이전 데이터는 함수 형태로 모두 가져와준다. 다음은 Bayesian Optimization 을 이용한 코드만 후술할 것이다.
Bayesian Optimization
# bayesian optimization 패키지 설치
!pip install bayesian-optimization
from bayes_opt import BayesianOptimization
from sklearn.metrics import roc_auc_score
from lightgbm import LGBMClassifier함수의 입력값 search범위를 설정
bayesian_params = {
'max_depth':(6, 16), #트리 최대 깊이
'num_leaves':(24,64), #트리 하나에 최대 잎 개수
'min_child_samples': (10, 200), #하나의 잎에 최소 데이터 개수 (오버피팅 대응)
'min_child_weight': (1, 50), #하나의 잎에 최소 sum hessian
'subsample': (0.5, 1), #
'colsample_bytree': (0.5, 1), #피처의 50% 를 트레이닝 전에 선택
'max_bin': (10, 500), #bins 의 최대 개수
'reg_lambda': (0.001, 10), #L2 regularization
'reg_alpha': (0.01, 50) #L1 regularization
}
}파라미터의 숫자는 파라미터를 많이 쳐봄으로서 경험적으로 아는 수밖에 없다. 사이트 에 파라미터에 대한 정의와 설명이 모두 담겨있으니 참조하도록 하자. 일단 나와있는 것은 모두 주석으로 작성해놨다.
최대 값을 구할 함수 선언
이 함수는 하나의 반복마다 하이퍼파라미터를 입력받아 분류 학습하고 roc_auc 를 반환하는 함수이다.
def lgb_roc_eval(max_depth, num_leaves, min_child_samples, min_child_weight, subsample, colsample_bytree, max_bin, reg_lambda, reg_alpha):
params = {
"n_estimators" : 500, "learning_rate": 0.02,
'max_depth': int(round(max_depth)),
'num_leaves': int(round(num_leaves)),
'min_child_samples': int(round(min_child_samples)),
'min_child_weight': int(round(min_child_weight)),
'subsample': max(min(subsample, 1), 0), # 0 과 1 사이
'colsample_bytree': max(min(colsample_bytree, 1), 0),
'max_bin': max(int(round(max_bin)),10),
'reg_lambda': max(reg_lambda,0),
'reg_alpha': max(reg_alpha, 0)
}
lgb_model = LGBMClassifier(**params)
lgb_model.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 100)
valid_proba = lgb_model.predict_proba(valid_x)[:, 1]
roc_auc = roc_auc_score(valid_y, valid_proba)
return roc_auc실제로 학습을 할 때에는 int(round()) 를 통해 정수값으로 입력받을 수 있도록 해준다.
BayesianOptimization 객체 생성 후 함수 반환값이 최대가 되는 입력값 search 를 위한 iteration 수행
반환값 roc_auc 를 최대화하는 것이 현재의 목표다. 객체를 생성하고 init_points 와 n_iter 로 반복수를 지정해주면 최대화를 위해 객체가 달린다!
lgbBO = BayesianOptimization(f= lgb_roc_eval, pbounds=bayesian_params, random_state = 0)
lgbBO.maximize(init_points = 5, n_iter = 25)🤔 장장 1시간 30분이 넘어가는 파라미터 튜닝 시간이 걸렸다...
Iteration 수행 결과 출력
.res 는 하나의 반복을 돌 때마다 그때의 반환값과 파라미터 결과값을 기억하고 있다.
lgbBO.res
Iteration 결과 Dictionary 에서 최대 target 을 가지는 index 추출하고 그때의 parameter 추출
# dictionary에 있는 target값을 모두 추출
target_list = []
for result in lgbBO.res:
target = result['target']
target_list.append(target)
print(target_list)
# 가장 큰 target 값을 가지는 순번(index)를 추출
print('maximum target index:', np.argmax(np.array(target_list)))
# 가장 큰 target값을 가지는 index값을 기준으로 res에서 해당 parameter 추출.
max_dict = lgbBO.res[np.argmax(np.array(target_list))]
print(max_dict)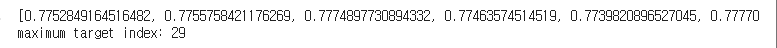
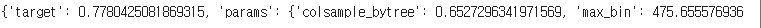
.res 로 반환값과 파라미터를 돌면서 target 값을 가져온다. 그 중 target 값이 가장 큰 index 를 추출한다. 이를 출력을 해주면 된다. index 는 np.argmax(np.array(target_list))로 가져오면 된다.
def train_apps_all(apps_all_train):
ftr_app = apps_all_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = apps_all_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
print('train shape:', train_x.shape, 'valid shape:', valid_x.shape)
clf = LGBMClassifier(
nthread=4,
n_estimators=1000,
learning_rate=0.02,
max_depth = 13,
num_leaves=57,
colsample_bytree=0.638,
subsample=0.682,
max_bin=435,
reg_alpha=0.936,
reg_lambda=4.533,
min_child_weight=25,
min_child_samples=166,
silent=-1,
verbose=-1,
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 100)
return clf
#모델 학습
apps_all = get_apps_all_with_prev_agg(apps, prev)
apps_all = get_apps_all_encoded(apps_all)
apps_all_train, apps_all_test = get_apps_all_train_test(apps_all)
clf = train_apps_all(apps_all_train)
#예측, 파일 생성.
preds = clf.predict_proba(apps_all_test.drop('SK_ID_CURR', axis=1))[:, 1 ]
apps_all_test['TARGET'] = preds
apps_all_test[['SK_ID_CURR', 'TARGET']].to_csv('prev_baseline_tuning_01.csv', index=False)
