정이라고 보았다. 우리는 대화할 때 아무 말이나 던지지 않는다. 상대가 묻는 바에 맞추어, 지금 이 상황에서 적절한 방식으로 응답하려고 한다. 양의 격률(Maxim of Quantity)은 바로 이 협력의 한 조건을 설명한다.
양의 격률은 보통 다음의 두 문장으로 요약된다.
- 대화의 목적에 필요한 만큼은 정보를 제공해야 한다.
- 필요한 것보다 더 많은 정보를 제공해서는 안 된다.
즉, 양의 격률은 질문이 요구하는 정보량을 맞추라는 원칙이라고 할 수 있다. 예를 들어 누군가 “지금 몇 시야?”라고 물었을 때, “세 시 십 분이야”라고 답하면 충분하다.
그런데 여기에 “정확히는 오후 세 시 십 분이고, 오늘 일정상 지금 출발하면 도착은 네 시쯤이고, 보통 이 시간대에는 길이 막히지 않고...”와 같은 설명이 계속 이어진다면 어떨까. 내용이 틀린 것은 아닐 수 있다. 오히려 친절해 보일 수도 있다. 하지만 질문이 요구한 정보량은 이미 넘어서고 있다. 이 순간 대화는 성실해 보이면서도, 동시에 어딘가 과잉된 느낌을 준다.
결국 양의 격률은 대화를 절제의 기술로 바라보게 한다. 좋은 대화는 정보를 아끼는 대화도 아니고, 정보를 과시하는 대화도 아니다. 상대가 지금 필요로 하는 만큼을 가장 적절한 길이로 건네는 대화이다. 이 관점에서 보면, LLM의 장황함은 단순한 스타일의 차이가 아니다. 그것은 대화의 가장 기본적인 협력 원리 중 하나를 자주 놓치는 현상으로 읽을 수 있다.
2. LLM은 말이 너무 많다.
2.1. 장황함을 측정하는 벤치마크 YapBench
LLM의 장황함을 양적으로 측정해보려는 시도가 등장하고 있다. YapBench는 '짧은 답변이 적절한 질문'을 따로 수집한 뒤, 모델이 그 기준선을 얼마나 초과해서 말하는가를 측정하는 벤치마크다. [1] 각 문항은 단일 턴 프롬프트, 사람이 정한 최소 충분 답변(minimal-sufficient baseline answer), 그리고 문항 유형 라벨로 구성된다. 핵심 지표인 YapScore는 기준선보다 얼마나 더 길게 답했는지를 문자 수 기준으로 계산하고, YapIndex는 범주별 중앙값 YapScore를 평균 내어 모델의 전반적인 장황함을 요약한다.
YapBench는 300개가 넘는 영어 프롬프트를 세 유형으로 나눈다. 첫째는 짧은 확인이나 되물음이 가장 적절한 모호한 입력이다. 둘째는 짧고 안정된 답이 가능한 사실 질문이다. 셋째는 한 줄짜리 명령문이나 코드 조각이면 충분한 기술 요청이다. 이 틀로 76개의 assistant LLM을 평가한 결과, 모델들 사이에는 중간 초과 길이에서 큰 격차가 나타났고, 특히 모호한 입력에서는 모델이 빈칸을 스스로 채우듯 길게 설명하는 vacuum-filling, 한 줄 코딩 요청에서는 설명과 서식을 과도하게 붙이는 경향이 관찰되었다.
LLM의 장황함 문제는 답변을 어디에서 멈춰야 하는지를 모른다는 데 있다. YapBench는 바로 그 멈춤의 실패를 측정 가능한 현상으로 바꾸어 보여준다.
2.2. 불필요한 정보의 누적
장황함의 더 핵심적인 문제는, 응답 안에 최소 답을 넘어서는 정보가 반복적으로 덧붙는다는 점이다. ACL 2025 Findings에 실린 Brevity is the soul of sustainability는 12개의 decoder-only LLM을 5개 데이터셋에서 비교했다. 그 결과, 이 모델들이 자주 필요 이상으로 긴 응답을 생성하고, 필요한 최소 답을 넘어서는 중복 정보나 추가 정보를 함께 넣는다고 보고했다. [2]
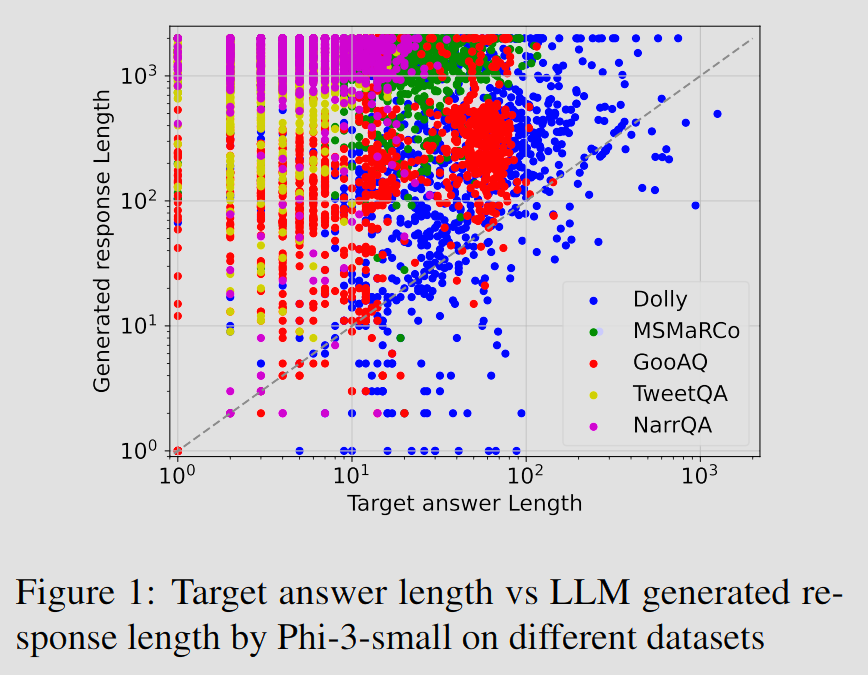
- 위 그래프는 Phi-3-small 모델이 각 QA 데이터셋에 대해 이상적인 답변의 길이(target answer length)와 생성한 답변의 길이(generated response length)를 비교한 그래프이다. 대부분의 경우 생성된 답변의 길이가 이상적인 답변의 길이를 초과한 것을 볼 수 있다.
이 연구가 보여 주는 것은, LLM의 긴 답변이 언제나 더 풍부한 답변은 아니라는 점이다. 질문에 대한 직접적인 답변은 이미 한두 문장 안에 끝났는데도, 그 뒤에 배경지식, 주의사항, 예외 사례가 연속해서 덧붙는다. 각각은 유용해 보일 수 있지만, 전체 응답의 관점에서는 질문의 초점을 흐리고 독해 비용만 높이기도 한다. 결국 장황함의 본질은 단순히 길다는 데 있지 않다. 멈춰야 할 지점을 지나서도 계속 말한다는 데 있다.
3. LLM은 왜 말이 많아졌을까?
3.1. 선호 학습(Preference Learning)은 길이가 긴 답을 좋아하게 만들 수 있다.
최근 LLM이 장황한 답변을 출력하는 원인이 선호 학습(preference learning)에 있다고 보는 연구들이 등장했다. 특히 RLHF(Reinforcement Learning from Human Feedback)에서는 사람이 더 선호한 답변을 바탕으로 보상 모델(Reward Model)을 학습시키는데, 이 과정에서 긴 답변이 더 성실하고 도움이 되는 답변처럼 평가되는 편향이 함께 들어갈 수 있다. ALBM 논문은 보상 모델이 응답 길이를 과도하게 중시하는 길이 편향(length bias)을 보일 수 있으며, 이 편향이 지나치게 장황한 응답을 유도해 정렬 품질을 해칠 수 있다고 지적한다. 저자들은 응답 길이가 인간 평가에서 문맥 의존적인 요소라고 보고, 길이 편향을 무조건 제거하기보다 질문의 성격에 따라 다르게 다루어야 한다고 제안한다.[3] 즉 문제는 길이 그 자체가 아니라, 길이가 품질의 대리 지표처럼 오인되는 상황에 있다.
이러한 관점에서 보면 장황함은 "평가 신호의 왜곡된 학습 결과"에 가깝다. 모델은 더 좋은 답을 하도록 학습된 것이지만, 실제로는 더 좋게 보이는 답의 형식을 함께 학습한 것일 수 있다. 그 결과 지나치게 설명을 늘어놓는 방향이 강화된다. 결국 선호 학습의 문제는 길이와 품질을 충분히 분리하지 못한 채 선호를 학습한다는 점이다.
3.2. DPO는 구조적으로 길이 편향을 증폭시킬 수 있다.
RLHF를 간소화한 DPO(Direct Preference Optimization)도 역시 장황함 문제를 피하지 못한다. ACL 2024 Findings의 Disentangling Length from Quality in Direct Preference Optimization 논문은 DPO에서 길이 편향의 적극적 활용이 나타난다고 보고한다. 저자들은 이를 out-of-distribution bootstrapping과 연결하며, DPO가 학습 과정에서 길이를 품질의 손쉬운 신호로 이용할 수 있다고 설명한다. 이 논문에 따르면, 길이가 긴 응답이 우연히 더 자주 선택되면, DPO는 그 경향을 그대로 학습하는 데서 멈추지 않는다. 학습이 진행되면서 모델은 길이를 늘리는 방식 자체를 유리한 전략으로 활용할 수 있다. 저자들은 길이 정규화를 도입해 이 문제를 완화했고, 길이를 통제한 평가에서 최대 20%의 win rate 개선을 보고했다.[4] 즉 DPO의 장황함 문제는 긴 답을 좋아한다는 단순 취향이 아니라, 길이를 더 쉽게 최적화할 수 있다는 구조적 성질에 있다.
이 문제를 더 직접적으로 다룬 것이 EMNLP 2024의 SamPO다. 이 논문은 DPO 알고리즘 내부에 '응답 길이에 대한 구조적 의존성(algorithmic length reliance)'이 숨어 있다고 지적한다. 이 논문에 따르면, DPO에서 선택된 응답이 더 길면 토큰 수가 많아져 보상이 과대평가되고, 더 짧으면 품질이 좋아도 보상이 과소평가될 수 있다는 것이다. 이를 완화하기 위해 SamPO는 선택된 응답과 거절된 응답에서 동일한 수의 토큰만 각각 추출해 비교하는 down sampling을 도입했고, 여러 벤치마크에서 장황함 완화와 5%에서 12% 수준의 성능 개선을 보고했다.[5]
정리하면, 선호학습이 길이를 품질처럼 오해하는 문제라면, DPO는 그 오해를 학습 과정에서 더 강하게 밀어붙일 수 있는 구조를 가진다고 할 수 있다. 그래서 장황함은 정렬 알고리즘이 선택한 손쉬운 최적화 경로일 수 있다.
4. 말이 많으면 무엇이 문제가 될까?
4.1. 사용자 경험(UX)의 문제
장황한 답변은 먼저 읽기 경험을 해친다. 사용자가 원하는 것은 대개 "더 많은 텍스트"가 아니라 "더 빠른 해결"이다. 그런데 짧게 끝날 수 있는 질문에 긴 답변이 나오면, 사용자는 불필요한 문장들을 읽으며 시간 낭비를 해야 한다. YapBench[1]가 측정한 것도 바로 이러한, 사용자에게 직접 드러나는 과잉 생성(user-visible over-generation)이다. 짧은 답이 적절한 상황에서 모델이 계속 설명을 붙이는 현상은, 단순한 스타일 차이가 아니라 사용자 경험의 문제로 드러난다.
이 문제는 모호한 입력에서 더 두드러진다. 모호한 입력에서 짧게 되묻기보다 일반론을 길게 늘어놓는 빈칸 메우기식 설명(vacuum-filling)은 UX를 더 악화시킨다. 사용자는 아직 답을 받을 준비가 되지 않았는데, 모델이 먼저 과잉 설명을 시작하기 때문이다. 이때 문제는 정보 부족이 아니라, 응답 길이와 응답 타이밍이 사용자 의도와 어긋난다는 데 있다.
4.2. 정확한 소통의 문제
장황함은 소통의 정확성도 해친다. Brevity is the soul of sustainability[2]는 많은 LLM이 최소 답변 외에 중복 정보나 추가 정보를 함께 넣는다고 보고했다. 질문에 대한 직접 답이 이미 제시된 뒤에도, 배경 설명이나 일반론 등이 계속 덧붙는다는 뜻이다. 이런 정보가 항상 틀린 것은 아니지만, 질문의 초점을 흐릴 수 있다.
핵심 답과 부가 설명의 경계가 흐려지면, 사용자는 무엇이 직접적인 답이고 무엇이 주변 설명인지 스스로 걸러내야 한다. 즉 정보가 많아질수록 소통이 정교해지는 것이 아니라, 오히려 질문의 중심이 희석되는 방향으로 갈 수 있다. 이는 앞에서 본 양의 격률의 관점에서도 분명한 위배다.
4.3. 비용과 자원의 문제
장황함은 비용 문제이기도 하다. YapBench는 추론 비용이 생성 토큰 수에 거의 선형적으로 비례하기 때문에, 불필요하게 긴 응답은 곧바로 더 많은 에너지 사용으로 이어진다고 지적한다. 같은 품질의 답을 더 짧게 줄 수 있다면, 길게 말하는 것은 계산 자원을 낭비하는 셈이다.
이 문제는 실제 절감 효과로도 확인된다. Brevity is the soul of sustainability는 길이 축소를 유도하는 단순한 프롬프트만으로도 응답 길이를 줄이면서 25–60% 수준의 에너지 최적화가 가능했다고 보고했다. 이는 장황함이 단지 읽기 피로의 문제를 넘어, 서비스 운영 비용과 추론 효율까지 좌우하는 문제임을 보여준다.
5. LLM이 필요한 말만 하게 하려면
그렇다면 어떻게 해야 LLM의 장황함을 줄이고 필요한 말만 하게끔 만들 수 있을까? 이 장에서는 LLM의 장황함을 줄이기 위한 방법으로, 프롬프트, 길이 지시 추종, 보상 모델 교정, 정렬 알고리즘 수정, 추론 예산 최적화라는 다섯 가지 층위를 중심으로 살펴본다.
5.1. 프롬프트 엔지니어링을 통한 해결
가장 간단한 방법은 프롬프트를 바꾸는 것이다. Brevity is the soul of sustainability[2]는 "짧게 답하라(Answer briefly)", "최소한의 답변만 제공하라(Only provide the minimal answer)", "불필요한 텍스트나 대화체적 표현을 생성하지 마라. (not to produce redundant text or conversational enhancements)", "N단어 이내로 답하라" 같은 지시를 비교했고, 이런 프롬프트가 거의 모든 모델에서 응답 길이를 줄였다고 보고했다. 같은 논문은 적절한 프롬프트만으로도 응답 품질을 유지하면서 에너지 사용을 25–60%까지 줄일 수 있다고 정리한다. 특히 "최소한의 답변만 제공하라"라는 지시는 약 60%의 응답 길이를 줄여 가장 높은 단축률을 보였다.
5.2. 길이 지시를 따르도록 별도로 학습시키기
프롬프트만으로 부족하다면, 길이 제약을 따르는 능력 자체를 학습시킬 수 있다. EMNLP 2025의 Following Length Constraints in Instructions[6]는 원하는 길이 정보를 포함한 지시문으로 모델을 훈련했고, 이렇게 학습된 모델이 길이 지시가 포함된 평가에서 GPT-4, Llama 3, Mixtral 같은 일반 instruction 모델보다 더 잘 통제된 출력을 보였다고 보고했다. 길이 제어를 부가 옵션이 아니라 instruction following의 일부로 본 셈이다.
5.3. Reward Model의 길이 편향 자체를 교정하기
문제가 보상 신호에 있다면, 보상 모델을 직접 교정하는 방법도 있다. Post-hoc Reward Calibration은 추가 데이터나 재학습 없이 길이 편향 항을 추정해 제거하는 방법을 제안했고, RewardBench의 33개 reward model에서 평균 3.11의 성능 향상과 length-controlled win rate의 10% 개선을 보고했다.[7] 핵심은 짧게 만들기보다, 보상 모델이 길이를 품질로 오인하지 않게 만드는 데 있다.
5.4. DPO 계열 알고리즘을 길이에 둔감하게 바꾸기
DPO 쪽에서는 목적함수 자체를 손보는 연구가 나왔다. Disentangling Length from Quality in Direct Preference Optimization는 길이 exploitation을 막는 정규화를 제안했고, 길이를 통제한 평가에서 최대 20%의 win rate 개선을 보고했다.[4] 이어서 SamPO는 DPO 내부의 algorithmic length reliance를 문제로 지적하고, 선택·거절 응답에서 동일한 수의 토큰만 비교하는 down-sampled KL divergence를 도입해 장황함을 완화하면서 5–12%의 성능 개선을 얻었다.[5] 해결의 핵심은 답을 짧게 강제하는 것이 아니라, 길이가 품질의 지름길로 쓰이지 못하게 막는 데 있다.
5.5. Reasoning Model의 길이 예산을 직접 최적화하기
추론형 모델(reasoning model)에서는 아예 토큰 예산을 학습 목표에 넣는 방향이 등장했다. ALP는 문제별 solve rate에 따라 길이 패널티를 다르게 주어 쉬운 문제에는 짧게, 어려운 문제에는 충분히 길게 생각하게 만들고, 평균 토큰 사용량을 50% 줄이면서 성능 저하를 크게 만들지 않았다고 보고했다.[8] LACONIC은 목표 토큰 예산을 RL objective에 직접 넣어 수학 추론에서 출력 길이를 50% 이상 줄이면서 pass@1을 유지하거나 개선했고, 일반 지식과 다국어 평가에서도 44% 적은 토큰으로 성능을 유지했다고 보고했다.[9] 이 흐름은 모든 답을 짧게 만드는 것이 아니라, 문제 난이도에 맞게 길이를 배분하는 방향에 가깝다.
6. 결론
LLM의 장황함은 단순히 말투의 문제가 아니다. 이 글에서 보았듯이, 그것은 화용론의 관점에서는 양의 격률을 자주 벗어나는 현상으로 읽을 수 있고, 기술적 관점에서는 선호 학습, 기술적 관점에서는 선호 학습, 보상 모델의 길이 편향, DPO의 구조적 특성이 맞물려 생겨난 결과로 볼 수 있다. 최근 연구들이 장황함을 별도의 벤치마크로 측정하고, 길이 편향을 정렬 문제의 핵심 변수로 다루기 시작한 것도 이 현상이 더 이상 사소한 스타일 문제가 아님을 보여준다.
중요한 것은, 긴 답변이 언제나 더 좋은 답변은 아니라는 점이다. 질문에 대한 직접적인 답이 이미 제시된 뒤에도 배경 설명, 일반론, 예외 사항이 계속 덧붙으면, 사용자는 더 많은 정보를 받는 대신 더 높은 독해 비용을 치르게 된다. 그 결과 사용자 경험은 나빠지고, 질문의 초점은 흐려지며, 불필요한 토큰 생성으로 비용과 자원도 더 많이 소모된다.
그렇기 때문에 해결도 한 가지 방법으로 끝나지 않는다. 프롬프트 엔지니어링은 가장 손쉬운 출발점이고, 길이 제약을 따르도록 별도로 학습시키는 방법은 길이 제어를 instruction following의 일부로 만든다. 더 나아가 보상 모델의 길이 편향을 교정하거나, DPO 계열 알고리즘이 길이를 손쉬운 편법으로 삼지 못하게 바꾸거나, 추론형 모델에서 토큰 예산 자체를 최적화하는 접근도 등장하고 있다. 최근 연구의 흐름은 공통적으로, 응답을 무조건 짧게 만들려는 것이 아니라 질문의 성격과 난이도에 맞게 적절한 길이로 응답하게 만들려는 방향으로 향하고 있다.
결국 앞으로의 정렬(alignment)에서 중요한 것은 필요한 만큼만 말하게 만드는 것이다. 좋은 LLM은 많은 정보를 쏟아내는 모델이 아니라, 사용자가 묻는 범위 안에서 가장 적절한 정보량을 선택할 수 있는 모델이다. 그런 점에서 양의 격률은 오늘날의 LLM을 이해하고 앞으로의 방향을 가늠하게 해주는 중요한 기준이라고 할 수 있다.
참고 논문
[1] Do Chatbot LLMs Talk Too Much? The YapBench Benchmark (arXiv, 2026)
[2] Brevity is the soul of sustainability: Characterizing LLM response lengths (ACL Findings, 2025)
[3] Adaptive Length Bias Mitigation in Reward Models for RLHF (NAACL Findings, 2025)
[4] Disentangling Length from Quality in Direct Preference Optimization (ACL Findings, 2024)
[5] Eliminating Biased Length Reliance of Direct Preference Optimization via Down-Sampled KL Divergence (EMNLP, 2024)
[6] Following Length Constraints in Instructions (EMNLP, 2025)
[7] Post-hoc Reward Calibration: A Case Study on Length Bias (arXiv, 2024)
[8] Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning (arXiv, 2025)
[9] LACONIC: Length-Aware Constrained Reinforcement Learning for LLM (arXiv, 2026)
