C++
공부한 키워드
- 레퍼런스
- 포인터 배열
- 배열 포인터
- sstream
- istringstream
- getline
- C-string, char void형변환
- cpu, l1, l2, l3캐시, 레지스터
실습문제
도전 실습
#include <iostream>
using namespace std;
void calculator(int calType, int a, int b)
{
if (calType == 1) // 덧셈
{
cout << a << " + " << b << " = " << a + b << "\n";
}
else if (calType == 2) // 뺄셈
{
cout << a << " - " << b << " = " << a - b << "\n";
}
else if (calType == 3) // 곱셈
{
cout << a << " * " << b << " = " << a * b << "\n";
}
else if (calType == 4) // 나눗셈
{
cout << a << " / " << b << " = " << a / b << "\n";
}
else // 그 이외의 숫자가 들어오면
{
cout << "잘못된 입력입니다." << "\n";
}
}
int main()
{
while (true)
{
cout << "사칙 연산 모드를 설정해주세요." << "\n";
cout << "1) 덧셈" << "\n";
cout << "2) 뺄셈" << "\n";
cout << "3) 곱셈" << "\n";
cout << "4) 나눗셈" << "\n";
cout << "-1) 나가기" << "\n";
int state = 0, inp1 = 0, inp2 = 0;
// 계산 뭐할지 입력
cout << "원하는 계산 입력해주세요 : ";
cin >> state;
if (state == -1)
{
break;
}
// 두 수 입력
cout << "첫 번째 수 입력 : ";
cin >> inp1;
cout << "두 번째 수 입력 : ";
cin >> inp2;
// 계산기 호출
calculator(state, inp1, inp2);
cout << endl;
}
return 0;
}도전x도전 실습
-
첫번째 코드
-
모든 분기를 만들었다. 코드더럽
-
괄호에 따른 연산 우선순위를 적용하려면 스택을 사용해야 하기때문에 구조를 모두 바꿔야한다.
괄호추가 1차
- 내 풀이
- 5 + 7 (87) 처럼 숫자와 괄호가 붙어있는 경우는 제대로 판별을 못해서 숫자 + 괄호가 붙어있는 부분은 를 붙여준다던지 하는 식으로 계산해야 할것 같다.
코드 작성하면서 느낀점
- sstream, istringstream, getline조합으로 문자열 한줄을 받고 공백을 제거하면서 배열형태로 받을 수 있다.
istringstream ss(inp);
vector<string> tokens;
string token;
while (ss >> token)
{
tokens.push_back(token);
}- goto 문법
- goto 이동할곳;
- 이동할곳 :
- 실행할내용;
게임 개발자를 위한 C++ 문법
1-4. 포인터와 레퍼런스
값 대신 주소값 담기
- 변수의 크기가 커지면 많은 복사비용이 필요하다 그런 경우에 값 전체를 복사하는것이 아니라 변수의 시작주소를 알려준다.
- 주소값은 고유하므로 이를 알고 있다면 실제 변수의 위치에 접근할 수 있습니다.
포인터 변수의 구성 요소
- 주소값에 접근해서 값을 수정하려고 하니 변수의 크기가 모두 다르다 보니 끝도 알아야한다.
- 포인터에는 변수의 크기 정보를 파악할 수 있는 타입 정보가 함께 필요하다.
- C++에서는 이를 위해 타입 정보를 포함한 포인터 변수를 사용한다.
- int* ptr
포인터 배열과 배열 포인터
-
포인터 배열은 포인터를 원소로 갖는 배열
- int ptrArr[4]; 는 크기가 4이고, 각 원소가 int인 배열
-
배열 포인터는 배열 전체를 가리키는 포인터
- 즉, 단일 변수가 아닌 배열 통째로 가리키는 변수
- 보통 다차원 배열 제어에 사용한다.
int x = 1, y = 2, z = 3;
int* ptrArr[3] = { &x, &y, &z };
int arr[3] = { 10, 20, 30 };
int (*ptr)[3] = &arr;
cout << *ptrArr[0] << endl;
cout << *ptrArr[1] << endl;
cout << *ptrArr[2] << endl;
cout << (*ptr)[0] << endl;
cout << (*ptr)[1] << endl;
cout << (*ptr)[2] << endl;포인터 연산
int arr[4] = {7, 3, 2, 5};
int* ptr = arr;- ptr + 1을 하게되면 ptr이 가리키는 주소에서 한 단위 메모리 주소가 이동 즉 &arr[1]이랑 같음
- (*ptr) + 1을 하면 ptr이 가리키는 7값에서 1을 더해서 8이 출력
- *(ptr+1)은 ptr[1]과 동일
레퍼런스
- 포인터를 사용하면 주소값을 직접 다루어야 하므로 복잡 그래서 C++에서는 변수에 또다른 이름을 부여하는 레퍼런스문법을 도입
- 일반 변수와 거의 동일하게 사용가능 + 내부적으로 해당 변수를 직접 가리켜주는 역할
- int& ref = var; 처럼 사용가능 ref값이 변하면 var값도 변경
- 레퍼런스는 선언과 동시에 초기화 해야됨
포인터와 레퍼런스의 차이
- 포인터는 선언 후, 나중에 = 연산자를 통해 가리킬 대상을 변경할 수 있다.
- 레퍼런스는 선언과 동시에 초기화 해야한다. 초기화 이후에는 다른 대상에게 재연결할 수 없다.
- 이는 레퍼런스는 항상 다른 변수와 연결되어있기 때문에 NULL이라는게 없다.
- 반면 포인터는 유효대상이 없음을 나타내기 위해 NULL이나 nullptr을 가질 수 있다.
- 간접 참조 문법의 유무
- 포인터는 주소값을 담으므로 접근할 때는 *연산을 사용하고 주소를 가져올 때는 &연산을 사용한다.
- 레퍼런스는 변수 자체의 별명이므로 일반 변수와 연산하는 방법이 동일하다.
상수 레퍼런스
- 레퍼런스에 const를 걸어서 읽기전용으로 사용할수도 있다.
- 값을 복사하지 않고 기존 변수를 보호할 수 있다.
숙제 1
#include <iostream>
using namespace std;
int main()
{
int value = 25;
int* ptr = &value;
cout << "포인터를 통해 접근한 value의 값 : " << *ptr;
cout << endl;
return 0;
}숙제2
#include <iostream>
using namespace std;
int main()
{
int score = 80;
int& score_ref = score;
cout << "레퍼런스를 통해 접근한 score의 값 : " << score;
cout << endl;
score_ref = 95;
cout << "레퍼런스를 통해 접근한 score의 값 : " << score;
cout << endl;
return 0;
}궁금한거
왜 char는 cout이랑 사용할때 void로 형변환을 해야할까?
C와 C++에서 char*은 문자열의 시작주소로 자주 쓰인다. cout은 char*를 만나면 자동으로 C-string(문자열)로 해석해서, 포인터가 가리키는 주소가 아니라 그 주소부터 시작하는 문자열을 출력한다.
- C-string이란 C스타일 문자열을 말함 '\0'널 문자로 끝나는 char배열
배열의 매개변수로 & (레퍼런스)를 쓰는데 원본에 접근하지 않더라도 이게 무조건 쓰는게 좋은거 아닌가?
- 무조건은 아니다
- 작은 타입 (int, double, char, 포인터 등) 은 복사 비용이 참조 비용보다 작거나 비슷하다.
즉, 그래서
- 원본 수정이 필요없고 + 작은타입이면 -> 값 전달 방식 -> 복사비용이 적고 간단함
- 원본 수정이 필요없고 + 큰 타입이면 -> const 참조 (const string& s) -> 복사 비용 절약 + 수정 방지
- 원본 수정이 필요한 모든 타입들은 -> 참조(int& x, string& s) -> 원본에 직접 접근
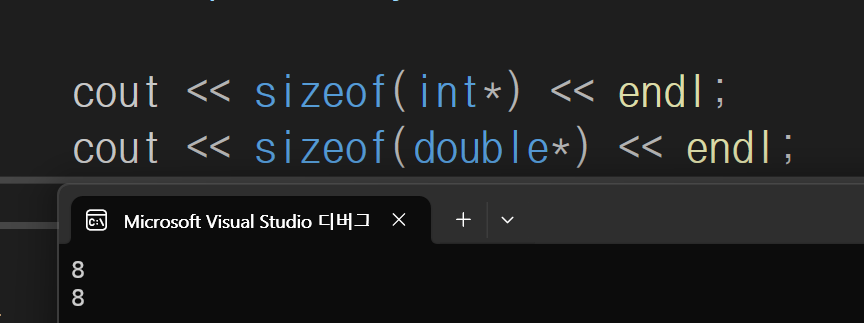
포인터의 크기는 왜 8바이트인가?
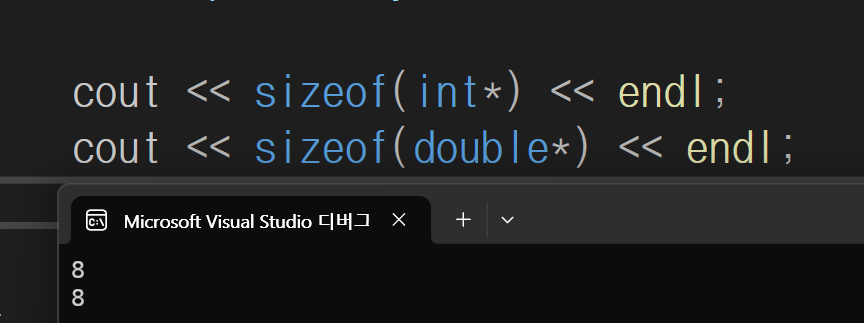
64비트 cpu에서 레지스터가 64비트 이므로 한번에 64비트의 주소 처리가능 -> 그래서 포인터는 8바이트
- 레지스터란?
- CPU내부에 있는 초고속 임시 저장 공간
- CPU가 명령어를 실행하는데 필요한 데이터를 바로바로 읽고 쓰기위한 장치
- 레지스터 -> 캐시메모리(L1,L2,L3) -> RAM -> SSD 속도 순서
AMD CPU의 x3D모델들은 L3캐시가 높아서 게임에서 성능이 좋다는데 왜 그런건지?
- 내 예상 : 로딩에 필요한 데이터같은것들을 캐시에 많이 적재해 둘수 있어서?
- 답변 : 캐시 메모리가 크다는것은 낮은속도의 RAM에 덜 왕복해도 된다는것과 비슷하다.
게임에서는 AI상태, 물리, 맵/타일 정보, 엔티티 리스트, 경로 탐색 같은 자주 참조되는 데이터들이 많은데 이게 L3 캐시에 많이 상주하면 RAM까지 가지않고 레이턴시가 낮아져서 프레임드랍이 많이 개선된다 특히 (1% low)- 게임 루프에서 계속 재사용되는 데이터가 L3 안에 머무를 확률이 훨씬 높아진다 -> 캐시 적중률이 올라간다.
- 왜 특히 게임에서 성능이 좋은가?
- 게임은 큰 데이터를 조금씩 자주 읽는 패턴이 많다.
- 이런 패턴이 L3캐시에 잘 맞다.
- 캐시 적중률이 높으므로 RAM까지 내려가서 데이터를 가져올 필요가 없다.
- 캐시 적중률이 높으므로 캐시 교체 정책에 의해서 캐시 데이터에서 잘 안내려감
배열 포인터 - 이 코드는 왜 에러?
int arr[3] = { 10, 20, 30 };
int (*ptr)[4] = &arr;배열 포인터 타입이 배열 크기까지 타입에 포함되기 때문이다.
int arr[3] // 타입 int[3]
int(ptr)[4]; // 타입 int()[4];
&arr의 타입은 int(*)[3] 그러므로 이 코드는 서로 타입이 다르므로 실행 불가하다.
