
Flowery는 개발, PM, 디자인, 기획을 포함하여 14명이 진행하는 큰 규모의 사이드 프로젝트입니다. 저는 현재 여기서 프로젝트 총괄을 맡고 있으며, 서비스의 설계 및 구현에 참여하고 있습니다.
I. 개요: 모니터링 서버의 필요성
사실 필요하기보다는, 만들어보고 싶다는 생각이 크다...ㅎㅎ 하고 싶은거 다 해보는 Flowery
로그 데이터는 많은 서비스들이 유기적으로 돌아가는 MSA 환경에서는 중요한 자리를 차지한다. 수집된 로그 데이터는 발생하는 오류를 추적하고 원인을 알아낼 수 있는 중요한 단서가 되고, 서버의 최적화 작업, 예상치 못한 버그 등을 찾는데 매우 큰 도움이 된다.
이전에 창업을 했었을 때, 초중반 서비스 운영시 가장 힘들었던 것이 원인 모를 오류를 추적하고 해결하는 것이었다. 이유를 알 수 없는 오류가 발생했을 때, dev 환경에서 재현을 하기가 어려워 밤을 새며 찾았던 기억이 새록새록하다...ㅎㅎ 당시에는 CassandraDB를 활용하여 간단한 로그 수집 서버를 만들었었고, 수집되는 로그를 통해서 보다 수월한 디버깅이 가능했었다.
해당 경험을 살려 이번에도 모니터링 서버를 만들어보려고 한다. 다만, 이번 기회에 평소 공부를 해보고 싶었던 기술 스택인 ELK 스택을 사용해서 만들어보려고 한다.
II. ELK?
ELK 스택은 Elasticsearch + Logstash + Kibana를 합친 말이다. 각자 독자적으로 사용이 가능한 기술들이지만, 이 3가지가 함께 사용이 되는 경우가 많아 ELK 기술 '스택'이라고 보통 부른다.
간단하게 설명을 해보도록 하겠다.
-
Elasticsearch: 로그 검색 및 저장Elasticsearch는 분산형 검색 & 분석 엔진이다. 로그와 같이 많은 양의 데이터를 저장하는 데이터 웨어하우스이면서, 동시에 해당 데이터를 검색 및 분석 기능도 제공하여 로그 데이터 저장소로 안성맞춤이다.
-
Logstash: 로그 수집 및 변환Logstash는 로그 데이터 처리 파이프라인이다. 다양한 소스에서 전달되는 로그 데이터를 수집하는 퍼넬(Funnel)와도 같은 역할을 함과 동시에 데이터를 저장하기 전 가공하고 변화시키는 필터링 작업을 진행한다.
-
Kibana: 로그 데이터 시각화Kibana는 시각화 도구이다. 대쉬보드와 각종 분석 툴을 사용하여 수집된 로그 데이터의 시각화 기능을 제공한다.
즉, 정리하자면
1. Filebeats 혹은 Message Queue로 어떠한 로그 데이터가 들어오면
2. Logstash는 해당 로그 데이터를 수집 및 가공을 하고,
3. Elasticsearch는 가공된 로그 데이터를 저장하며,
4. Kibana는 해당 로그 데이터에 대한 정보를 시각화하여 제공한다.
정도가 되겠다.
III. InfluxDB?
TSDB의 대표격인 InfluxDB의 사용 유무를 고민했었다. 하지만, 결국에는 사용 안하기로 판단을 하였다. 이유는 다음과 같다.
- 시간 순서로 데이터를 저장하는 시계열 데이터베이스의 경우, 해당 역할을
Elasticsearch가 이미 행하고 있다. - 그렇다면 남은 역할은 metrics 정보 수집인데, 이는 이후에
Prometheus를 활용하여 수집할 것이고,Prometheus는 이미 시간 순서대로 수집한 metrics를 저장한다.
즉, 오버 엔지니어링이라고 판단이 되어서 InfluxDB는 아쉽지만 이번 프로젝트에서는 사용하지 않기로 결심했다.
IV. Filebeat
이제 문제는 '어떻게 로그를 수집하느냐'인데, 이는 Filebeat를 활용하기로 했다. Logstash에서 기본적으로 제공하는 integration이기도 하고, 로그 파일을 모니터링한 후 Logstash로 포워딩을 하는 방법으로 작업을 진행할 수 있다는 점이 마음에 들어서 해당 스택을 선정하였다.
Filebeat: 로그 수집 및 전송Filebeat는 각 서버에 설치가 되어 동작을 한다. 로그 파일이 생성되는 경로를 설정하면Filebeat는Havester를 통해 해당 로그 데이터를 읽고,libbeat로 새로운 로그 데이터를 전송한다.libbeat는Filebeat의 코어 시스템 중 하나로, 로그 데이터를 수집하고 설정한 output으로 해당 로그 데이터를 전송한다.
우선 각 microservice에 filebeat agent를 설치하고, 저장되는 logfile들을 모니터링하여 logstash로 전송하는 방법을 사용할 것이다.
V. Conclusion
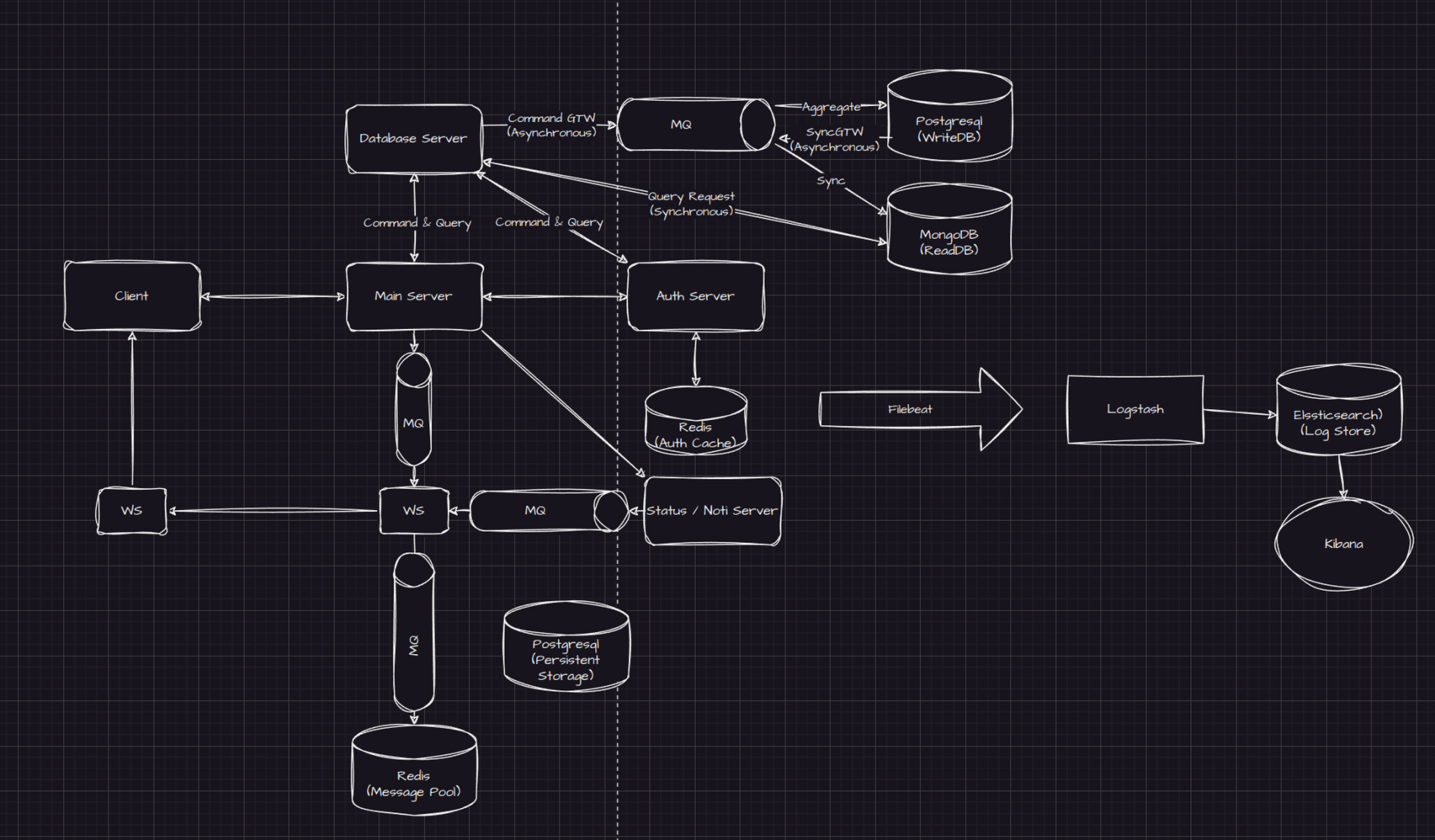
모니터링 서버까지 설명해놓은 서버의 구조이다. Logstash의 설정이 꽤나 빡세 보이는데, 해당 스택을 공부하며 많은 공부가 되었으면 좋겠다. :)
References
Elastic Stack: (ELK) Elasticsearch, Kibana & Logstash
Logstash: Centralize, transform & stash your data
Filebeat Overview
