새로운 딥러닝 모델을 만들기 위해 어떤 방법을 써야할까?
강아지와 고양이를 구분하는 딥러닝 모델을 구축하려고 할 때, 많은 데이터가 필요하다.
그러나 보통 데이터셋이 적음…. → 데이터셋의 크기가 적으면 학습이 잘 안됨
이 때 어떻게 딥러닝 모델을 구축할 수 있을까?
그에 대한 해답!
ImageNet 데이터를 미리 학습해 놓은 딥러닝 모델 (Pre-Trained Model)을 가져와 Fine- Tuning 시키는 방법을 사용한다. 이러한 방법을 Transfer Learning이라고 한다.
Pre-Trained Model은 보통 유명한 것들을 쓰므로 쉽게 WEB에서 가져올 수 있다. Pre-Trained Model을 로드한 후, Fully Connected Layer 앞의 네트워크의 가중치를 가져오고, Fully Connected Layer를 다시 설계하는 방식으로 진행이 된다.
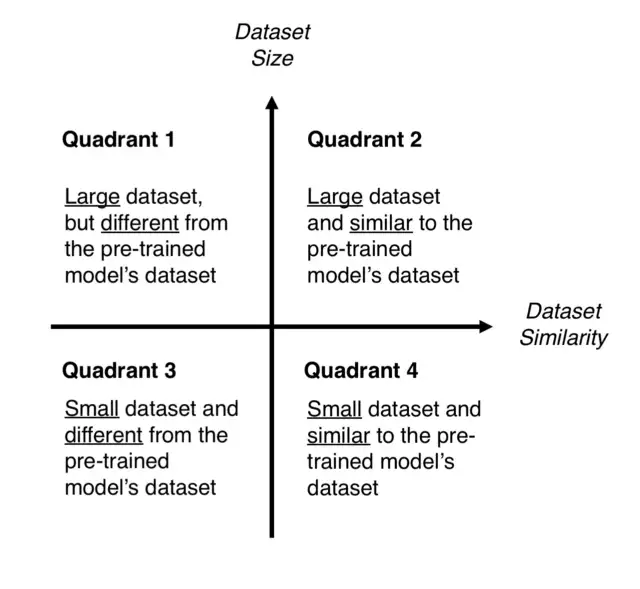
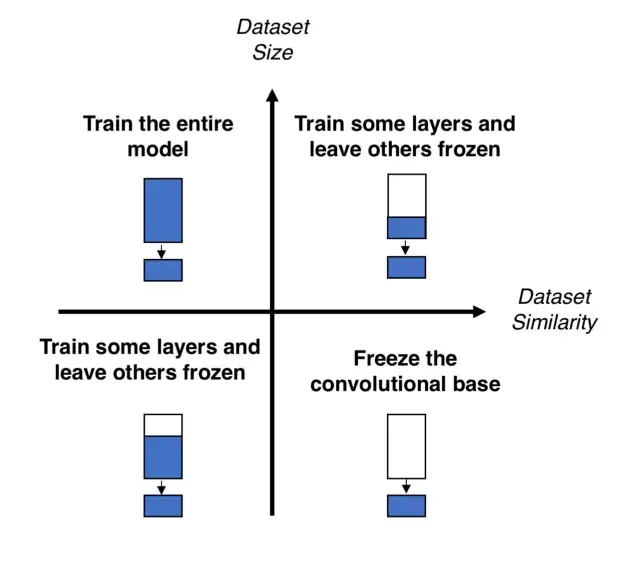
Transfer Learning은 크게 4가지로 구분할 수 있습니다.
- Dataset은 많으나 pre-trained model의 데이터셋과는 다를 때, Dataset이 많기 때문에, 모델을 처음부터 학습시키는 것이 가능합니다. Pre-Trained model의 구조와 가중치를 사용해서 처음부터 학습합니다.
- Dataset도 많고, pre-trained model의 데이터셋과 비슷할 때, 데이터 셋이 크기 때문에 Overfitting은 큰 문제가 되지 않습니다. 데이터셋이 pre-trained와 비슷하기 때문에, training 을 전부 할 필요는 없다. classifier와 CNN구조의 약간만 학습시키면 됩니다.
- Dataset이 적고, pre-trained model과 다를 때, 데이터 셋이 적기 때문에, Overfitting이 생길 가능성이 높다. 고로 Data augmentatiton 방법을 써야한다. 또한 CNN구조도 바꿔야한다.
- Dataset이 적으나, pre-trained model의 데이터셋과 비슷할 때, Transfer Learning에 가장 적합한 유형이라고 할 수 있다. 가장 끝 Fully Connected Layer (Output Layer)를 지우고 pre-trained model을 feature extractor로서 작동시키고, 나온 feature들을 새로운 Classifier로서 학습시키면 된다.
앞선 예를 계속 들자면,
개와 고양이를 분류하는 딥러닝 모델을 만들고자 할 때, Fully Connected Layer를 그대로 사용하고, Output Layer만 디자인하기도 한다. Pre-Trained Model은 우리가 분류하고자 하는 문제인 (강아지 , 고양이)보다 훨씬 큰 문제를 푸는 모델이기 때문에, Output Layer의 Dimension을 수정해야한다.
그 후, 강아지와 고양이 데이터를 가지고 Input으로 학습을 시켜야한다. 일반적으로 Pre-Trained Model의 Fully Connected layer 이전의 Weight는 학습시키지 않는다. 이 때는 Weight를 freezing한다는 표현을 쓰며, 이 것은 Fully Connected Layer 부분의 weight만을 가지고 학습을 진행하는 것이다.
→ 이 과정을 Fine Tuning이라고 한다.
이제 간단한 실습을 해보도록 합시다.!
ResNet18 모델 구조를 활용해 개미와 벌 이미지를 분류해보도록 하겠습니다.
다음 코랩 링크를 참고해주세요!
Pre-Trained 되지 않은 모델을 사용하고 학습을 진행한 결과, 학습시간이 오래걸리고 accuracy가 굉장히 낮다.
그러나, Pre-Trained 된 모델을 활용해 학습을 진행한 결과, 학습시간이 짧고 accuracy가 굉장히 높다.
https://colab.research.google.com/drive/1dtFQfpRX3zXEI6gN5dammuolfJsh9szO#scrollTo=qCvLYBrDF-tj
