LLM
1.강화학습을 품은 LLM

1. 왜 LLM 학습에 RL이 필요해졌는가 LLM은 거대한 말뭉치를 통해 주어진 토큰의 다음 토큰을 예측하는 능력을 극대화하도록 사전 학습된다. 이 과정은 모델에게 폭넓은 세상 지식(world knowledge)과 뛰어난 언어 생성 능력을 심어주지만, 한계도 분명하
2.[LLM과 언어학] Too Much Talker LLM
들어가며 친절함은 왜 때로는 과잉이 되는가 LLM과 대화하다 보면, 종종 지나치게 장황하다는 느낌을 받는다. 분명히 한 문장으로 대답해도 되는 쉬운 질문을 던졌는데, 돌아오는 답은 세 단락이나 된다. 간단한 사실만 확인하고 싶었는데, 모델은 배경 설명을 덧붙이고, 주
3.[LLM과 언어학] LLM은 어떻게 내 '진짜' 의도를 읽어낼까? 화행이론의 관점에서
들어가며 LLM은 왜 우리의 의도를 잘 읽지 못할까 우리는 LLM과 대화하며 종종 기묘한 단절감을 느낀다. 모델이 문장의 단어는 완벽히 이해하는 것 같지만, 정작 내가 왜 그 말을 했는지는 모르는 것처럼 보이기 때문이다. 엔지니어의 관점에서 보면, 이는 모델이 지시 따
4.[LLM과 언어학] LLM이 대화 함축(Implicature)을 어떻게 이해하는가?
들어가며: 함축이란? 인간은 일상적인 대화에서 모든 정보를 명시적으로 발화하지 않는다. 우리는 주어진 맥락을 적극적으로 활용한다. 그리고 행간에 숨겨진 의미를 자연스럽게 추론한다. 언어학의 하위 분야인 '화용론(Pragmatics)'에서는 이를 '함축(Implicat
5.[LLM과 언어학] '세차장 벤치마크'를 LLM이 어려워하는 이유
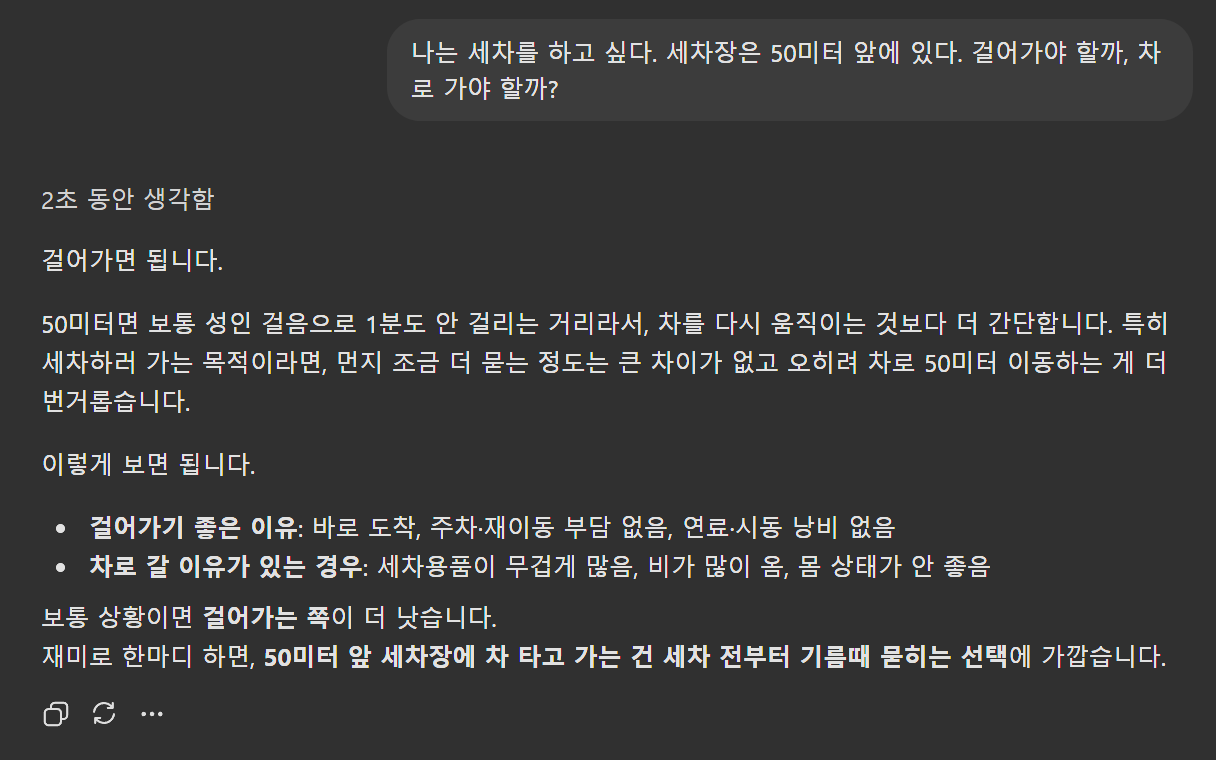
1. '세차장 벤치마크'에 취약한 LLM들 ChatGPT(GPT 5.4, Thinking) 실험 결과 > "나는 세차를 하고 싶다. 세차장은 50미터 앞에 있다. 걸어가야 할까, 차로 가야 할까?" 이 질문에 대해 인간은 너무나도 당연하게 '차를 타고 가야 한