
안녕하세요!
채팅 기능을 개발하며 사용했던 이벤트 브로커인 Kafka(이하 카프카)에 대해서 정리하려고 합니다!
아마 개발의 길을 걷는 분들은 한번쯤은 들어보셨을 것 같은데요.
들어보지 못하셨다면 행운입니다 이제 알게 되실테니까요! 😊
카프카는 Microsoft, AirBnB, Netflix 같은 빅기업들뿐만 아니라 수많은 기업들이 현업에서 활발하게 사용되고 있습니다
그럼 시작하겠습니다!
1. Kafka란?
먼저 공식페이지의 카프카 정의를 살펴보겠습니다.
- Apache Kafka - an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 사용하는 오픈 소스 분산 이벤트 스트리밍 플랫폼입니다.
조금 쉽게 설명해보자면, 아래와 같습니다.
- 카프카 - 실시간 이벤트 기반 애플리케이션 개발을 지원하는 것을 포함해 많은 이점을 가진 오픈소스 분산형 이벤트 스트리밍 플랫폼
무슨 의미일까요? 탄생 배경부터 하나하나 알아보도록 하겠습니다.
1-1. 탄생 배경
카프카는 비즈니스 소셜 네트워크 서비스인 Linked-In (링크드인)에서 개발했습니다.
기존의 링크드인 데이터 시스템은 여러가지 문제를 가지고 있었습니다.
- 통합된 전송 영역이 없어 데이터 흐름 파악 어려움 → 시스템 복잡도 증가
- 각 애플리케이션과 데이터 시스템 간의 별도의 파이프라인 존재 → 확장 및 유연성 감소 / 관리 어려움
고민 끝에 모든 시스템으로 데이터를 전송 할 수 있고, 실시간 처리 및 확장이 쉬운 시스템을 만들자!
하여 모든 데이터/이벤트 스트림을 중앙에서 관리하는 카프카를 개발하게 되었죠.
1-2. 이벤트 스트리밍
먼저 이벤트란, 일어난 활동 및 그 시간에 관한 디지털 기록이고, 어떤 프로세스의 일환으로 또 다른 활동을 촉발하는 활동이기도 합니다.
보통 ‘어떤 일의 발생’이란 의미에 초점을 맞춥니다.
그렇다면 이벤트 스트리밍은 무엇일까요?
- 이벤트 스트리밍 - 어떤 일이 발생하였을 때에 초점을 맞추어 생성된 데이터
이벤트와 이벤트 스트리밍 의미에 큰 차이는 데이터 입니다.
즉, 핵심은 ‘어떤 일이 일어난 시점’에 대한 ‘데이터’ 가 이벤트 스트리밍입니다.
이벤트 스트리밍의 예를 몇가지 알아볼까요?
- Log
- 실시간 금융정보 및 주식 거래
- 병원에서 실시간 긴급 처치 및 처방을 위한 변화 예측
외에도 많은 예들이 존재합니다.
2. 아키텍쳐
카프카는 Pub-Sub 모델을 따르고, 메세지 큐 형태로 동작합니다. 뿐만 아니라 다양한 구성요소들이 존재합니다.
카프카의 전체적인 흐름과 용도를 알기 위해서 하나하나 알아보도록 하겠습니다.
2-1. Message Queue (MQ)

Producer - 데이터를 제공하는 자
Consumer - 데이터를 가져와 사용하려는 자
MQ - Producer의 데이터를 저장, Consumer가 데이터를 가져오는 곳
Message Queue는 메세지 지향 미들웨어를 구현한 시스템으로 프로세스간 데이터를 교환할 때 사용합니다.
중요한 부분은 Queue 형태인데, MQ에서 메세지는 엔드포인트간 직접 통신하지 않고, 중간 Queue를 통해 중개됩니다.
즉, Producer 와 Consumer 는 서로 직접적인 통신을 하지 않습니다.
이렇게 MQ를 사용하므로써 여러 장점들을 얻을 수 있습니다.
- 비동기 - Queue에 저장 후, 나중에 처리할 수 있음
- 낮은 결합도 - 애플리케이션과 분리
- 확장성 - Producer 와 Consumer 서비스를 확장할 수 있음
- 탄력성 - Consumer 서비스가 다운되도 애플리케이션이 중단되지 않고, 메세지는 MQ에 남아있음
- 보장성 - MQ에 들어간 메세지들은 모두 Consumer 서비에 전달되는 보장 제공
굉장히 강력한 장점들이죠?
2-2. 메세지 브로커 / 이벤트 브로커
-
메세지 브로커
Publisher가 생산한 메세지를 Queue 에 저장 + Consumer가 저장된 메세지를 가져갈 수 있도록 중간 다리 역할을 합니다.
메세지 브로커의 경우 Consumer가 메세지를 가져가면 즉시(짧은 시간) 큐에서 메세지가 사라지는 특징이 있습니다.
대표적으로 RabbitMQ, Redis, GCP의 pubsub, AWS의 SQS가 있습니다.
-
이벤트 브로커
이벤트 또는 메시지라고 불리는 레코드를 하나만 보관하고 인덱스를 통해 개별 액세스를 관리합니다.
메시지 브로커와 이벤트 브로커 모두의 이벤트를 수신하고, 이것을 Consumer 에게 전달하는 데에 목적을 두고 있습니다.
작동 방식의 차이점으로는 생산된 이벤트 처리 후에 즉시 삭제하지 않고 저장하여,
Consumer가 특정 시점부터 다시 이벤트를 수행할 수 있습니다.
또한 메세지 브로커보다 대용량의 데이터를 처리할 수 있는 장점이 있습니다.
대표적으로 Kafka, AWS의 kinesis가 있습니다.
메세지 브로커는 이벤트 브로커 역할을 할 수 없지만, 이벤트 브로커는 메세지 브로커 역할을 할 수 있습니다.
2-3. Pub/Sub 구조
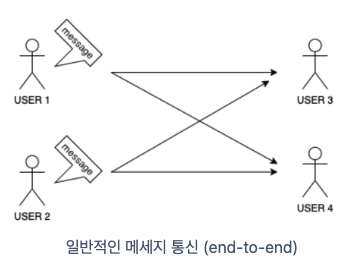
일반적인 네트워크 통신은 위처럼 각 개체가 직접 연결하여 통신합니다.
속도가 빠르고, 결과를 바로 알 수 있는 장점이 있지만,
특정 개체에 장애가 발생하는 경우 개별 처리 해주어야 하고, 확장성이 떨어지는 단점이 있습니다.
단점을 극복하고 나온 구조가 아래와 같은 Pub/Sub 구조입니다.
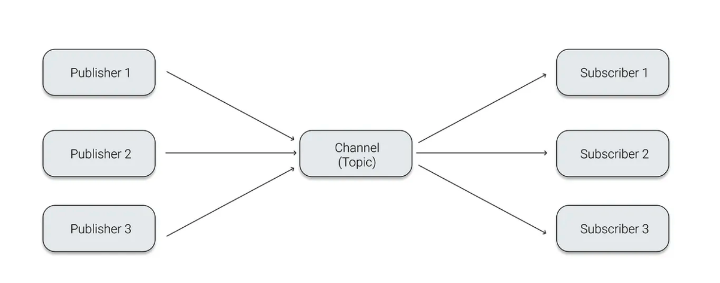
Pub/Sub 구조는 비동기 메세지 전송 방식으로 발행(Publish)되는 메세지는 수신자가 정해져 있지 않습니다.
발행된 메세지는 Subscribe(구독)을 한 수신자만 해당 메세지를 Topic을 통해 받을 수 있습니다.
즉, 수신자는 발신자 정보가 없어도 구독으로 원하는 메세지만 수신할 수 있고, 높은 확장성을 확보할 수 있습니다.
이러한 구조를 사용하는 카프카는 중앙 집중형 메시지 관리 방식으로, 메시지의 생성과 소비와 관리를 완전히 독립시킨 구조입니다.
Publisher 와 Subscriber 역할이 카프카에서 각각 Producer와 Consumer 입니다.
2-4. 카프카 클러스터
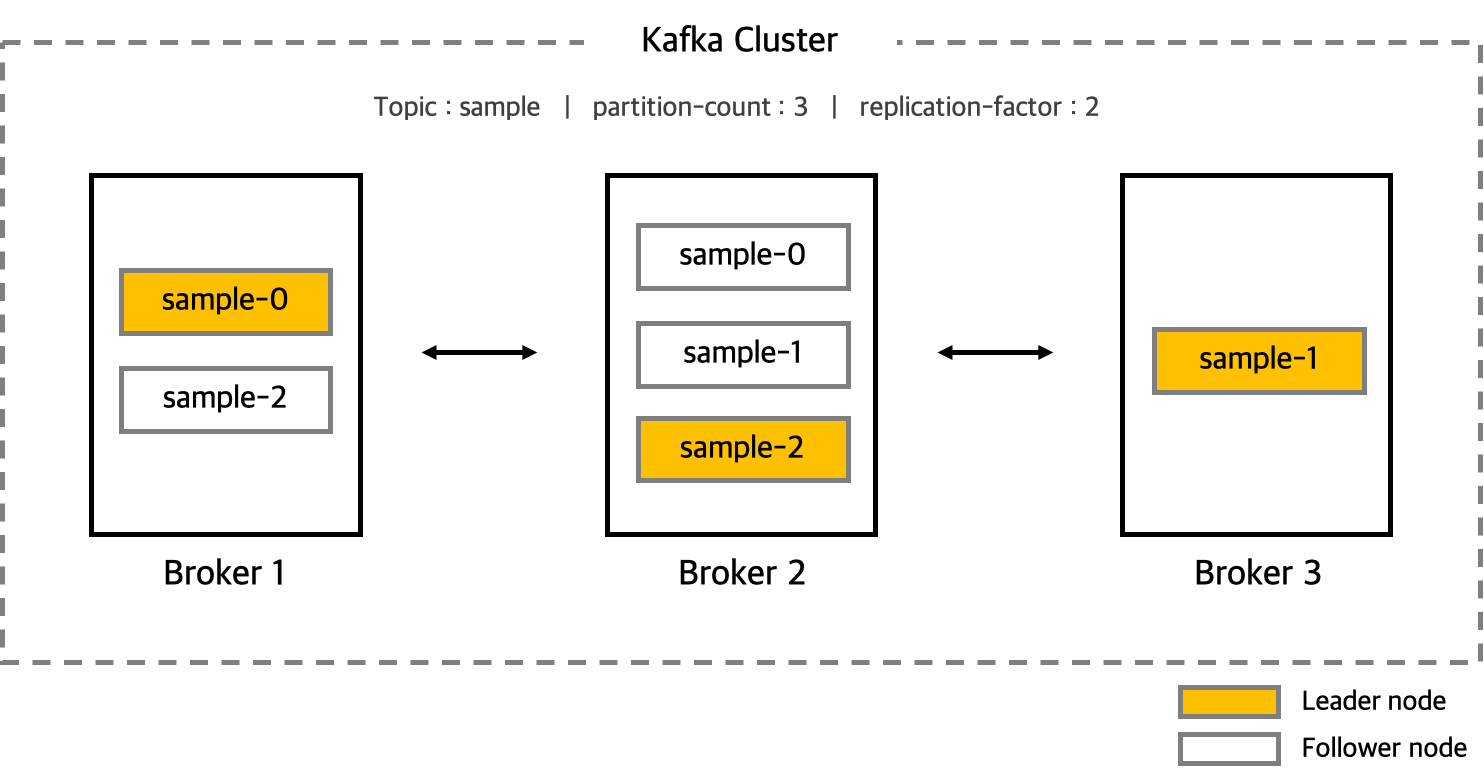
카프카 클러스터는 카프카에서 전체적인 메세지 관리를 담당합니다.
임의 갯수의 노드로 구성되고, 이때 노드를 Kafka Broker Host 라고 합니다.
일반적으로 1개 이상의 Broker를 두어 장애로 인한 데이터 유실을 방지할 수 있습니다.
기본적으로 Topic 내의 파티션이 추가 생성되면 카프카는 등록된 Broker 에 분산된 형태로 새 파티션을 배치시켜 분산된 형태로 처리할 수 있습니다.
1개의 파티션은 리더와 팔로워가 존재하는데 카프카에서는 Replication을 통해 이를 수행합니다.
이러한 특징은 Broker 노드의 장애나 Fail 에 대비하는 것에 목표를 두고 있습니다.
Replication - 각 메세지들을 여러개로 복제하여 카프카 클러스터 내 브로커들에 분산시키는 동작입니다. (정확히는 Topic의 파티션을 복제하는 것)
만약 replication-factor : 3 이라면, 클러스터 내에 최소 3대의 브로커 서버 등록이 보장되어야 하며 1개의 리더 노드와 2개의 팔로워 노드로 구성됩니다. (한 번 꼼꼼히 생각해보시길 추천합니다)
위 사진의 경우는 replication-factor : 2이므로 각 파티션은 1개의 리더 노드와 1개의 팔로워 노드로 구성되어 브로커들에 분산되어 있는 것이죠.
- 리더 파티션 : 브로커에 할당된 주담당 파티션으로 데이터의 쓰기/읽기 담당
- 팔로워 파티션 : 리더 파티션으로부터 데이터 복제만을 담당
참고로 replication-factor 값은 파티션 각각에 대해 카프카 클러스터 내의 모든 브로커에 동일한 값으로 설정되어야 하는 값입니다.
파티션은 이렇게 리더 - 팔로워 구조를 유지하다가, 만약 리더 노드로 등록된 브로커가 죽었을 때 팔로워들 중 하나를 다시 리더로 선출하여 데이터의 유실을 방지하고 복구를 진행할 수 있도록 합니다.
(만든분들 천재네요)
3. 구성 요소
카프카의 구성 요소에 대해서 자세히 알아보도록 하겠습니다.
3-1. Topic
- 메시지를 논리적으로 묶은 개념 (데이터베이스의 테이블 / 파일시스템의 폴더와 유사한 개념)
- 각각의 메시지를 목적에 맞게 구분할 때 사용 (ex. 연예 Topic, 스포츠 Topic)
- 메시지를 전송하거나 소비할 때 Topic을 반드시 입력
- Consumer는 자신이 담당하는 Topic의 메시지를 처리
- 한 개의 토픽은 한 개 이상의 파티션으로 구성
3-2. Producer
- 메시지를 만들어서 카프카 클러스터에 전송
- 메시지 전송 시 Batch 처리가 가능
- Key값을 지정하여 특정 파티션으로만 전송도 가능
- 전송 ACKS 값을 설정하여 효율성을 높일 수 있음
- ACKS=0 : 매우 빠르게 전송. 파티션 리더가 받았는지 알 수 없음
- ACKS=1 : 파티션 리더가 받았는지 확인 (Default)
- ACKS=ALL : 파티션 리더 뿐만 아니라 팔로워까지 메시지를 받았는지 확인
3-3. Consumer
- 카프카 클러스터에서 메시지를 읽어서 처리
- 메세지를 Batch 처리할 수 있다.
- 한 개의 Consumer는 여러 개의 Topic을 처리 가능
- 메시지를 소비해도 메시지를 삭제하지 않음(Kafka delete policy에 의해 삭제). 한 번 저장된 메시지를 여러번 소비 가능
- Consumer는 Consumer Group에 속함
- 한 개 파티션은 같은 Consumer Group의 여러 개의 Consumer 에서 연결할 수 없음 (주의)
3-4. Partition
- 분산 처리를 위해 사용
- Topic 생성 시 Partition 개수를 지정할 수 있음 (파티션 개수 변경 가능. *추가만 가능)
- 파티션이 1개라면 모든 메시지에 대해 순서가 보장
- 파티션 내부에서 각 메시지는 Offset(고유 번호)로 구분
- 파티션이 여러개라면 카프카 클러스터가 Round-Robin 방식으로 분배해서 분산처리되기 때문에 순서 보장 X
- 파티션이 많을 수록 처리량이 좋지만, 장애 복구 시간이 늘어남
3-5. Broker
- 실행된 카프카 서버를 말함
- Producer 와 Consumer 는 별도의 애플리케이션으로 구성되는 반면, 브로커는 카프카 자체
- Broker(각 서버)는 Kafka Cluster 내부에 존재
- 서버 내부에 메시지를 저장하고 관리하는 역할을 수행
3-6. Offset
- Consumer에서 메세지를 어디까지 읽었는지 저장하는 값
- Consumer Group의 Consumer들은 각각의 파티션에 자신이 가져간 메시지의 위치 정보(offset) 을 기록
- Consumer 장애 발생 후 다시 복구되면, 전에 마지막으로 읽었던 위치에서부터 다시 읽어들일 수 있음
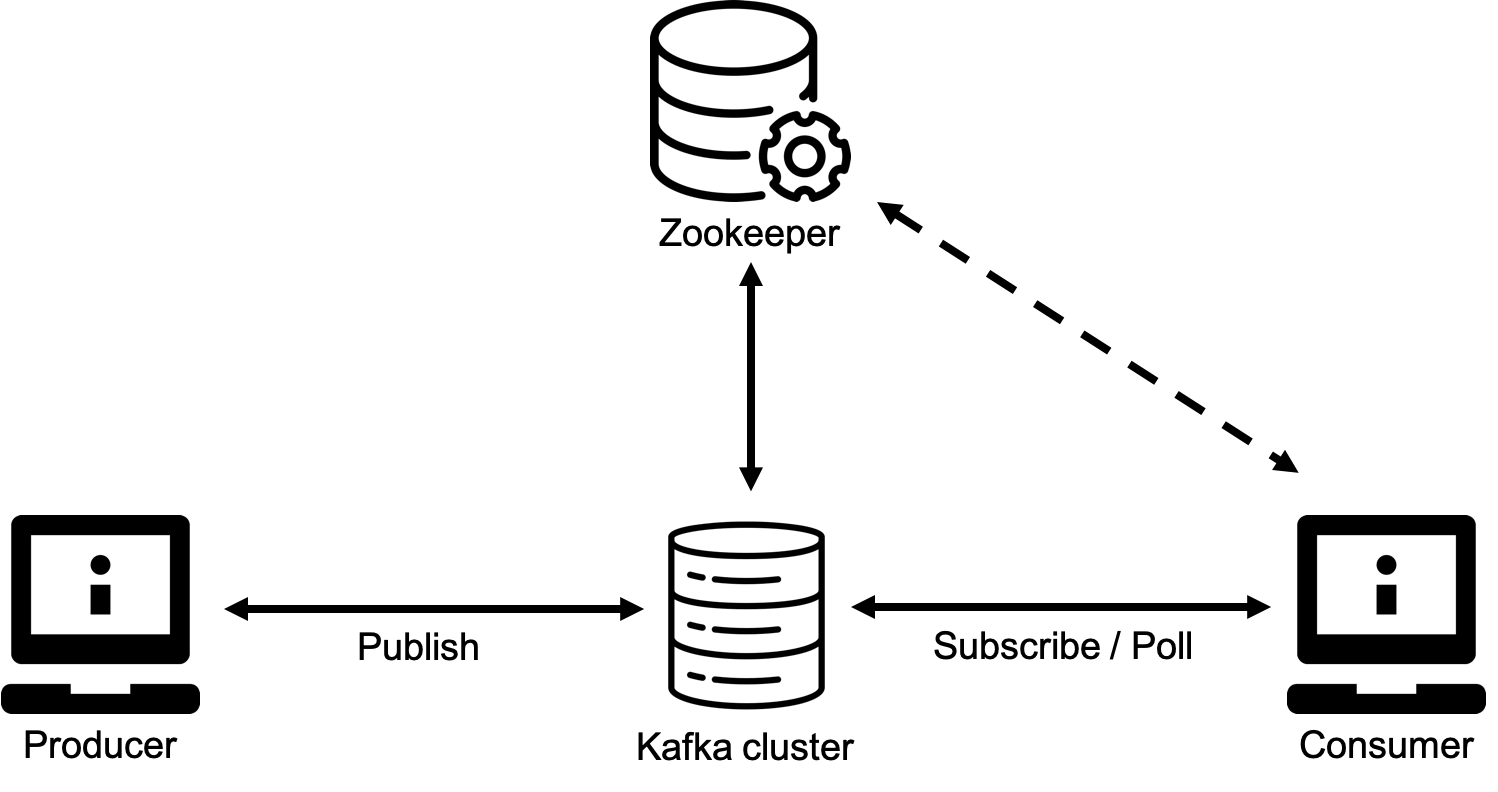
3-7. Zookeeper
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산 메시지큐의 메타 정보를 중앙에서 관리하는 역할
4. 동작 원리
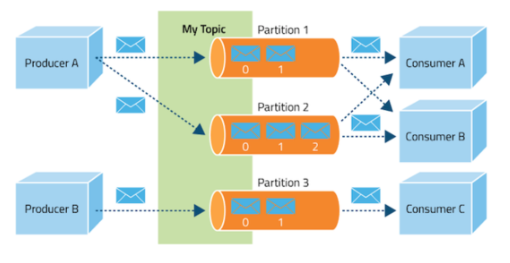
- 동작 원리
- Publisher는 전달하고자 하는 메세지를 Topic을 통해 카테고리화
- Subscriber는 원하는 Topic을 구독(subscribe)함으로써 메시지를 읽어옴
- Publisher와 Subscriber는 오로지 Topic 정보만 알 뿐, 서로에 대해 알지 못함
- 카프카는 브로커들이 하나의 클러스터로 구성되어 동작하도록 설계
- 클러스터 내, 브로커에 대한 분산처리는 Zookeeper가 담당
위의 아키텍쳐와 구성요소를 잘 이해하셨다면 카프카의 동작원리도 어렵지 않게 이해하실 수 있습니다.
5. 설계 특징
마지막으로 구성요소에서 알아본 Partition 과 Consumer Group이 필요한 이유에 대해서 알아보도록 하겠습니다.
5-1. Partition 설계 이유
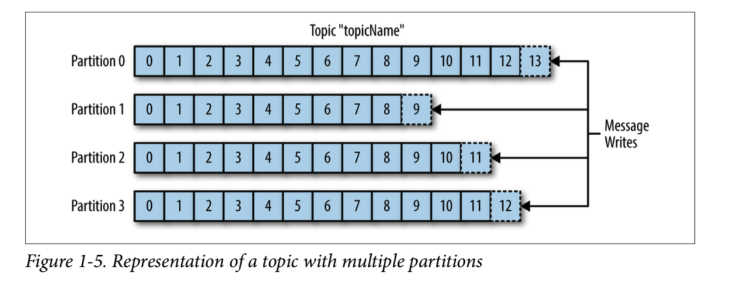
하나의 Topic을 여러개의 파티션으로 분산시키는 주된 목적은 메세지의 처리를 병렬로 수행하기 위함입니다.
Topic 에 메세지가 쓰여지는 것도 시간이 소요되므로, 만약 몇 천건의 메세지가 동시에 들어오면 병목현상이 일어날 수 있습니다.
따라서 파티션을 여러개 두어서 메세지를 분산 저장함으로써 쓰여지는 동작을 병렬로 처리할 수 있게 됩니다.
다만, 한번 늘린 파티션은 절대 줄일 수 없기 때문에, 운영 중에 파티션을 늘리는 건 충분히 검토 후 실행되어야 합니다. (최소한의 파티션으로 운영하고 사용량에 따라 늘리는 것을 권장)
파티션을 늘렸을 때 메세지는 Round-Robin 방식으로 쓰여집니다.
따라서 파티션이 한개라면 메세지 순서가 보장되지만, 파티션이 여러개일 경우에는 순서가 보장되지 않습니다.
5-2. Consumer Group 설계 이유
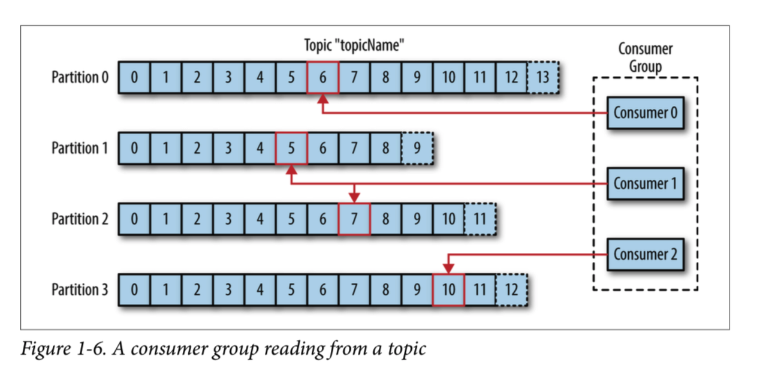
Consumer의 묶음을 Consumer Group 이라고 합니다.
Consumer Group은 하나의 Topic에 대한 책임을 갖고 있습니다. 즉 하나의 Topic 만 담당하는 것이죠.
그렇다면 왜 여러개의 Consumer를 모아논 Consumer Group 단위가 필요할까요?
만약 어떤 Consumer가 다운된다면, 파티션 재조정(리밸런싱)을 통해 Group 내의 다른 Consumer가 해당 파티션의 sub을 맡아서 수행합니다.
또한 Offset 정보를 그룹간에 공유하고 있기 때문에 다운되기 전 마지막으로 읽었던 메세지 위치부터 시작할 수 있습니다.
6. 장점
카프카는 현재 많은 기업에서 사용하는 만큼 명확한 장점들을 가지고 있습니다.
- 대규모 트래픽 처리 및 분산 처리에 효과적
- 클러스터 구성, Fail-over, Replication 같은 다양한 기능 존재
- 100Kb/sec 정도의 속도 (다른 메세지 큐보다 빠름)
- 디스크에 메세지를 특정 보관 주기동안 저장하여 데이터의 영속성이 보장되고 유실 위험이 적습니다. 또한 Consumer 장애 발생 시 재처리가 가능합니다.
긴 호흡으로 카프카에 대해서 자세히 알아봤습니다.
포스트 내용은 이론에 관한 것이기 때문에, 서비스에 직접 사용해보는 것은 또 다른 이야기이니 직접 사용해보는 것도 좋은 경험일 것 같습니다.
그래도 조금이라도 아! 하는 부분이 있었다면 행복합니다.
읽어주셔서 감사합니다 😄
References
