Flowery 회고록 #1: Developing CQRS - 좋은 데이터베이스 서버 구조를 설계하는 과정
Flowery 회고록

Flowery는 개발, PM, 디자인, 기획을 포함하여 14명이 진행하는 큰 규모의 사이드 프로젝트입니다. 저는 현재 여기서 프로젝트 총괄을 맡고 있으며, 서비스의 설계 및 구현에 참여하고 있습니다.
I. 개요: 데이터베이스 서버
현재 Flowery 서비스는 여러 개의 서비스가 나뉘어져있는 MSA 구조로 설계가 되고 있다. 여러개의 서비스가 서로 유기적인 관계를 맺어 하나의 서비스를 운영하는 구조. 하고 싶은 것을 다 할 수 있는 사이드 프로젝트이기에, 나는 이 MSA구조에 특별한 데이터베이스 서버를 구축하기로 결심했다.
현재까지 구성된 대략적인 서버 구조는 다음과 같다.
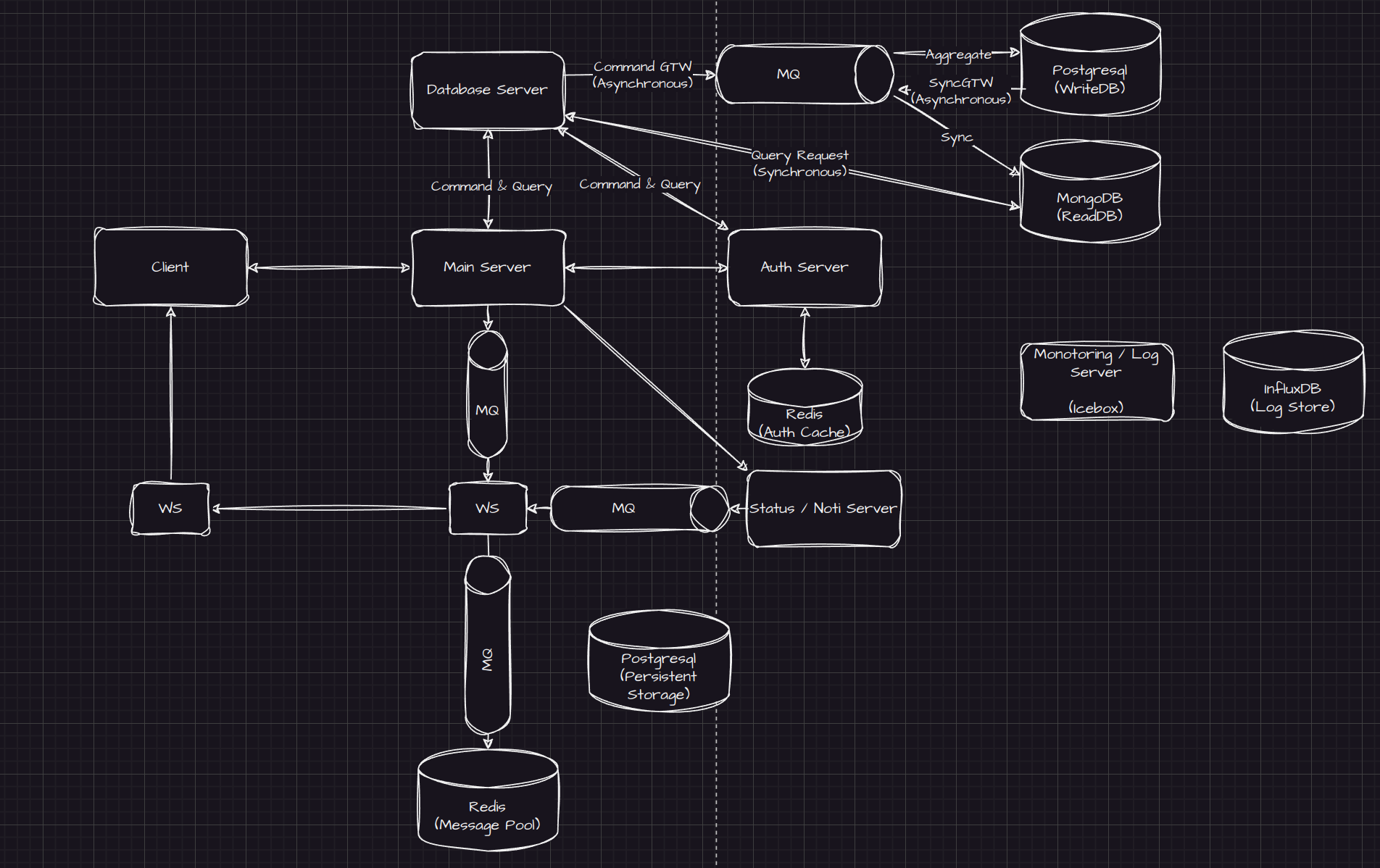
상단을 보면나의 욕심이 그득그득 들어간 데이터베이스 서버를 볼 수 있다. 이를 하나하나 분석해보자.
II. ReadDB와 WriteDB
-
데이터베이스 서버는 2개의 데이터베이스, ReadDB (MongoDB)와 WriteDB (Postgresql)을 사용하고 있다.
-
WriteDB로는 Postgresql를 채택했다. Persistent data가 직접 저장이 되는 공간이기에 데이터의 스키마를 철저하게 설정할 수 있어야 한다고 판단이 되었고, 이는 WriteDB로 RDB를 사용하기로 결정하는데 큰 영향을 미쳤다. RDB 중 가장 많이 사용하기도 했고 익숙한 Postgresql를 선정하였다.
-
ReadDB로는 MongoDB를 채택했다. WriteDB와는 달리 ReadDB는 사용 목적에 따라서 정말 다양한 스키마가 만들어질 수 있는 데이터베이스이다.
- 예를 들어, WriteDB에서 2개의 Table을 join해야하는 데이터가 있다고 가정했을 때, 해당 View를 그대로 ReadDB에 저장함으로 WriteDB의 부하를 줄이고 더욱 빠른 data retrival이 가능하도록 했다. 이것이 가능하려면 ReadDB는 스키마 설정에 있어서 제약이 자유로워야한다.
-
또한 많은 Read에 대해서 NoSQL이 RDB보다 이점이 있다고 하기도 하고 (그래봤자 자체적 caching으로 인해 티끌만한 차이겠지만), 자유로운 스키마 설정이라는 이유로 인해 ReadDB로는 NoSQL을 설정하기로 했다. 고민을 하다가 많은 레퍼런스가 있는 MongoDB로 결정을 하였다.
-
III. CQRS
이전에 CQRS에 대한 글을 적은 적이 있다. 해당 글을 바탕으로 다음과 같이 DB서버를 설계하였다.
- Create, Update, Delete는 Command로서, Message Queue를 활용하여 비동기적(asynchronous)으로 작업을 한다.
- Read는 Query로서, ReadDB에 대한 Query를 활용하여 동기적(synchronous)으로 작업을 한다.
이하는 요약이 된 Workflow이다.
Command
- Controller로 command가 들어오면
CommandGateway로 해당 command를 전송한다.commandGateway는 message queue로 해당 command를 전송할 것이다. - Queue된 command는 곧바로 관련
Aggregate에 전달이 된다.Aggregate는 Create, Update, Delete 등의 작업을 수행하는 객체이다. - 작업이 수행된 후, 곧바로 sync, 즉 동기화 작업이 진행이 된다. 해당 내용은 다음 장에서 설명한다. 해당 작업을 통해 관련된 ReadDB의 데이터는 WriteDB와 동일한 사본을 갖게 된다.
Query
- Controller로 query가 들어오면 관련
Projection에 전달이 된다. Projection은 ReadDB에서 해당 데이터를 읽어온 후 Controller에 반환을 한다.
IV. Synchronize - CDC & Eventual Consistency
먼저 동기화 (Sync)의 정의를 확실히 한다. 해당 글에서 동기화란, WriteDB-ReadDB간의 유지되어야 하는 데이터 일관성을 위해 진행하는 작업을 의미한다,
해당 데이터베이스 서버의 main issue는 'WriteDB와 ReadDB간의 차이'를 최소화하는 것이다. 데이터에 대한 불일치를 최소화하는 것이 해당 데이터베이스 시스템 설계의 관건이라고 할 수 있다.
가장 먼저 결정을 해야하는 것은 CDC (Change Data Capture), 즉 데이터에 변화가 생겨 WriteDB-ReadDB간의 일관성이 깨지는 순간을 찾는 것이다. 해당 시점이 바로 ReadDB와 WriteDB간의 일관성을 유지하기 위해 동기화 작업이 필요한 순간이다.
나는 간단하게 CDC의 시점을 Command 작업이 일어나는 시점으로 선택을 하였고, Command가 끝날때마다 연관된 데이터의 Sync작업을 진행해주기로 했다.
다음은 이제 어떻게 Sync 작업을 구현하는가인데, CommandGateway와 같은 방법으로 이를 구현하였다.
- Command가 작업이 된 후, 곧바로
SyncGateway로 동기화 이벤트를 발생한다. - 해당 이벤트는 곧 해당하는
Sync에 전달이 되고, 연관이 되는 모든 ReadDB의 Document를 업데이트한다.
이와 같은 Event-Driven 방법으로 WriteDB와 ReadDB간의 일관성을 유지하기로 결정하였다. Sync 이벤트가 소비되는 순간, ReadDB는 WriteDB와 동일한 버전의 데이터를 갖게 될 것이다. 찰나의 순간에는 데이터 불일치가 발생하지는 몰라도, 궁극적으로는 모두 동일한 데이터를 갖게 하는, 궁극적 일관성 (Eventual Consistency) 모델을 차용한 것이다.
V. 아쉬운 점
이 간단한 CQRS 모델의 아쉬운 점이라고 하면, 해당 모델은 완전한 Eventual Consistency를 제공하지 않는다는 것이다. 만약 DB Transaction이 일어나고, 해당 이벤트가 Sync Gateway의 Message Queue에 전달되지 않는다면, 동기화 작업은 일어나지 않을 것이다. ReadDB는 해당 변화를 업데이트하지 않을것이며, Eventual Consistency는 깨져버리게 된다. 즉, CDC라고 한 Command의 transaction과 동기화 작업이 atomic하지 않다!
더 최악인건, 해당 모델의 일관성은 온전히 Sync Gatway의 Message Queue에 의존하고 있기 때문에, 위와 같은 일이 발생하면 동기화가 자동으로 복구되지 않아, 수동으로 복구해야한다는 점이다. (DB 수동 작업이라...끔찍하군 끔찍해...)
Outbox Pattern으로 동기화 작업과 transaction을 atomic하게 유지할 수 있겠다. 가장 naive하게 한번 구상이나 해볼까.
- WriteDB에 command_log라는 이름의 로그 테이블을 만들고, command 작업 시 command_log에 해당 command 관련 로그를 적는다.
- JPQL을 활용하던, 쌩 Native Query를 활용하던 해당 작업이 Atomic하게 이루어지게 한다.
- 5~10초마다 해당 table을 polling하는 마이크로서비스를 하나 만든다. 해당 서비스는 로그가 추가되면 바로 불일치를 감지할 수 있을 것이다. 해당 서비스가 CDC를 담당한다.
- 만약에 불일치 발생 시, 추가된 로그를 바탕으로 동기화 이벤트를 Sync Gateway의 Message Queue에 넣어준다.
- 이 방법이면 적어도 확실한 CDC는 확보가 되어 Eventual Consistency를 보장할 수 있게 된다.
으, 근데 너무 마음에 안든다. RDBMS에 로그와 같이 High-write, Low-read 데이터를 저장하는 것도, polling이라는 방식도 마음에 안든다.
사이드 프로젝트이기도 하고, 일단 이렇게만 구현을 한 다음에 해당 프로세스를 개선해보자!!
(나중에 찾아보니 Postgresql의 WAL을 사용해서 구현할 수 있다고 하는데, MySQL의 binlog같다. 그런데 외부 툴도 연결해야한다고 하고...워크로드가 조금 많이 들어갈 것 같네... :( 하지만 충분히 공부할만한 가치는 있다고 판단이 된다! 나중에 공부하면 해당 내용도 정리해봐야지!)
VI. Summary
물론 Axon과 같이 해당 CQRS를 Event-Sourcing 방법으로 구현해주는 Framework가 있었으나, 레퍼런스가 적고 직접 구현하며 공부하고 싶은 마음이 더욱 커 하나하나 스스로 구현하는 방법을 채택하였다. 현재 이 글을 쓰는 시점에서는 해당 방법으로 보일러플레이팅을 완료한 상태이며, 테스트도 잘 되는 것 같아서 기분이 좋다 :)
