
어느 날 모든 게시글을 조회하는 기능을 테스트 하던 중 엄청난 양의 쿼리 로그가 찍히는 걸 봐버린 나,,
머리로 생각했을 때 쿼리 한 줄이면 해결될 조회가 왜 이런 결과를 내놓는 것인가 하고 검색하던 중 마주친 유명한 N+1 문제!
말로만 듣고 정확히는 어떤 이유로 발생하는지도 몰랐기에, 관련된 모든 개념과 해결 과정에 대한 회고를 남기고자 합니다.
그럼 시작해 보겠습니다!
0. 환경과 엔티티 관계
모든 설명에 앞서 브릿지 프로젝트 환경과 일부분의 엔티티 관계를 짚고 가야합니다.
- 환경 브릿지 프로젝트는 JPA ORM을 사용하고 있습니다.
- 엔티티 관계 Project 엔티티와 Part 엔티티(모집 분야)는 일대다 양방향 연관관계를 가지고 있습니다.
- Project (게시글)
@Entity @Getter @NoArgsConstructor public class Project { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "project_id") private Long id; private LocalDateTime dueDate; // 게시글 마감일 private LocalDateTime uploadTime; // 게시글 게시일 //...생략 @OneToMany(mappedBy = "project", cascade = CascadeType.ALL) private List<Part> recruit = new ArrayList<>(); // 모집 분야 - Part (모집 분야)
@Entity @Getter @NoArgsConstructor public class Part { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "part_id") private Long id; //.. 생략 @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "project_id") private Project project; // 프로젝트 게시글
- Project (게시글)
1. 문제 상황

위와 같이 JPA와 아래의 조건들을 이용해 모든 프로젝트를 조회하려고 합니다.
- 변수인 dueDate ≤ 필드 값인 dueDate (마감 일이 지난 프로젝트는 제외)
- 필드 값 uploadTime 으로 정렬
서비스 단에서 모든 프로젝트 게시글을 조회하는 메소드를 실행하면
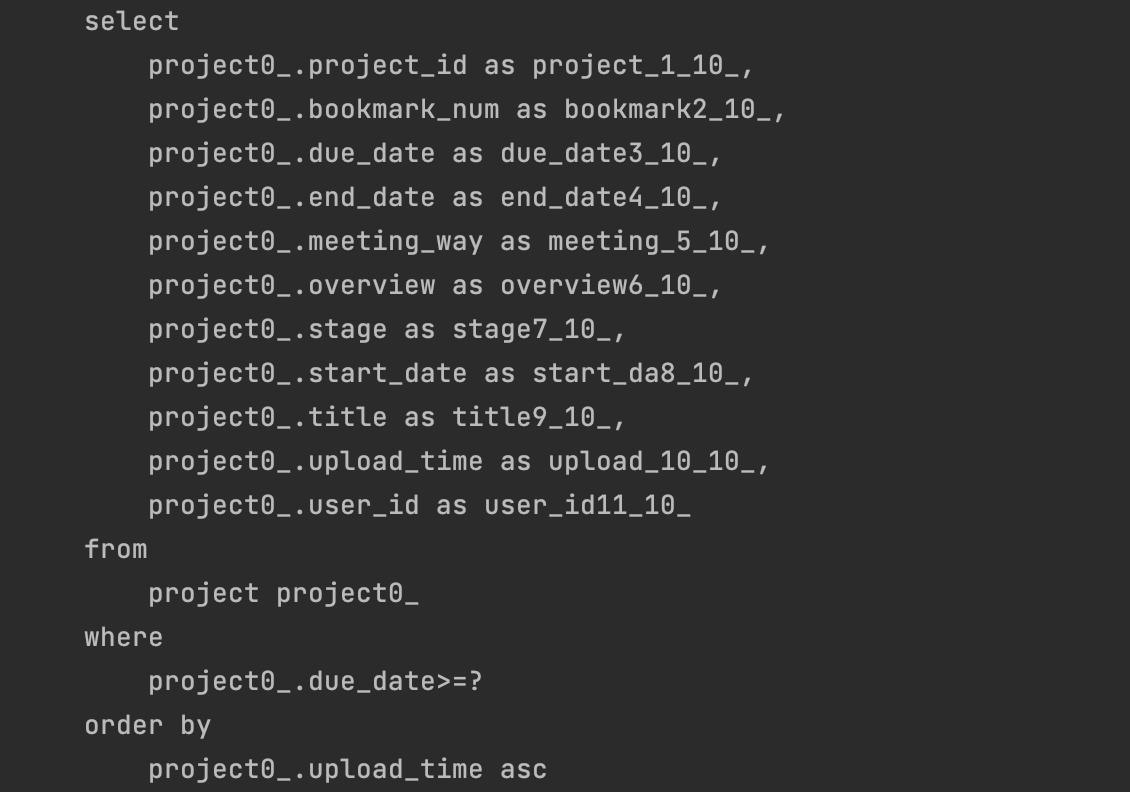
Project들을 조회하는 쿼리가 한 번 실행되고,
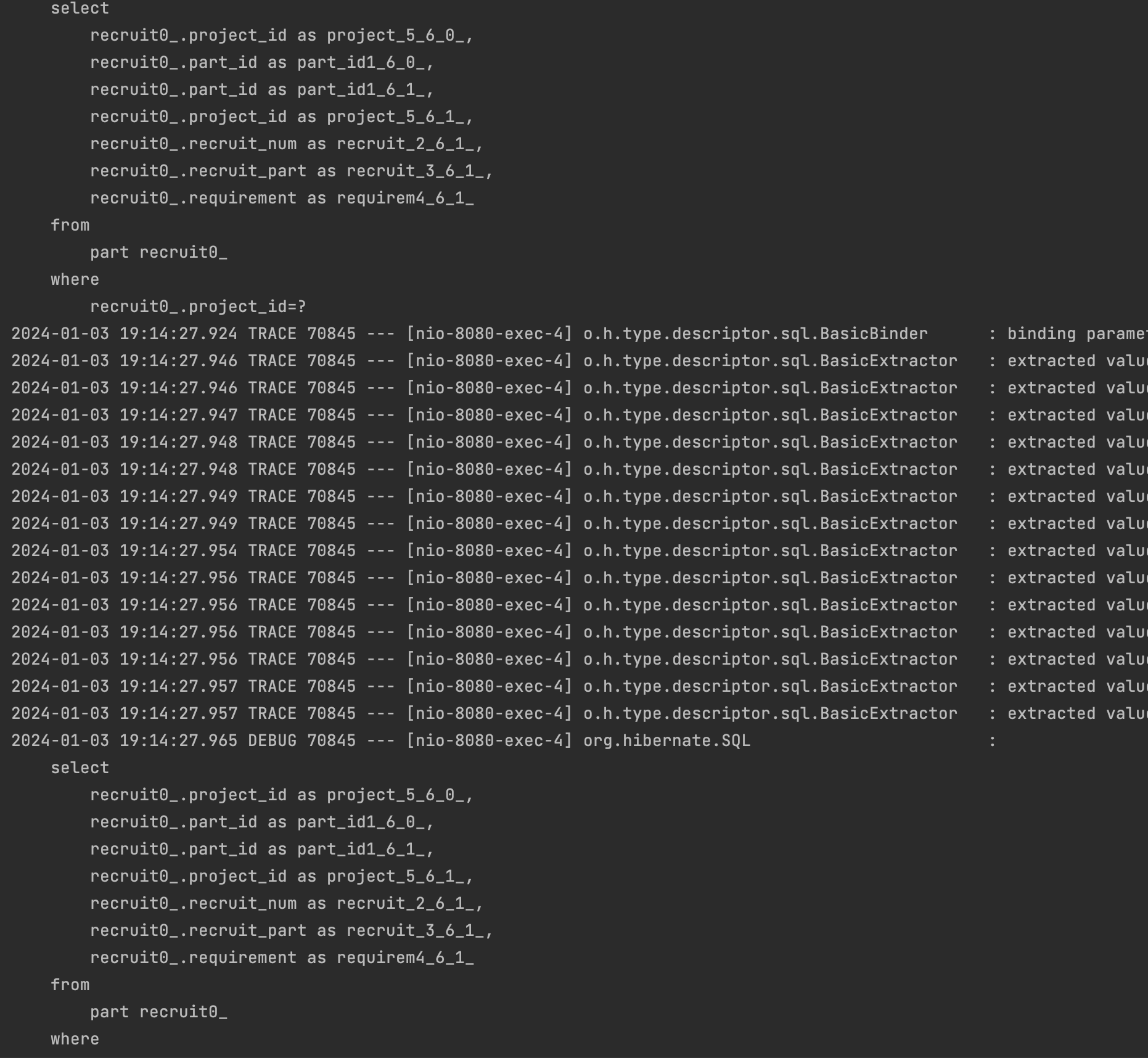
이후에 각 Project 에 연관된 Part를 조회하는 쿼리가 Project의 수 만큼 추가로 실행되는 걸 확인 할 수 있습니다.

처음부터 프로젝트를 조회할 때 JOIN으로 연관된 Part정보도 불러오면 되는 것 아닌가? 라는 생각과 이런 이슈가 N+1 문제 라는 걸 알게 되었습니다.
2. N+1 문제란?
N+1 문제는 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회하는 경우, 조회된 데이터 개수(N)만큼 연관 관계의 조회 쿼리가 추가로 발생하여 발생하는 문제입니다.
2-1. FetchType이 원인?
간혹 N+1 문제가 FetchType 전략에 따라 발생한다고 오해 할 수 있는데,
이런 오해는 EAGER 와 LAZY를 조금만 공부해보면 바로 해결됩니다.
- EAGER(즉시 로딩) - 초기 데이터 조회 시 모든 연관관계 데이터도 함께 로드
- LAZY(지연 로딩) - 연관관계 데이터 사용 시 연관관계 데이터 로드
즉, 연관관계 데이터의 로드 시점이 처음이냐, 사용하는 시점이냐의 차이만 있을 뿐입니다.
그렇다면 N+1이 발생하는 원인은 무엇일까요?
2-2. 실제 원인
Repository에 정의한 인터페이스 메소드를 실행하면 우리의 똑똑한 JPA는 작성한 메소드 이름을 분석하여 JPQL을 생성하여 실행합니다.
따라서 JPQL은 예시로 findAll()이란 메소드를 수행하게 되면 해당 엔티티만 조회하는
SELECT * FROM Entity쿼리만 실행하게 됩니다.
즉, JPQL 입장에서는 연관관계 데이터를 무시하고 조회 엔티티를 기준으로만 쿼리를 실행하는 것이죠.
JPA가 만능은 아니다 란 말을 여러번 들었는데 이러한 이유 때문인가 봅니다.
그렇다면 해결 방법은 무엇이 있을까요?
3. 해결 방법
해결 방법은 주어진 상황과 환경에 따라 조금씩 차이가 있는데, 하나씩 알아보도록 합시다.
3-1.Fetch Join
가장 베이식한 해결방법입니다.
사실 저는 그냥 일반 JOIN으로 N+1문제를 해결할 수 있지 않을까? 생각했는데 모두가 입을 모아
FETCH JOIN을 해결방법으로 다루고 있었습니다. (처음 들어봄)
실제로 일반 JOIN을 사용하여 실행 해본 결과 LazyInitializationException 가 발생합니다.
Fetch Join VS Join 이 궁금하다면?
LazyInitializationException이 궁금하다면?
Fetch Join을 적용하려면 메소드를 통해 자동으로 적용할 수 없고, 직접 JPQL로 작성해야 합니다.

@Query(value = "SELECT distinct p FROM Project AS p LEFT JOIN FETCH p.recruit WHERE p.dueDate >= :dueDate ORDER BY p.uploadTime")
List<Project> findAllByDueDateGreaterThanEqualOrderByUploadTime(@Param("dueDate") LocalDateTime dueDate);위 처럼 @Query 를 통해 원하는 JPQL을 직접 작성하면 됩니다.
한 번 실행해보도록 하겠습니다. 두근두근
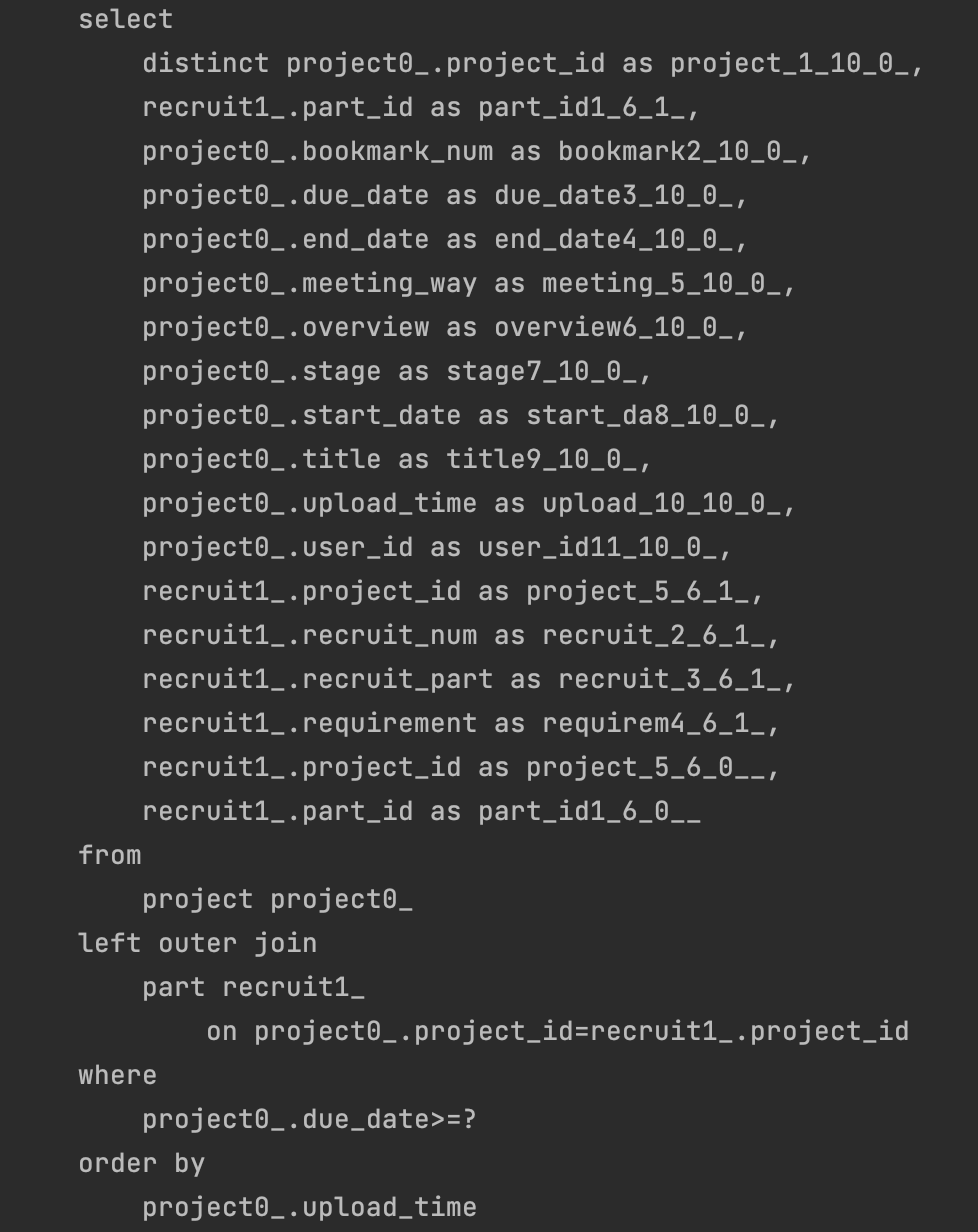
다행히 원하는 대로 Join 을 통해 쿼리 한 번으로 조회가 되었습니다. 👏🏻👏🏻👏🏻
하지만 Fetch Join으로 해결하지 못하는 경우도 있습니다.
만약 페이징 기능을 사용하고 싶다면 Fetch Join을 사용하여 N+1문제를 해결하는 건 좋지 않을 수 있습니다.
- Fetch Join 사용 시 페이징 쿼리 동시 사용 불가
- 페이징 API를 사용하면 쿼리를 통해 데이터를 모두 메모리에 올린 후, 메모리에서 페이징 수행
위와같은 두가지 이슈 때문인데,
페이징을 꼭 수행해야한다면 어떡해야 할까요?
3-2.Batch Size
Hibernate에서 제공하는 @BatchSize를 적용하면 연관된 엔티티를 조회하는 경우 지정한 Size만큼 IN절을 사용해 조회하게 됩니다.
(Size는 IN절에 올 수 있는 최대 인자 개수를 의미합니다)
@Entity
@Getter
@NoArgsConstructor
public class Project {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "project_id")
private Long id;
private LocalDateTime dueDate; // 게시글 마감일
private LocalDateTime uploadTime; // 게시글 게시일
//...생략
@BatchSize(size=5)
@OneToMany(mappedBy = "project", cascade = CascadeType.ALL)
private List<Part> recruit = new ArrayList<>(); // 모집 분야
위처럼 @BatcSize 를 적용하고 실행해보도록 하겠습니다.
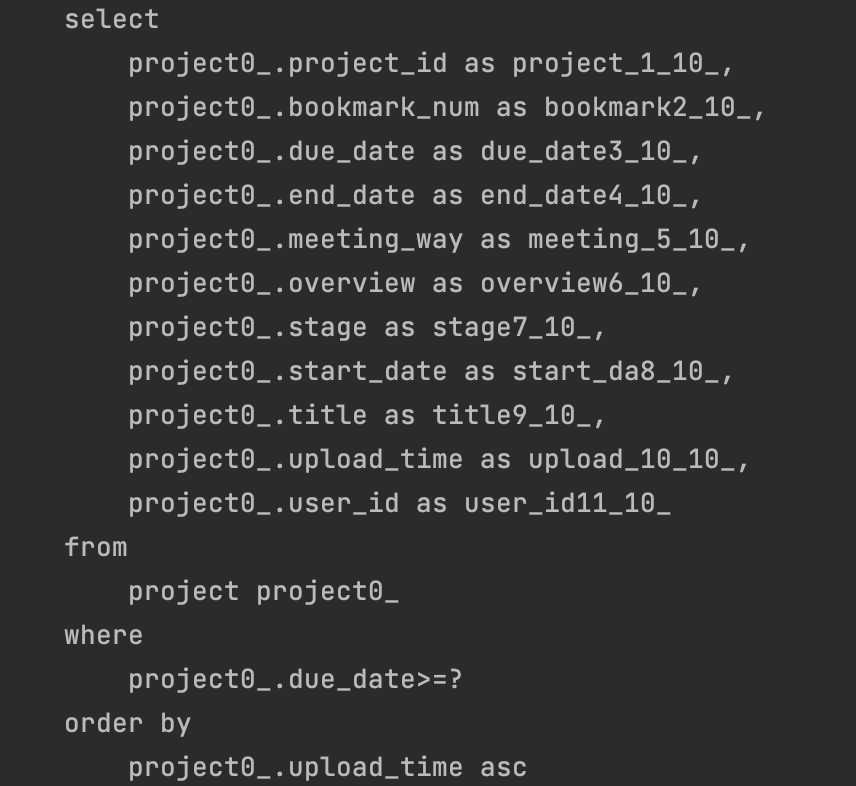
Project를 조회하는 쿼리가 한 번 실행되고,
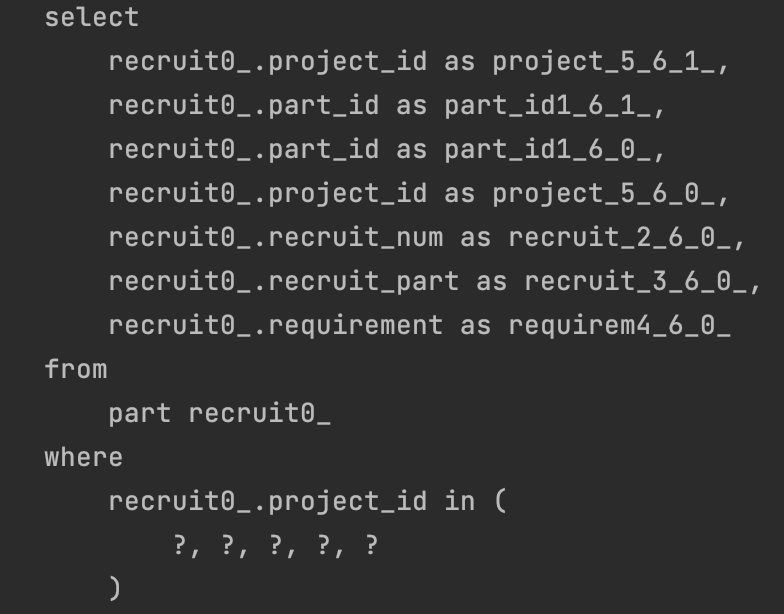
연관된 엔티티 조회 시 설정한 Size 만큼 IN절을 통해 한 번에 가져오는 것을 알 수 있습니다.
Fetch Join처럼 쿼리 한 번으로 조회하는 건 아니지만, 페이징을 수행할 수 있는 장점이 있습니다.
하지만 데이터의 총 개수를 알기는 쉽지 않기 때문에, 최적화할 수 있는 Size 를 설정하는 건 어렵다는 단점이 있습니다.
또 다른 방법을 알아볼까요?
3-3.EntityGraph
직접 JPQL을 작성하여 쿼리를 실행 할 때, 해당 메소드 위에 @EntityGraph을 사용하면 원하는 연관 엔티티를 즉시로딩하여 연관 데이터를 초기에 로딩할 수 있습니다.
또한 Fetch Join과 달리 Inner Join이 아닌 Outer Join으로 쿼리가 실행됩니다.

위처럼 @EntityGraph 설정 후 실행해보면,
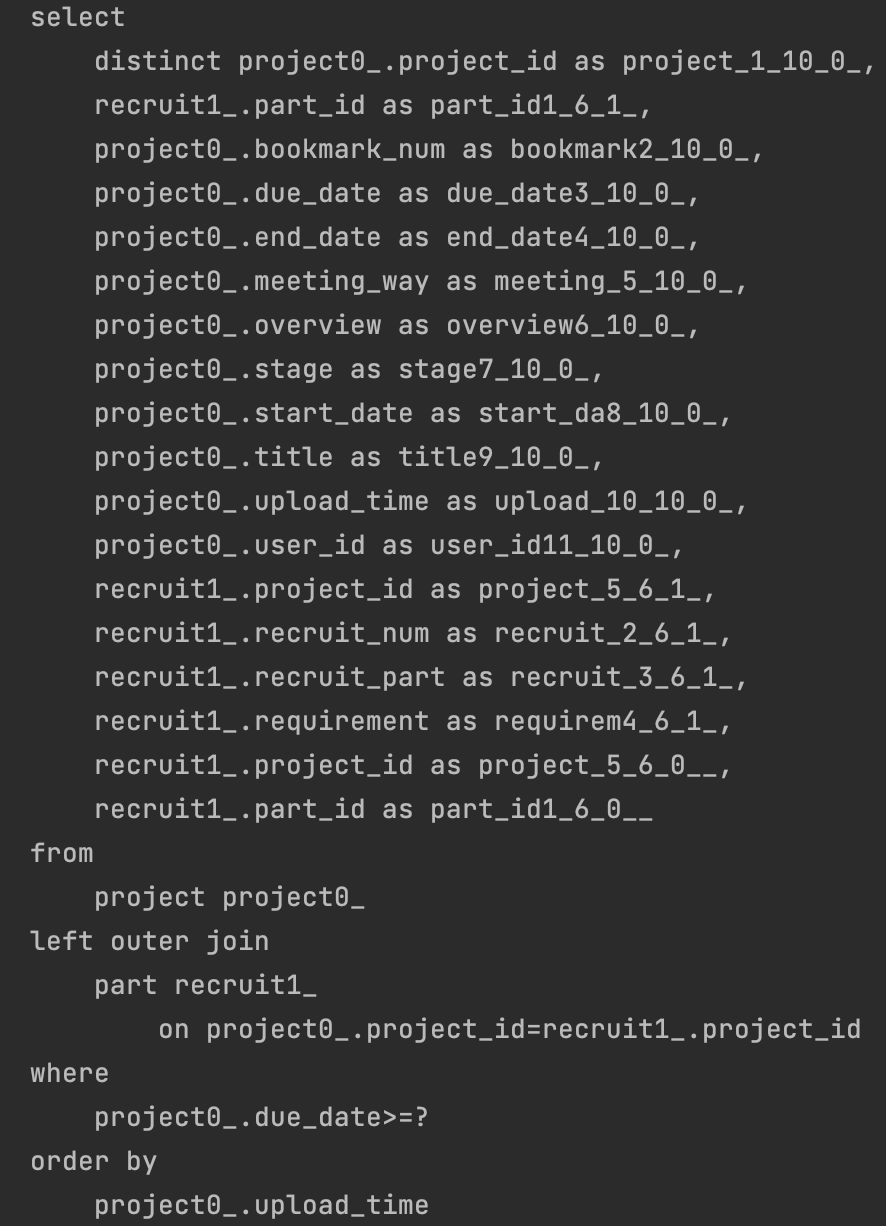
Fetch Join과 마찬가지로 쿼리 한 번으로 초기에 모든 데이터를 로딩하는 것을 알 수 있습니다.
4. 결론
정리해보자면 N+1의 해결방법은 아래와 같습니다.
- Fetch Join 혹은 EntityGraph를 사용하면 쿼리 한 번으로 모든 데이터 조회 가능
- BatchSize 를 통해 원하는 크기만큼 페이징 조회 가능
알아본 여러가지 방법 중, 브릿지 프로젝트는 페이징을 사용하지 않기 때문에, Fetch Join을 이용하여 N+1 문제를 해결했습니다.
JPA가 편리하긴 하지만, 모든 경우의 비즈니스 로직을 구현하진 못하기에 직접 JPQL을 사용하는 등 다양한 방법을 시도해보는 것도 좋을 것 같습니다.
읽어주셔서 감사합니다!
