인트로
python으로 자료구조 강의를 통해 배운 Stack, Queue, LinkedList가 어떻게 구현될 수 있는지 궁금해서 한번 공부해보았다.
목차
- ADT vs Data Structure
- Stack
- Queue
- LinkedList
추상 데이터 타입(ADT, Abstract Data Type) vs 자료구조(Data Structure)
추상 데이터 타입(ADT)
-데이터 타입의 정의가 그 데이터 타입의 구현으로부터 분리된 데이터 타입을 말한다.
-사용자들은 추상 데이터 타입이 제공하는 연산만을 사용한다.
-사용자들은 추상 데이터 타입이 제공하는 연산의 명세를 이해 해야 한다. 즉 이것들을 어떻게 사용하는지 알아야한다.
-사용자들은 추상 데이터 타입 내부의 데이터에 접근할 수 없다. 이러한 캡슐화 개념이 추상 데이터 타입 내부의 데이터를 보호한다.
-사용자들은 내부의 데이터에 접근할 수 없지만 추상 데이터 타입을 사용할 수 있다. 즉 데이터가 어떻게 저장되는지 모르더라도 사용은 가능하다.
만약 다른 사람이 추상 데이터 타입의 구현을 변경하더라도 인터페이스가 변경되지 않으면 사용자들은 여전히 추상 데이터 타입을 같은 방식으로 사용할 수 있다.
=> ADT는 구현에 독립적이다
ADT의 필요성
사용자입장에서 ADT는 이 데이터 타입은 이러이러한 객체들(objects)과 이러이러한 함수들(functions)로 구성되어있다'라는 것을 명시해 놓은 '사용설명서' 같은것이기 때문에 외부에 공개적(public) 입니다.
그렇지만 구현 부분을 나타내지 않기 때문에 내부는 비공개적(private)입니다.
=> 정보은닉
즉, 사용자는 사용법만 알면, 내부는 몰라도 그 데이터 타입을 쉽게 쓸 수 있다는 것이다.
*데이터 타입(Data Type): 객체 + 객체 위에서 동작하는 연산들의 집합
자료구조(Data Structure)
-ADT를 프로그래밍언어로 구현한 것이다.
-효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다.
-자료구조는 여러종류가 있고, 각각의 자료구조는 각자의 연산 및 목적에 맞추어져있다.
-스택, 큐, 연결리스트, B-트리(데이터베이스에서 사용됨), 라우팅 테이블(네트워크에서 사용됨)
Stack의 ADT연산
Stack은 LIFO(Last In First Out)원칙을 따른다.
‘Stack(called S)‘은 ADT 이고 아래의 연산을 지원한다.
- S.push(e): S의 top에 원소e를 삽입(=추가)한다.
- S.pop(): S의 top에있는 원소를 삭제(=제거)한다. 만약, S가 비어있다면 에러를 반환한다.
- S.peek(): S의 top에있는 원소를 반환한다. 만약, S가 비어있다면 에러를 반환한다.
- S.is_empty(): S의 top에 원소가 있는지/없는지에 따라 비어있지않은지/비어있는지를 판단한 결과를 반환한다.
- S.size(): S의 크기(=원소의 개수를 반환한다.
Stack의 자료구조
# python의 list자료구조를 통해 LIFO로 동작하는 Stack구현
class StackADT:
# empty stack생성.
def __init__(self):
self.data = []
# stack의 top부분에 원소e를 삽입.
def push(self, e):
self.data.append(e)
# stack의 top부분에 있는 원소를 삭제(or 제거) 후, 해당 원소를 return
# 만약 stack이 empty라면 에러를 return
def pop(self):
if self.is_empty():
raise IndexError('Stack is empty')
else:
return self.data.pop()
# stack의 top부분에 있는 원소를 return
# 만약 stack이 empty라면 에러를 return
def peek(self):
if self.is_empty():
raise IndexError('Stack is empty')
else:
return self.data[-1]
# 만약 stack이 empty라면 True를 return
def is_empty(self):
return len(self.data) == 0
# stack의 size를 return
def size(self):
return len(self.data)
# start of main
# if '__name__' == main:
S = StackADT()
S.push("S")
S.push("T")
S.push("A")
S.push("C")
S.push("K")
S.peek() # K
S.size() # 5
S.is_empty() # False
S.pop() # K
S.pop() # C
S.pop() # A
S.pop() # T
S.pop() # S
S.is_empty() # True
S.size() # 0
S.peek() # IndexError: Stack is emptyQueue의 ADT연산
Queue는 FIFO(First In First Out)원칙을 따른다.
Queue(called Q)는 ADT이고 아래의 연산을 지원한다.
- S.enqueue(e): Q에 뒷부분으로 원소e를 삽입(=추가)한다.
- S.dequeue(): Q에 원소를 삭제(=제거)한다. 만약, Q가 비어있다면 에러를 반환한다.
- S.peek(): Q에 첫번째 원소를 반환한다. 만약 Q가 비어있다면 에러를 반환한다.
- S.is_empty(): Q에 원소가 있는지/없는지에 따라 비어있지않은지/비어있는지를 판단한 결과를 반환한다.
- S.size(): Q의 크기(=원소의 개수)를 반환한다.
Queue의 자료구조
# Python의 list자료구조를 통해 FIFO로 동작하는 Queue구현
class QueueADT:
# 비어있는 Queue생성
def __init__(self):
self.data = []
# Q에 뒷부분으로 원소e를 삽입(=추가)한다.
def enqueue(self, e):
self.data.insert(0, e)
# Q에 원소를 삭제(=제거)한다.
# 만약, Q가 비어있다면 에러를 return
def dequeue(self):
if self.is_empty():
raise IndexError('Queue is empty')
else:
return self.data.pop()
# Q에 첫번째 원소를 return
# 만약 Q가 비어있다면 에러를 return
def peek(self):
if self.is_empty():
raise IndexError('Queue is empty')
else:
return self.data[-1]
# Q가 비어있다면 True를 return
def is_empty(self):
return len(self.data) == 0
# Q의 크기를 return
def size(self):
return len(self.data)
Q = QueueADT()
Q.enqueue("Q")
Q.enqueue("U")
Q.enqueue("E")
Q.enqueue("U")
Q.enqueue("E")
Q.peek() # Q
Q.size() # 5
Q.is_empty() # False
Q.dequeue() # Q
Q.dequeue() # U
Q.dequeue() # E
Q.dequeue() # U
Q.dequeue() # E
Q.is_empty() # True
Q.size() # 0
Q.peek() # IndexError: Queue is emptyLinked List
Linked List(연결 리스트)는 노드(데이터 + 포인터(다음 노드의 주소를 담고있음))들이 한 줄로 연결되어 있는 방식의 자료구조입니다.
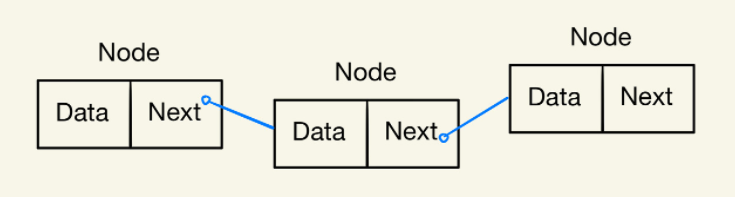
Linked List란?
Linked List는 Array처럼 선형 데이터 자료구조이지만, Array는 물리적인 배치 구조 자체가 연속적으로 저장되어 있고 Linked List는 노드의 Next부분에 다음 노드의 위치를 저장함으로써 선형적인 데이터 자료구조를 가진다.
Python 내장 함수의 시간 복잡도에서 List의 삽입/삭제의 시간복잡도가 O(n)이 걸리는 것은 배열이 물리적인 데이터의 저장 위치가 연속적이어야 하므로 데이터를 옮기는 연산작업이 필요하기 때문입니다.
하지만 Linked List는 데이터를 삽입/삭제할 경우, 노드의 Next부분에 저장한 다음 노드의 포인터만 변경해주면 되므로 배열과 비교하였을 때 Linked List가 효율적으로 데이터를 삽입/삭제할 수 있습니다. 그러나 안타깝게도 Linked List에서 특정 위치의 데이터를 탐색하기 위해서는 첫 노드부터 탐색을 시작하여야 합니다. 그 시간이 O(n)만큼 걸리게 되므로 탐색에 있어서는 배열이나 트리에 비해 상대적으로 느리다고 할 수 있습니다.
Linked List의 장점
- Linked List의 길이를 동적으로 조절 가능
- 데이터의 삽입/삭제가 쉬움
Linked List의 단점
- 임의의 노드에 바로 접근할 수 없음.
- 다음 노드의 위치를 저장히기 위한 추가 공간이 필요함.
- Cache Locality를 활용해 근접 데이터를 사전에 캐시에 저장하기 어려움
- Linked List를 거꾸로 탐색하기가 어려움
Linked List 구현
삽입
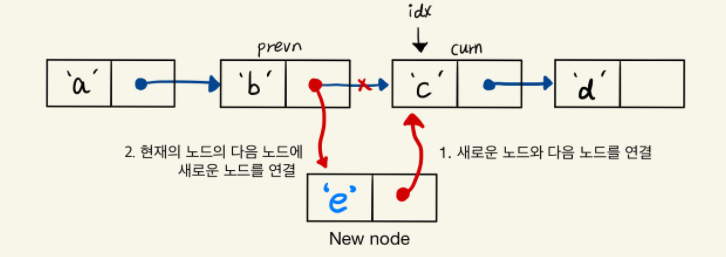
삭제
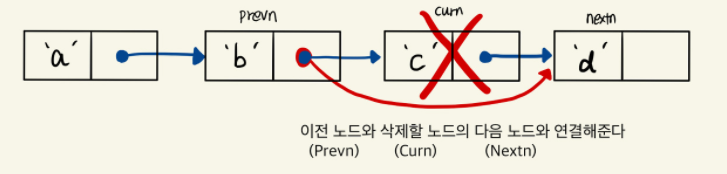
LinkedList의 자료구조
# 노드 class선언
class Node:
def __init__(self, data):
self.data = data
self.next = None
# 연결리스트 선언
class LinkedList:
def __init__(self):
self.head = None
self.count = 0
#연결리스트의 끝부분에 새로운 노드추가
def append(self, data):
if self.head == None:
self.head = node
else:
cur = self.head
while cur,next != None:
cur = cur.next
cur.next = Node(data)
#모든 노드 값 출력
def print_all(self):
cur = self.head
while cur != None:
print(cur.data)
cur = cur.next
# 특정 인덱스에 있는 노드 알아내기
def get_node(self, index):
cnt = 0
node = self.head
while cnt < index:
cnt += 1
node = node.next
return node
#삽입
def add_node(self, index, value):
new_node = Node(value)
if index == 0:
new_node.next = self.head
self.head = new_node
return
node = self.get_node(index-1)
next_node = node.next
node.next = new_node
new_node.next = next_node
#삭제
def delete_node(self, index):
if index == 0:
self.head = self.head.next
return
node = self.get_node(index-1)
node.next = node.next.next
자료구조 연산 시-공간 복잡도 비교
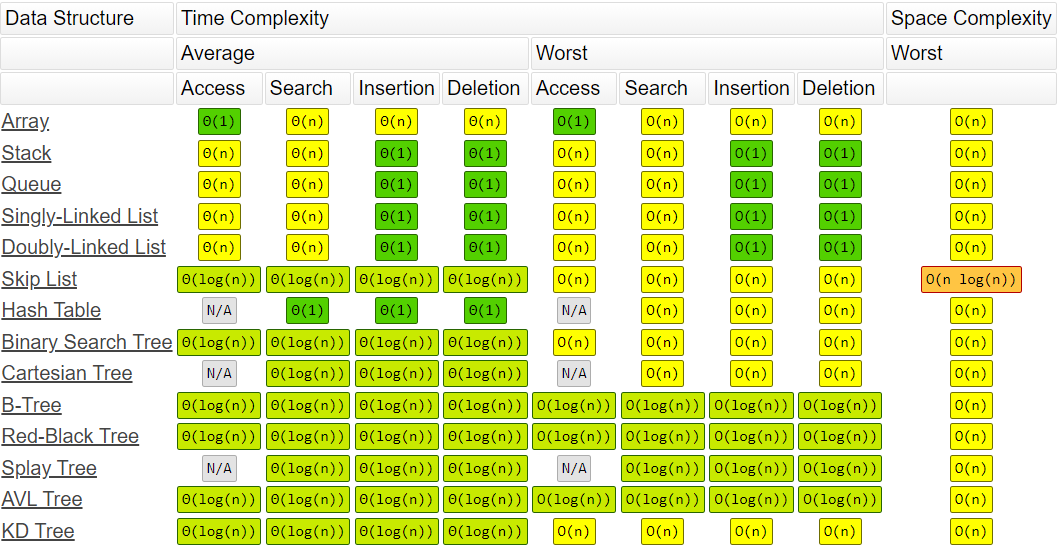
참조
자료구조 3강] 추상 데이터 타입(Abstract Data Type)
르크의 it로 캠핑가자
위키피디아-자료구조
Mosh Hamedani-Data Structure
Big-O Cheat Sheet
