01 크롬 개발자 도구
우리가 흔히 접속하는 웹사이트의 HTML 태그는 생각보다 더 복잡하다. 태그들의 분석을 위해 개발자 도구를 이용하자. (크롬으로 접속함)
사이트에 접속한 다음 우클릭 > [검사] 를 클릭하면 Elements 에 웹 사이트를 구성하고 있는 HTML 코드가 나타난다. 너무 짧다면, 토글을 눌러서 해당 상세 코드를 볼 수 있다.
좋은 점은 위 코드에 마우스를 올려두면 색으로 해당 코드가 웹 사이트에서 어떤 부분을 의미하는지 확인 할 수 있다는 점이다. 확인해보자.
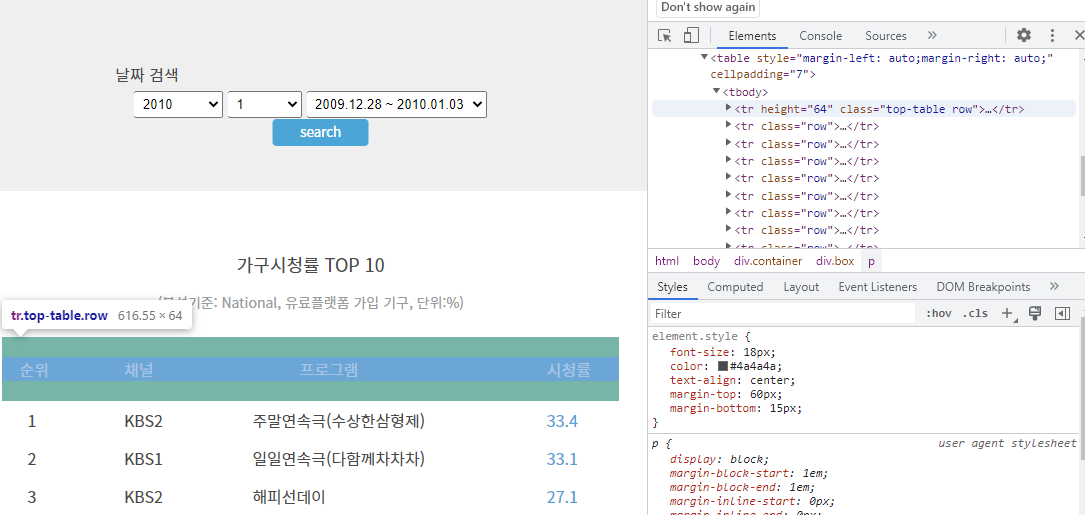
토글을 펼치고 펼치니 tr 태그가 나타났고, 그 안에는 th 태그가 있었다. 마우스에 올려놓아서 각각 순위, 채널, 프로그램, 시청률이 어떻게 화면에 띄어졌는지 확인할 수 있었다.
02 Beautiful Soup 라이브러리
Beautiful Soup 을 사용하는 이유는 웹 페이지 상에 존재하는 HTML 태그에서 원하는 정보 (HTML 태그)를 쉽게 빼올 수 있기 때문이다. 이따가 보겠지만 쉽게말해 select 하나로 가능하다.
Beautiful Soup4 라이브러리를 설치했다.
(터미널에서 설치할 수도, [File] > [Settings] > interpreter 검색 > + 누르고 원하는 라이브러리 선택 > install)
앞서 html 태그를 가져오는 방법은 익혔을 것이다. requests 라이브러리의 get 메서드를 통해 가져오고, .text 를 찍어주면 텍스트화되어 나타난다.
rating_page 에 들어있는 html 태그를 어떻게 하면 선택하기 쉬운 상태로 만들까? 파싱 을 이용하는 것인데, 이 과정을 Beatiful Soup 가 해준다. 코드는 다음과 같다.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://workey.codeit.kr/ratings/index")
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
print(soup.select('table')rating_page 는 html 코드가 담겨있었고, 그것을 파라미터로 전달해줬다.
BeautifulSoup 파라미터에 들어갈 내용은 코드를 담은 변수 , html.parser 이다. 여기서 파서란 말 그대로 쪼개는 것 을 의미한다. 이렇게 쪼갠 것을 soup에 넣어두면 이제 soup 는 select 메서드를 활용할 준비가 되었다. 'table' 태그만 모아서 추출하라 명령하면 잘 나온다.
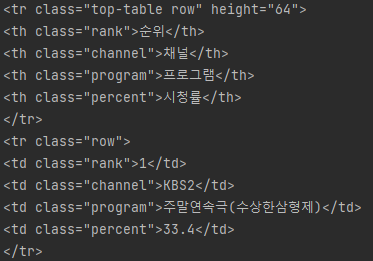
아래 코드가 더 많았다. table 태그가 좀 길어서 페이지의 이름인 title 태그를 가져오겠다.

title 태그는 딱 하나이므로 저렇게 눈에 잘 보이게 나온다. 어쨌든 변수.select 로 원하는 태그에 쉽게 접근할 수 있게 되었다.
03 원하는 태그 선택하기
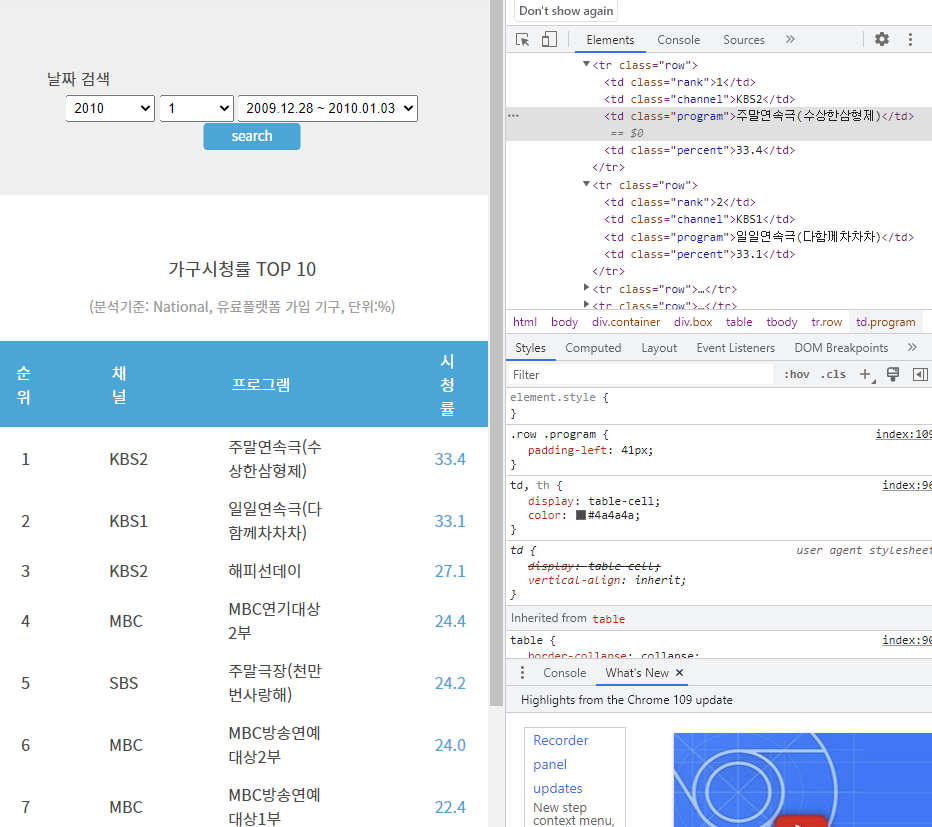
시청률 순위에 오른 방송의 이름을 선택하고 싶다고 가정하자.
개발자 도구에서 들어가 확인한 결과, 태그 이름은 td이고 클래스 이름은 program 이다.
✅ Select 메서드 이용하기
태그 이름은 td & 클래스 이름은 program 인 것을 코드로 나타내면 어떻게 할까?
td.program 이다. &는 바로 붙여쓴다고 했고 클래스는 . 으로 나타내기 때문이다!
🍀 날 것으로 뽑고 싶다면..
가장 기본적인 코드를 보자.
response = requests.get("https://workey.codeit.kr/ratings/index")
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
print(soup.select('td.program'))출력결과는 다음과 같다.
[<td class="program">주말연속극(수상한삼형제)</td>, <td class="program">일일연속극(다함께차차차)</td>, <td class="program">해피선데이</td>, <td class="program">MBC연기대상2부</td>, <td class="program">주말극장(천만번사랑해)</td>, <td class="program">MBC방송연예대상2부</td>, <td class="program">MBC방송연예대상1부</td>, <td class="program">SBS연예대상2부</td>, <td class="program">주말기획드라마(보석비빔밥)</td>, <td class="program">일일시트콤(지붕뚫고하이킥)</td>]약간 날 것의 느낌이 든다. 프로그램 이름만 뽑는 수는 없을까?
🍀 리스트와 get_text() 로 프로그램 이름만 리스트에 담기
response = requests.get("https://workey.codeit.kr/ratings/index")
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
program_title_tags = soup.select('td.program')
program_titles = []
for tag in program_title_tags:
program_titles.append(tag.get_text())
print(program_titles)
다음과 같은 경우에 담고, 변수를 한 번 더 포문으로 리스트에 담은 것이다. 결과를 보자.
['주말연속극(수상한삼형제)', '일일연속극(다함께차차차)', '해피선데이', 'MBC연기대상2부', '주말극장(천만번사랑해)', 'MBC방송연예대상2부', 'MBC방송연예대상1부', 'SBS연예대상2부', '주말기획드라마(보석비빔밥)', '일일시트콤(지붕뚫고하이킥)']
잘 담겼다!
🍀 태그 중 맨 위의 값만 보는 select_one 메서드
번외로, select_one 코드를 이용하면 잡아낸 것 중 가장 위의 코드 하나만 보여준다.
print(soup.select_one('td.program'))
<td class="program">주말연속극(수상한삼형제)</td>04 꿈의 직장 전화번호 모으기
오렌지 보틀이 꿈이라는 친구한테 전화번호를 긁어모아주자.
import requests
from bs4 import BeautifulSoup
# 여기에 코드를 작성하세요
response = requests.get("https://workey.codeit.kr/orangebottle/index")
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
phone_numbers = []
num_tags = soup.select('span.phoneNum')
for tag in num_tags:
phone_numbers.append(tag.get_text())
# 테스트 코드
print(phone_numbers)전화번호 리스트에 담아서 잘 출력했다!
05 원하는 태그 선택하기 (2)
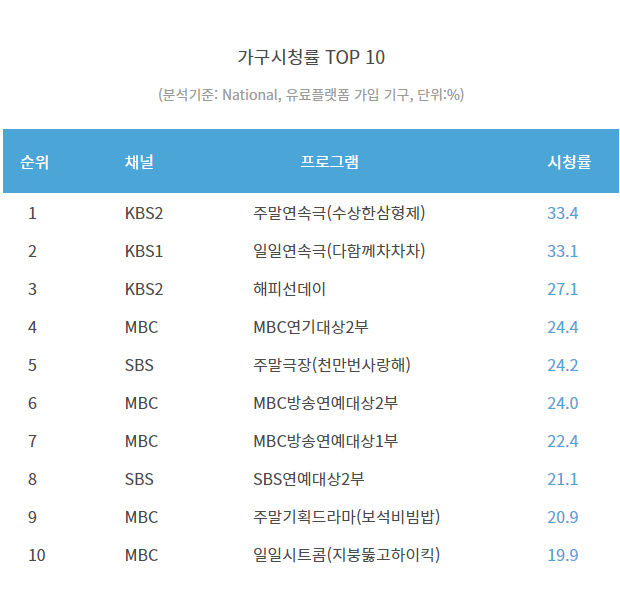
위 페이지에서 순위 1 위를 차지한 열을 모두 불러오고 싶다. 어떻게 해야할까? 먼저 다시 개발자 도구에서 태그를 확인해보자.
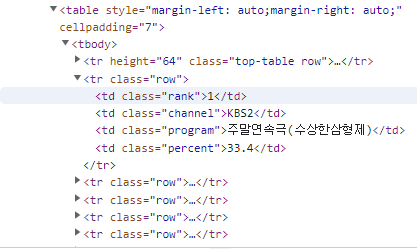
원하는 정보는 td 태그였다. 그러나 td 태그는 다른 열도 td 태그이기 때문에.. 슬라이싱 이 무조건 필요했다. 코드를 보자.
soup = BeautifulSoup(rating_page, 'html.parser')
print(soup.select('td')[:4])0~3 번 인덱스까지 슬라이싱 해주었다. 따라서 한 열의 원하는 정보만 출력이 되었으나.. get_text() 를 이용하는 게 더 깔끔하겠다.
soup = BeautifulSoup(rating_page, 'html.parser')
td_tags = soup.select('td')[:4]
for tag in td_tags:
print(tag.get_text())슬라이싱 한 것을 변수에 넣고, 반복문을 돌리면서 get_text() 를 입혀줬다.

06 슬라이싱과 range 함수
07 원하는 태그 선택하기 3
soup.select 는 soup 라고 내가 지정한 전체 html 코드에서 가져오는 것이었다면,
.select 의 앞에 다른 태그가 있어도 괜찮다.
상위태그.select('하위태그 이름')
전체html.select('원하는 태그 이름')
두 방법 모두 괜찮다는 것이다. 이번에는 아까와 다른 방법으로 잡아보자.
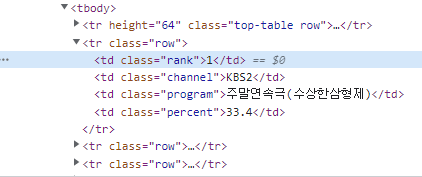
원하는 tr 태그는 사실 상위 태그로 td 태그를 가지고 있었다. 여러 td 태그 중 두번째 td 를 선택하고, 그 안의 tr 태그를 가져오는 코드는 다음과 같다.
🍀 태그로 출력하기
response = requests.get("https://workey.codeit.kr/ratings/index")
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
tr_tag = soup.select('tr')[1]
td_tags = tr_tag.select('td')
print(td_tags)tr_tag 에는 두번째 tr 태그가 들어가있다.
그때 다시 tr 태그에서 td 만을 선택해 (이 경우 전체 코드긴 하다)
그것을 출력하면 결과는 다음과 같다.
[<td class="rank">1</td>, <td class="channel">KBS2</td>, <td class="program">주말연속극(수상한삼형제)</td>, <td class="percent">33.4</td>]🍀 텍스트로 출력하기
좀 더 이쁘게 출력하자!
soup = BeautifulSoup(rating_page, 'html.parser')
tr_tag = soup.select('tr')[1]
td_tags = tr_tag.select('td')
for tag in td_tags:
print(tag.get_text())
1
KBS2
주말연속극(수상한삼형제)
33.408 꿈의 직장 전화번호 모으기 (2)
import requests
from bs4 import BeautifulSoup
# 여기에 코드를 작성하세요
response = requests.get('https://workey.codeit.kr/orangebottle/index')
rating_page = response.text
soup = BeautifulSoup(rating_page, 'html.parser')
branch_infos = []
for i in range(len(soup.select('.branch'))):
branch_name = soup.select('.branch')[i].select('.city')[0].get_text()
address = soup.select('.branch')[i].select('.address')[0].get_text()
phone_number = soup.select('.branch')[i].select('.phoneNum')[0].get_text()
branch_infos.append([branch_name, address, phone_number])
# 테스트 코드
print(branch_infos)