AlexNet : ImageNet Classification with Deep Convolutional Neural Networks
Abstract
120만개의 고화질 데이터를 이미지넷 상에서 1000개의 클래스로 분류하기 위해 CNN 을 학습을 시켰다. 그 결과 TOP 1, TOP 5 error rate가 37.5%, 17.0%가 나왔다. (지금 생각해보면 진짜 못만들었네)
아무튼 그 당시에는 굉장히 좋은 성과라고 할 수 있다. 6천만 개의 매개 변수와 65만 개의 뉴런을 가진 신경망은 5개의 컨볼루션 레이어로 구성되며, 그 중 일부는 최대 풀링 레이어, 그리고 최종 1000way 소프트맥스를 가진 3개의 완전 연결 레이어로 구성된다.
훈련 속도를 높이기 위해 non-saturating neurons과 GPU를 사용했고 fully-connected layers에서 overfitting을 줄이기 위해 drop-out의 정규화 방법까지 사용해 큰 효과를 얻었다고 한다.
The Dataset
22,000개 범주로 구성되어 있고 1500만개의 고해상도 이미지가 포함되어있는 data set입니다.
ILSVRC 대회는 ImageNet dataset의 subset을 이용하는데, 각 범주당 1000개의 이미지가 포함되어 있는 1000개 범주를 이용합니다. 따라서, 대략 120만개의 training 이미지와 50,000개의 validation 이미지, 150,000개의 testing 이미지로 구성되어있습니다.
ImageNet은 이미지의 해상도가 다양한 반면, AlexNet은 일정한 입력 차원을 요구한다. 따라서, 우리는 이미지를 256 × 256의 고정 해상도로 다운샘플링했다. 직사각형 이미지가 주어졌을 때, 먼저 짧은 쪽이 256 길이가 되도록 이미지의 크기를 조정한 다음, 결과 이미지에서 중앙 256x256 패치를 잘라냈다.
The Architecture
AlexNet은 8개의 층으로 구성이 되어 있는데, 처음 5개는 convolution 층이고 3개는 fully connected layer이다. 마지막 fully connected layer의 output은 1000개의 클래스 label을 분류하도록 되어 있다.
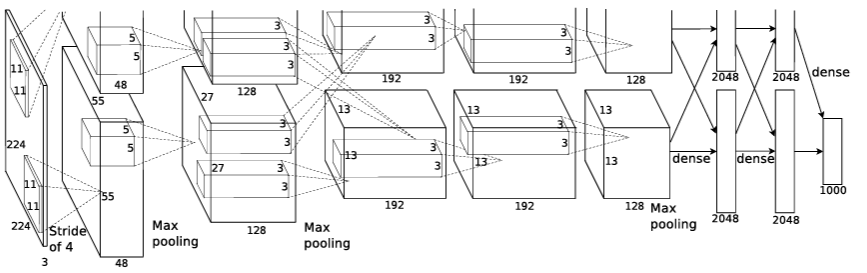
- Input Image (224,224,3)
- Conv1
- 96 kernel (filter 의 개수가 96개이다.) 11by 11의 filter, stride=4,padding=0
- Input : 224,224,3
- Output: 55,55,96
input=torch.Tensor(1,3,224,224)
conv1=nn.Conv2d(3,96,11,stride=4,padding=0)
print(conv1.shape)
#torch.Size([1,96,54,54])
#Output Size 계산 하듯이 계산하면 wide가 54 가 나오는데 의문임- MaxPool1
- 3by3 kernel, stride=2
- Input: 55,55,96
- Output: 27,27,96
- Norm1
- normalization layer임
- Conv2
- (5,5,96) kernel 256개, stride=1,padding=2
- Input: 27,27,96
- Output: 27,27,256
- MaxPool2
- 3by3 kernel, stride=2
- Input: 27,27,256
- Output: 13,13,256
- Norm2
- normalization layer임
- Conv3
- (3,3,256) 384개, stride=1, padding=1
- Input: 13,13,256 (stride=1,pading=1이면 그대로 유지)
- Output: 13,13,384
- Conv4
- (3,3,384) 384개, stride=1,padding=1
- Input: 13,13,384 (stride=1,padding=1이면 그대로 유지)
- Output: 13,13,384
- Conv5
- (3,3,384) 256개, stride=1,padding=1
- Input: 13,13,384
- Output: 13,13,256
- MaxPool3
- 3by3 kernel, stride=2
- 13,13,256
- Out: 6,6,256
- FC1
- 6,6,256
- 4096
- FC2
- 4096
- 1000
CNN모델을 만드는 과정에서 입력 데이터의 채널 수와 필터의 채널 수는 같아야 한다.
입력데이터 shape: (C,H,W) (channel,height,width)
Filter shape: (FN,C,FH,FW) 필터의 개수대로 Output channel로 변경됨
Output: (FN,OH,OW)
ReLU
활성화 함수로 RELU 함수를 사용했다. 원문에서는 “these saturating nonlinearities are much slower than the non-saturating nonlinearity” 라는 표현을 썼는데 비선형함수인 tan h, sigmoid가 ReLU 보다 몇배는 느리다고 표현을 했습니다.
CIFAR-10 dataset을 학습시켰을 때, trainig error가 25%까지 도달하는 Epoch가 ReLU는 약 6정도인데 tanh 함수는 훨씬 느리다고 합니다.
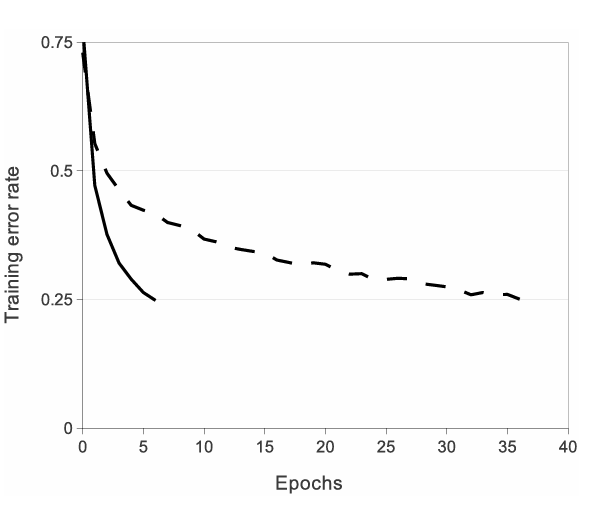
논문 원문에 있는 그림인데 뭔가 조잡함. ㅋㅋ
Training on Multiple GPUs
120만 개의 data를 학습시키기 위해 3gb의 GPU로는 부족하기 때문에, 2개의 GPU로 분할해서 학습시키니, top1 error 1.7%줄고, top5 error가 1.2%줄었고, 학습속도도 굉장히 줄었다. 이를 GPU parallelization이라고 한다.
Local Response Normalization (LRN)
추후 작성 예정입니다
https://colab.research.google.com/drive/1giGtGe-kSntbepAh8AGqRttsPQii9Vmj?usp=sharing
