변수
데이터를 저장하기 위해 프로그램에 의해 이름을 할당받은 메모리 공간
데이터를 저장할 수 있는 메모리 공간
이전 자료형 개념에서는 변수를 생성하고 어떠한 값을 넣기만 하는 문장만을 사용하였지만, 사실 한 번 변수를 생성하고 이 변수가 소멸되기 전까지는 그 안에 넣는 값을 변경할 수 있다. 그래서 이름이 ‘변수’이다.
아래는 여러가지 변수 선언 방식이다. 자료형은 잘보이기 위해 int로 통일하였지만 사용하기 위한 자료형으로 바꿔하면 된다. 물론 대입하는 값이 그 자료형에 맞아야한다.
// 여러가지 선언 방식
int i1; // 변수의 선언
i1 = 5; // 변수에 값 대입
int i2 = 10; // 변수의 선언과 값 대입을 동시에 하는 방법
int i3 = -2; // int는 음수 또한 다룰 수 있다.
int i4 = i2; // 다른 변수의 값을 초기값으로 대입하여 초기화 수 있다.
int i5, i6; // 한 번에 여러가지 변수도 선언할 수 있다.
int i7 = 8, i8 = 9; // 여러 변수 선언과 초기화
// 한글로 풀어서 설명
int a = 0; // 정수를 담을 수 있는 a라는 이름을 가진 변수를 선언하면서 그 안에 0을 담으며 초기화한다.
a = 10; // 미리 선언된 a라는 그릇에 기존의 데이터를 치우고 10을 담는다.변수의 이름 생성 규칙
이전에 썼던 글인 변수의 이름을 포함한 식별자 규칙을 참고하면 된다.
자료형을 선언하고 그 뒤에 딸려오는 것이 변수의 이름이다. 위의 예시로는 i1, i2, i3, f1 등이 변수의 이름이 되겠다.
자료형 변수이름;
자료형 변수이름2 = 대입하고싶은값;변수의 유효범위
변수는 선언 위치와 키워드에 따라 해당 변수의 메모리 반환 시기, 초기화 여부, 저장되는 장소 등이 변경된다
변수의 종류
- 지역 변수
- 전역 변수
- 정적 변수
레지스터 변수외부 변수
레지스터와 외부 변수는 설명하지 않기 때문에 생략
메모리 구조
데이터와 스택 영역 외에도 메모리 영역이 있지만 설명하기 위해서 두 영역만 언급했다.
- 데이터 영역
- 전역 변수가 생성되는 구역
- .data ( 초기값이 있는 경우 )
- ex) int a = 2;
- .bss ( 초기값이 없는 경우 )
- ex) int b;
- .rodata ( 읽기 전용 데이터)
- ex) const char* msg = “Hello World”;
- 스택
- 지역 변수가 생성되는 구역
- 함수와 관련이 많음
- 자신이 돌아갈 주소를 저장
- 인자를 넘기는 용도로도 사용
- 함수 내부에서 임시적으로 사용하는 변수들이 있는 공간
- 함수 호출이 끝나면 공간을 다시 반환
지역 변수
- 사용할 중괄호 내부에서 선언
- 중괄호 내에서만 사용할 수 있음
- 초기화를 하지 않으면 쓰레기 값 저장
- 메모리 생성 시점 : 중괄호 내부 초기화
- 메모리 소멸 시점 : 중괄호 탈출
#include <iostream>
using namespace std;
// func의 함수는 main보다 먼저 정의되어 있지만,
// '호출' 자체는 main 안에서 이루어지고 main-for문 후 func 이기 때문에 for 문보다 늦게 출력됨
void func()
{
int a = 20;
cout << "func : " << a << endl; // func의 a 변수 값 출력
}
int main()
{
int a = 0;
for (int i = 0; i < 3; i++) // i도 for문의 지역변수
{
int a = 20; // for 문 내에서 쓰이는 a 지역변수, main의 a랑 충돌하지 않음
cout << "for : " << a << endl; // for의 a 변수 값 출력
}
func();
cout << "main : " << a << endl; // main의 a 변수 값 출력
}
// 출력 결과
// for : 20 // for 문은 중괄호 내부를 반복하는 기능이고 3번 반복하도록 해서 결과가 3번 나옴
// for : 20
// for : 20
// func : 20
// main : 0for 문이라는 배우지 않는 개념이 나오긴하지만 초점을 맞춰야하는 곳은 a라는 변수의 선언 부분 3곳이다. main, for, func의 중괄호에서 각각의 변수가 다른 이름의 변수처럼 간주되어 실행되는 모습을 보면된다. 이 각각의 지역변수 a는 닫는 중괄호를 만나면 메모리에서 반환되어 사라진다고 보면된다.
전역 변수
- 모든 중괄호의 외부에서 선언
- 어느 지역에서든 참조해서 사용할 수 있음
- 초기화를 하지 않으면 자동으로 0으로 초기화
- 메모리 생성 시점 : 프로그램 시작
- 메모리 소멸 시점 : 프로그램 종료
#include <iostream>
using namespace std;
// 전역 변수로 선언되는 공간 (모든 함수 브라켓의 바깥 공간)
int a = 20;
// int a = 30; 을 하게 되면 이미 a라는 이름을 가진 변수가 있기 때문에 컴파일 에러가 난다.
void func()
{
cout << "global : " << a << endl; // 전역변수 a 변수 값 출력
}
int main()
{
func();
cout << "global : " << a << endl; // 전역변수의 a 변수 값 출력
int a = 0;
cout << "main : " << a << endl; // main의 a 변수 값 출력
}
// 출력 결과
// global : 20
// global : 20
// main : 0main 함수를 유심히 보아야한다. main 함수 내부에서 a를 ‘선언’하지 않았지만 출력문에 a를 이용하고 있다. 이는 전역변수가 미리 선언되어 있기 때문에 가능한 일이고, 이후 main의 출력문은 지역변수 a가 생성되었기 때문에 그 지역변수를 이용한다. 그래서 동일하게 main 함수에서 a를 호출해서 사용했지만 서로 다른 변수인 것이다.
정적 변수
- 자료형 앞에 static 키워드로 정의
- 초기화를 하지 않아도 자동으로 0으로 초기화
- 중괄호 내에서 선언되어도 초기화는 한 번만 실행
- 메모리 생성 시점 : 중괄호 내부
- 메모리 소멸 시점 : 프로그램 종료
#include <iostream>
using namespace std;
void func()
{
static int a = 0; // func 함수의 지역 정적 변수 a
a++; // func 함수의 a 변수 값 1 증가
cout << a << endl;
}
int main()
{
static int a = 0; // main 함수의 지역 정적 변수 a
a++; // main 함수의 a 변수 값 1 증가
cout << a << endl;
func();
func();
}
// 출력결과
// 1
// 1
// 2 // func의 첫 문장에 a = 0이라 써있지만 초기화는 한 번만 일어나므로
// // 0+1 = 1이 아닌 1+1 = 2가 된다.const
한 번 정해지면 절대 바뀌지 않을 값들을 지정하는 ‘키워드’
- 이 키워드를 사용하면 초기값을 반드시 지정해야함
- 변하지 않는 값이기 때문에 변수가 아니고 상수임
- 보통 const 상수의 이름은 상수인 것을 알게끔 다 대문자로 사용
- 하드 코딩 대신 사용하기에 적절함 총 목숨의 갯수를 지정할 때, int life = 3;이 아닌 총 목숨을 뜻하는 상수를 하나 생성하여 이를 대입하는 방식
const int TOTAL_LIFE = 3; int currentLife = TOTAL_LIFE; // 프로그램 어딘가에서 플레이어가 사망 시 if (canRestart) { currentLife = TOTAL_LIFE; restart(); } //와 비슷하게 TOTAL_LIFE의 값이 여러곳에서 사용되고 있다면 변경할 때 수월함 - 하드 코딩이 구조적으로 변경되어야할 때, const를 사용하면 좋음
#include <iostream>
using namespace std;
const int A = 20;
// const int B; // 초기값을 주지 않았기 때문에 컴파일 에러
int main()
{
// const int C; // 초기값을 주지 않았기 때문에 컴파일 에러
cout << A << endl; // 상수 A의 값 20을 출력
}
// 출력결과
// 20값 잘림
위에 표에 적혀있듯이 각각의 자료형이 저장할 수 있는 범위가 있다. 이 범위를 벗어나는 연산을 하게 되면 그 값을 온전히 저장하지 못한다. 만약 8bit unsigned 정수 자료형에서 1111 1111(2) = 255가 최대값이 되지만 1을 더한다면 자리 올림으로 인해서 1 0000 0000(2) = 256 가 되어야한다. 그렇지만 맨 처음 1비트를 현재 자료형 8비트에서는 저장할 수 있는 공간이 없으므로 컴퓨터는 이 값을 버리게 된다. 그럼 남아있는 값은 0000 0000(2)가 되어 0이 되어버리는 현상이다. 현재 버려질 자리 올림 값을 저장하기 위해서 9bit 이상의 자료형에 저장해야하는데 컴퓨터는 8비트씩 처리를 하니 최소 16bit의 자료형을 사용하면 되겠다.
값 잘림 현상이라는 한글로 이해하기 좋은 말도 있지만 보통 사용하는 단어는 오버플로우다. 넘쳐흐른다는 말이니, 자리 올림(carry)된 최상위 비트 1이 넘쳐흘러 저장할 곳이 없어 버려졌다는 느낌으로 받아들이면 이해하기 수월하다. over의 반댓말로 under를 사용해 underflow의 개념도 있다. 최소값에서 더 작은 값을 표현하지 못하여 나타나는 현상이다.
오버플로우
메모리에 표현 범위를 초과하는 수의 값을 저장할 때 발생
언더플로우
메모리에 표현 범위보다 작은 수의 값을 저장할 때 발생
#include <iostream>
using namespace std;
int main()
{
cout << CHAR_MIN << " char " << CHAR_MAX << endl;
cout << SHRT_MIN << " short " << SHRT_MAX << endl;
cout << INT_MIN << " int " << INT_MAX << endl;
}
// 출력결과
// -128 char 127
// -32768 short 32767
// -2147483648 int 2147483647#include <iostream>
using namespace std;
int main()
{
cout << "char, 8bit\n";
char c = CHAR_MIN;
cout << dec << "Before - 1 : " << int(c) << "\t\t" << bitset<8>(c) << "\n";
c = c - 1;
cout << dec << "After - 1 : " << int(c) << "\t\t" << bitset<8>(c) << "\n\n";
c = CHAR_MAX;
cout << dec << "Before + 1 : " << int(c) << "\t\t" << bitset<8>(c) << "\n";
c = c + 1;
cout << dec << "After + 1 : " << int(c) << "\t\t" << bitset<8>(c) << "\n\n";
cout << "short, 16bit\n";
short s = SHRT_MIN;
cout << dec << "Before - 1 : " << s << "\t\t" << bitset<16>(s) << "\n";
s = s - 1;
cout << dec << "After - 1 : " << s << "\t\t" << bitset<16>(s) << "\n\n";
s = SHRT_MAX;
cout << dec << "Before + 1 : " << s << "\t\t" << bitset<16>(s) << "\n";
s = s + 1;
cout << dec << "After + 1 : " << s << "\t\t" << bitset<16>(s) << "\n\n";
cout << "int, 32bit\n";
int i = INT_MIN;
cout << dec << "Before - 1 : " << i << "\t" << bitset<32>(i) << "\n";
i = i - 1;
cout << dec << "After - 1 : " << i << "\t\t" << bitset<32>(i) << "\n\n";
i = INT_MAX;
cout << dec << "Before + 1 : " << i << "\t\t" << bitset<32>(i) << "\n";
i = i + 1;
cout << dec << "After + 1 : " << i << "\t" << bitset<32>(i) << "\n\n";
}
/* 출력결과
char, 8bit
Before - 1 : -128 10000000
After - 1 : 127 01111111
Before + 1 : 127 01111111
After + 1 : -128 10000000
short, 16bit
Before - 1 : -32768 1000000000000000
After - 1 : 32767 0111111111111111
Before + 1 : 32767 0111111111111111
After + 1 : -32768 1000000000000000
int, 32bit
Before - 1 : -2147483648 10000000000000000000000000000000
After - 1 : 2147483647 01111111111111111111111111111111
*/#include <iostream>
using namespace std;
int main()
{
char c = CHAR_MIN;
char d = CHAR_MIN;
char e = c + d;
cout << " " << bitset<8>(c) << "\n";
cout << "+ " << bitset<8>(d) << "\n";
cout << "= " << bitset<8>(e) << "\n";
}
// 출력결과
// 10000000
// + 10000000
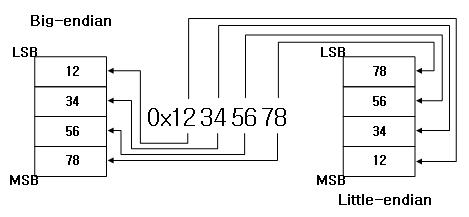
// = 00000000Endian
데이터를 메모리에 저장할 때, 각 자릿수를 어느 순서에 따라 저장할 것인가가 두 가지로 나뉜다. 보통은 x86 아키텍쳐에서는 리틀 엔디안을 사용하고, ARM 프로세서들은 빅 엔디안을 사용한다고 했는데, 내가 사용하고 있는 M1 프로세서에서 엔디안 테스트 코드를 짜보았을 때 리틀 엔디안으로 나왔다. M1은 ARM 기반이기 때문에 틀린 내용인가 했는데, 검색해보니 애플 개발자 사이트에서도 Apple silicon 또한 리틀 엔디안이라는 말이 나와있다. 또한 무조건 ARM이라해서 빅 엔디안을 사용하는 것이 아니고 제조사가 엔디안을 선택하여 제조한다고 한다.
Both Apple silicon and Intel-based Mac computers use the little-endian format for data, so you don’t need to make endian conversions in your code. However, continue to minimize the need for endian conversions in custom data formats that you create.
리틀 엔디언
작은 단위의 바이트가 앞에 오는 방식
- 하위 바이트만 사용할 때 별도의 계산이 필요 없어 캐스팅에 유리
- 가산기 설계가 좀 더 단순해지지만 여러 개의 바이트를 동시에 계산하는 오늘날에는 별 차이 없음
빅 엔디언
사람이 숫자를 쓰는 방법과 같이 큰 단위의 바이트가 앞에 오는 방식
- 사람이 숫자를 읽고 쓰는 방법과 같아 디버깅이 편리
- 네트워크 데이터 전송에서 사용
#include <iostream>
using namespace std;
int main()
{
cout << hex; // cout으로 출력되는 값들을 16진수로 나타내겠다.
int a = 0x01020304;
// char 옆에 *는 포인터 자료형을 나타내고 나중에 배운다.
char* a1 = (char*)&a; // a의 주소 중 첫번째 바이트의 주소를 char 단위로 가져옴
char* a2 = (char*)&a + 1; // a의 주소 중 첫번째 바이트의 주소를 char 단위로 가져오고 char 단위만큼 하나 건너뜀
char* a3 = (char*)&a + 2; // a의 주소 중 첫번째 바이트의 주소를 char 단위로 가져오고 char 단위만큼 둘 건너뜀
char* a4 = (char*)&a + 3; // a의 주소 중 첫번째 바이트의 주소를 char 단위로 가져오고 char 단위만큼 셋 건너뜀
cout << *a1 << *a2 << *a3 << *a4 << endl; // 그 주소 안에 있는 값들을 낮은 주소에 있는 값부터 하나씩 출력한다.
}
// 출력결과
// x04x03x02x01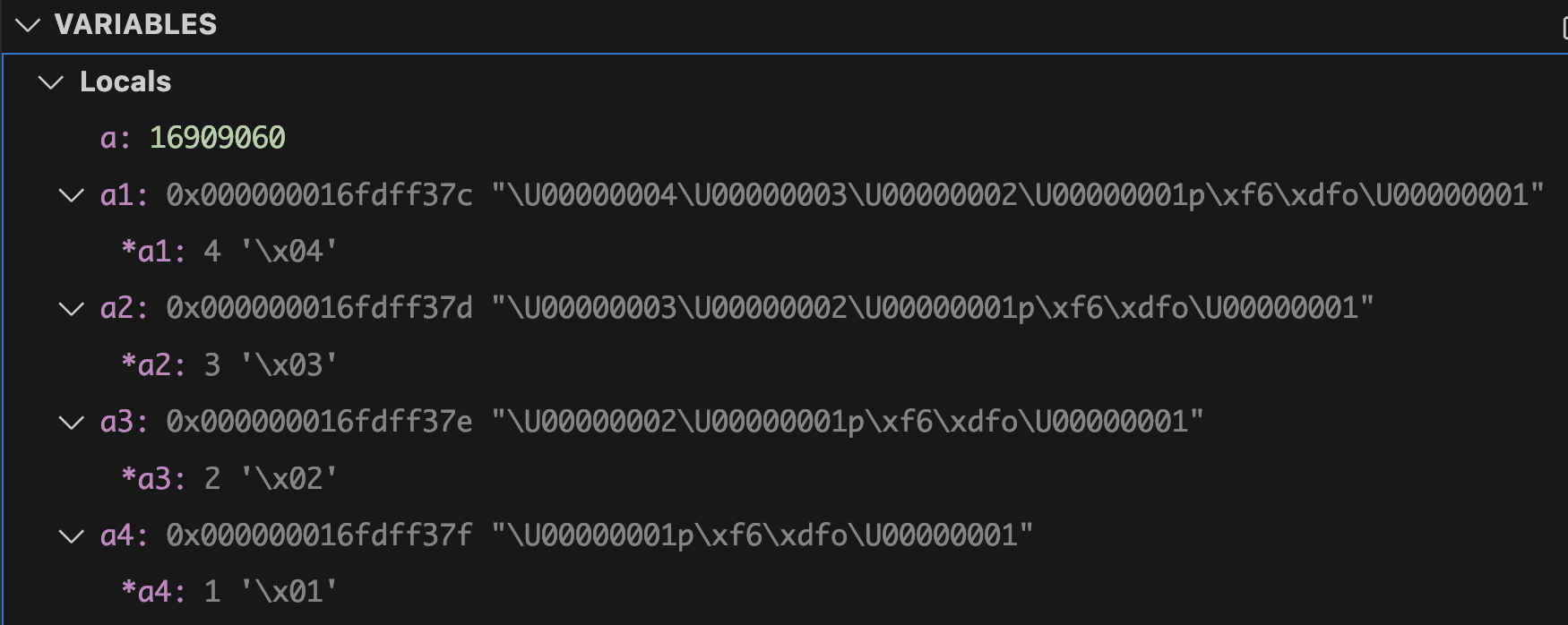
디버깅 화면인 맨 아래 사진에 VARIABLES를 보면 a1은 0x000000016fdff37c 이라는 주소를 가르키고 있는데 이는 a 변수가 할당되어 있는 주소다. 낮은 주소부터 하나씩 들어있는 값이 x04, x03, x02, x01의 값인 것을 볼 수 있다.
참고한 글
