관계형 데이터 모델링
이전 프로젝트에서 기획서와 Mock API가 모두 제공이 됐었다.
그것들을 가지고 코드를 작성하는데 문제점이 있었다.
어떻게 배열을 데이터베이스에 넣을 것인가 라는 문제였다.
좀 더 확장하면 어떻게 객체를 데이터베이스에 넣을것인가? 이었다.
이번에 생활코딩에서 데이터 모델링 수업을 들으면서 이 의문이 해결됐다.
내 질문을 DB 관점으로 다시 만들어보자.
그러면 이런 질문이 될 것이다.
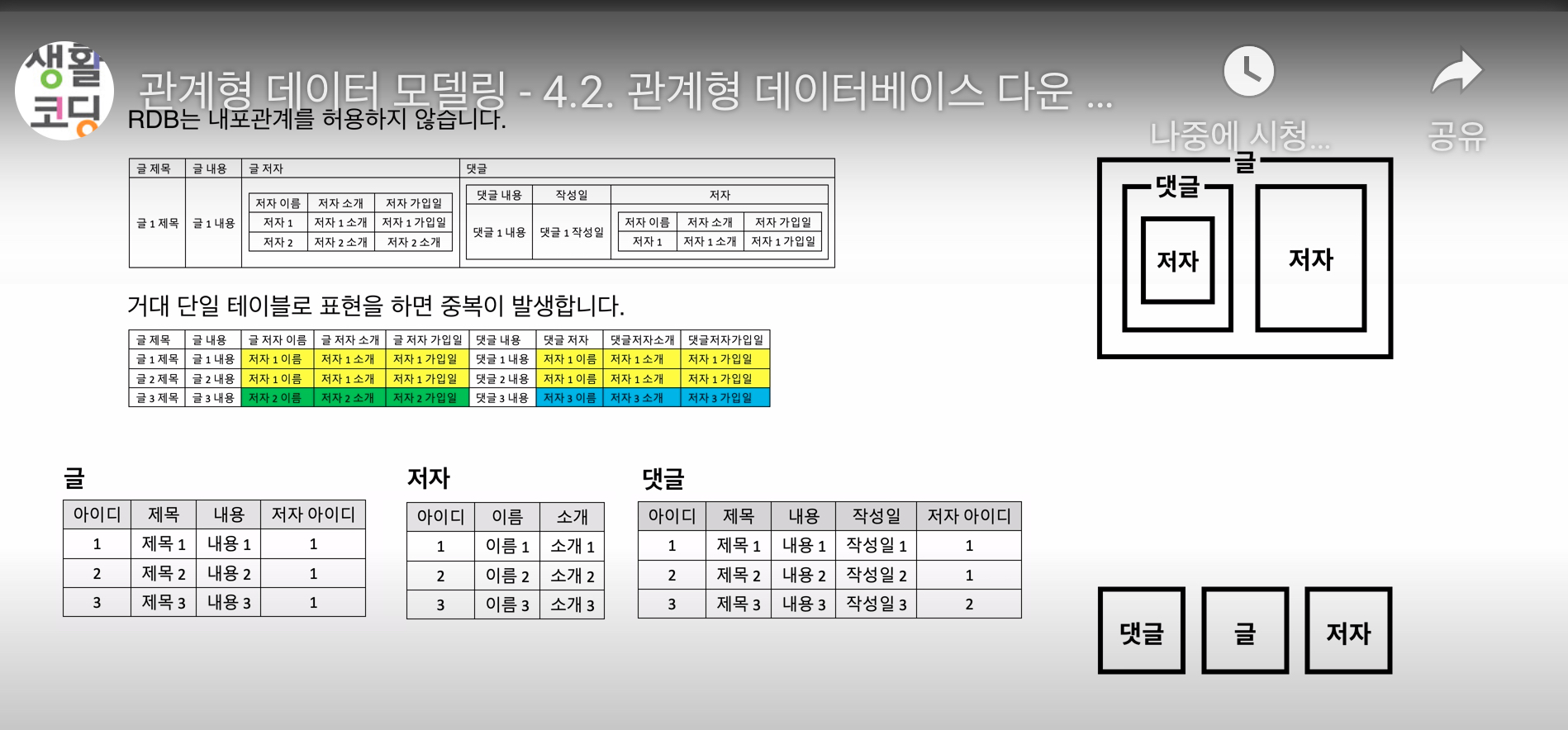
"어떻게 테이블의 컬럼 내에 또 다른 테이블을 넣을 것인가?"
이것을 디비에서는 내포관계라고 한다.
생활코딩에 따르면 RDB는 내포관계를 허용하지 않는다고 한다.
하지만, 하나의 표에 어떻게하면 구겨 넣을 수는 있는데,
그게 내가 이전 프로젝트에서 했던 방법이고
생활코딩에서는 아래그림을 예제로 보여주었다.

생활코딩은 이로인해서 어마어마한 중복이 발생해서 문제가 발생한다고 했는데,
사실은, 이전 프로젝트에서는 각 데이터들에 추가되는 데이터가 중복되지 않았었다.
저 이미지의 예제를 가지고 설명한다면, 글1,2,3의 글 저자의 이름,소개,가입일이 모두 달라서 중복되지 않았었다.
다시 풀어서 말하면, 애초에 내포관계고 뭐고 테이블 1개였였던거다.
Mock API에서 제공했던 JSON 데이터 형식이 상속관계(내포관계)로 나타나져있어서 디비를 만들때 날 헷갈리게 했던거다.
배운점
이번 생활코딩 강의를 들으면서 배운점은 Mock API를 보고 디비를 만들때 (or 클라이언트에서 제공해주는 데이터 형식), 굳이 클라이언트로 response 해주는 데이터 형식이 내 디비와 1:1 대응될 필요가 없다는 것이었다.
데이터 형식을 보고 디비를 만드는 게 아니라,
이 데이터들이 중복되는 데이터를 가지고 있는지를 생각하고 만들었어야 했다.
데이터 모델링, 그래서 어떻게 하는 거?
데이터 모델링을 하기 위해서 총 4가지로 분류한 공정과정이 있다.
- 업무파악
- 개념적 데이터 모델링
- 논리적 데이터 모델링
- 물리적 데이터 모델링
1. 업무파악
업무파악은 기획서를 만드는 것이다.
User Interface 담당자와 디비 담당자가 같이 기획할 것을 UI로 간단하게 만들어보는것이다.
생활코딩에서 만든 예제를 보면, 이게 어떤 말인지 알수있다.
2. 개념적 데이터 모델링
기획서를 만들고 나면 Entity를 생각하고 노트에 그린다.
Entity에 따른 Attribute도 생각해보고 각 Entity 옆에 그려본다.
그리고 서로 연결해준다.
이젠 이 Entity 사이의 관계를 생각해본다.
통용되는 그림 규칙은 아래와 같다.

순서대로 1:1, 1:N, N:M 관계이다.
이 관계를 생각해서 연결시켜준 곳에 삼발이를 달아준다.
그리고 두 Entity 사이의 관계가 Optional 한지도 생각해본다.
그러니까, 한 Entity가 있을때 다른 Entity가 꼭 필요한지 말이다.

Optional 하다면 O를 앞에 저런식으로 달아주고 필수인(Mandatory) 곳에는 짝대기를 하나 달아준다.
마지막으로 두개를 겹쳐서 만든다.

개념적 데이터 모델링이 끝나면 위와 같은 형태로 나올 것이다.
3. 논리적 데이터 모델링
위에서 만든 다이어그램을 실제 데이터베이스 프로그램으로 옮긴다.
MySQL Workbench 같은 것을 이용하면 쉽게 만들 수 있다.
공부해볼 키워드: 정규화 Normalization
더 나아가서
그렇다면, 데이터 모델링 과정에 중복되는 데이터를 발견했다면 어떻게 테이블을 만들어야할까?
그렇다. 이 때 필요한게, RDB 그 자체이다. 관계를 맺어주는것이다.
어떤 걸로 관계를 맺어줄까?
Foreign Key!
아래부터는 foreign key 관련에 대해 배운걸 작성해봄.
참조 무결성
참조 무결성..말 참 어렵고 어려운 개념처럼 보인다.
그냥 영어 직역으로 보니까 더 이해가 빠르다.
Referential Integrity.
네이버 사전의 의미를 가져오면
참조의 완전한 상태[온전함] 으로 해석이 된다.
훨씬 이해하기 쉬운듯.
예시

그리고 위키피디아에서 설명하고 있는 예제 그림을 이해하면 더 쉽다.
그림에서는 album테이블에서 artist_id value 중 4가 존재하지 않는 primary key value를 참조하고 있다.
이것을 referential integrity를 강제하지 않았다고 하는 것이다.
어려운 말로하면 "참조 무결성이 깨졌다" 라고 할 수 있을듯.
그런데, 관계형 데이터베이스에서 foreign keys를 사용해서 referential integrity를 제약조건으로 강제할 수 있다. (foreign key를 쓰는 이유)
즉, foreign keys를 사용하면 위와 같은 예제는 가능하지 않다는 이야기이다.
특징
Referential integrity(참조 무결성)은 레퍼런스가 모두 타당하다는 것을 나타내는 데이터의 한 속성이다.
관계형 데이터베이스에서 만약에 한 컬럼이 다른 컬럼을 참조하고 있다면, 참조된 값은 반드시 존재해야한다.
Referential integrity는 즉, 타겟이 되는 "referred value"가 있다는 것을 보장한다.
이 개념이 중요한 것은 데이터베이스에서 referential integrity 상태가 아니라면, 완전하지 않은 데이터를 리턴하게 되기 때문이다. 보통은 에러발생도 없다.
Foregin Keys VS Joins
외래키는 referential integrity(참조 무결성)을 강제하기 위한 위한 제약 조건이다.
Join은 데이터를 쿼리하거나 추출할 때, 데이터를 선택하는 법을 지정하기 위해 특정한 룰을 주느 것이다.
외래키와 Join은 서로 관계없이 동작한다.
참고
Foreign Keys vs Joings in Stackoverflow
Referential integrity in Wikipedia

Kyu 정말 꾸준히 열심히 학습하시는거 본받고싶습니다!👍🏻👍🏻