.png)
안녕하세요. 김용성입니다.
다들 컴퓨터를 다루다보면 특정한 상황에서 '뷁','갋' 막 이런 단어들을 마주칠 때가 있을겁니다. 다들 이 부분에 대해 인코딩 문제인 것은 알고 있지만 명확히 개념을 알고 넘어가는 경우는 드물거예요.
오늘은 문자열 인코딩과 탄생배경에 대해 알아보도록 하겠습니다.
문자표의 등장
우리가 사용하는 컴퓨터는 문자열을 표현하는 용도로보다는 수학적인 계산을 처리하기 위한 용도로 탄생되었습니다.
하지만 점차 발전하다보니 문자열을 출력장치를 통해 표현해주어야하는 일이 번번히 발생하였고, 처음에는 이러한 상황을 해결하기 위해 정형화된 규칙 없이 컴퓨터에
'음..1이면 A을 출력해줘'
이런식으로 나타내었습니다.
이처럼 정해진 규칙이 없다면 아무래도 컴퓨터를 사용하는 프로그래머들이 많아질수록 호환성 측면에서 큰 문제가 발생하였겠죠?
그로 인해 국제 표준이 나오게 되었고, 숫자와 문자를 매칭시키는 지금도 아주 유명한 ASCII CODE 표가 등장하게 되었습니다. 아주 유명한 표이죠?
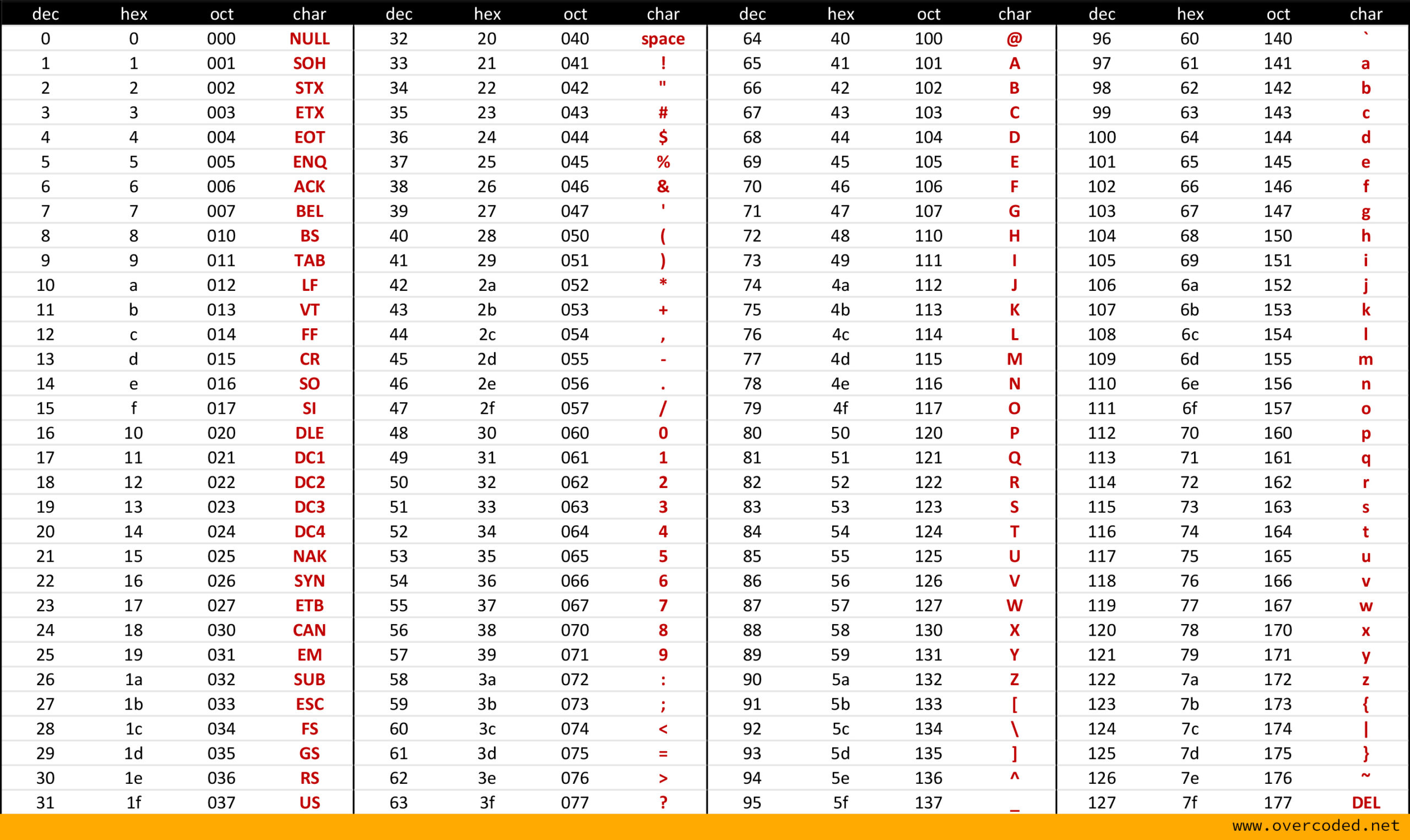
(ASCII-code 표)
ASCII 코드표의 문제점
ASCII는 American Standard Code for Information Interchange의 줄임말입니다. 이름에서 알 수 있듯, 당시 이 문자표가 만들어질 시점에는 영어권 소수의 사람들이 컴퓨터를 다뤘던 터라 American 위주로 구성된 문자표이고, 이로인해 영어 밖에는 표현할 수가 없다는 뚜렷한 단점이 있습니다.
컴퓨터가 널리 보급되고 여러 나라사람들이 컴퓨터를 사용하게 되면서 이러한 ASCII code표의 한계점이 명확해졌고, 초창기 문자표가 없었던 시절과 똑같은 문제점이 다시끔 피어오르기 시작했습니다.
유니코드의 등장
다양한 나라의 문자표를 만들 시점엔 이미 컴퓨터 프로그래머들이 많아졌고, ASCII 코드를 만들 때에 비해 훨씬 생태계가 커져버렸습니다. 그러다보니 중구난방으로 많은 문자표가 탄생하게 되었고 호환성 측면에서 엄청난 이슈가 생겨나기 시작했죠. 이러한 부분에 대해 불편함을 느낀 사람들의 노력으로 인해 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이 등장하게 되었고 이를 우리는 유니코드(Unicode)라고 부릅니다.
현재 이렇게 생성된 유니코드는 컴퓨터 소프트웨어의 국제화와 지역화에 널리 사용되게 되었으며, 비교적 최근의 기술인 XML, 자바, 그리고 최신 운영 체제 등에서도 지원되는 표준입니다.
인코딩의 등장
그러나 유니코드에도 문제점이 있습니다. 국가별 언어 별로 할당되는 바이트수가 다르기 때문에 이를 처리하는 컴퓨터에 큰 혼란을 줄 수 있다는 점인데요.
이러한 이유로 인해 컴퓨터의 입장에서 코드를 읽을 때 앞에 어떠한 표시를 해줌으로써 상황에 따라 컴퓨터가 1바이트를 읽어 표현할 것인지, 2바이트를 읽어 표현할 것인지에 대해 명시를 해주는 것들이 생겨났습니다. 우리는 이것을 인코딩이라고 합니다.
즉, 유니코드만으로 파일을 저장할 때는 혼란을 야기하니 유니코드 앞에 어떠한 표를 달아서 저장하는 것을 인코딩이라고 하는 것입니다.

이러한 인코딩은 여러가지 종류가 있는데요. 여러분들이 아실만한 'UTF-8','UTF-16' 등이 있습니다.
목적은 같지만 각기 다른 약속들인데요. 제가 위해서 말씀드린 내용들로 미루어 짐작했을 때, 인코딩 에러가 어떠한 것인지 살짝 감이오시지 않나요?
UTF-8이라고 저장을 해놓은 파일 혹은 프로그램을, UTF-16로 읽을 경우에는 지정된 약속에 어긋나는 행동이기 때문에 여기서 인코딩 에러가 발생하게 되는 것입니다.
참고로 많은 분들이 'UTF-8'은 유니코드 아니야? 하는데 저는 그것보다는 유니코드를 인코딩하는 방법이라고 말하는 것이 더 정확하다고 생각합니다.
EUC-KR
흔히 우리나라 사람들이 겪게 되는 인코딩 문제는 EUC-KR과 UTF-8로 인한 것들이 있습니다.
EUC-KR은 한글 지원을 위해 유닉스 계열에서 나온 완성형 코드 조합입니다.
완성형 코드란 완성 된 문자 하나하나마다 코드 번호를 부여한 것을 말하는데요. EUC-KR은 ANSI를 한국에서 확장한 것으로 외국에서는 지원이 안 될 가능성이 높습니다.
아무튼 각자의 쓰임새가 있고, 한글을 표현하기 위한 방식으로 사용할 수 있지만, 당연하게도 UTF-8로 인코딩 된 문서를 EUC-KR 방식으로 인코딩 한다면 한글 깨짐 문제가 발생하겠죠? 제가 위에서 말씀드린 '뷁' 과 같은 현상도 마찬가지로 이러한 원인일 가능성이 아주 큽니다.
HTML을 작성할 때, 한글을 표현하기 위해 대표적으로 사용되는 것도 EUC-KR과 UTF-8입니다.
<meta charset="UTF-8">(이제 이 코드의 의미를 아시겠나요??)
알아두셔야 할 것은 EUC-KR은 완성형, UTF-8은 조합형이라는 것입니다. 따라서 EUC-KR은 문자표에 존재하지 않는 문자라면 폰트가 깨지게 되고, UTF-8은 조합할 수 있는 모든 문자를 나타낼 수가 있습니다.
마무리
오늘은 문자열 인코딩의 개념과 탄생 배경에 대해 알아보았는데요. 많은 도움이 되면 좋겠습니다.
읽어주셔서 정말 감사합니다:)
