import numpy as np
import pandas as pd
import gc
import time
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 200)
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
%cd '/content/gdrive/My Drive/'
!ls
def get_dataset():
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
apps = pd.concat([app_train, app_test])
prev = pd.read_csv('previous_application.csv')
bureau = pd.read_csv('bureau.csv')
bureau_bal = pd.read_csv('bureau_balance.csv')
return apps, prev, bureau, bureau_bal
apps, prev, bureau, bureau_bal = get_dataset()
bureau 와 bureau bal 컬럼
두 데이터 세트의 중요한 컬럼은 다음과 같다.
SK_BUREAU_ID : 타 기관 대출 고유 id
DAYS_CREDIT : 현재 대출 신청 일 기준 과거 대출 신청 지난 기간
CREDIT_DAYS_OVERDUE : 대출 신청 시 연체 일수
DAYS_CREDIT_ENDDATE : 채무 완료까지 남아있는 일수 (신청일 기준)
DAYS_ENDDATE_FACT : 채무 완료까지 실제 걸린 일수
...
AMT_CREDIT_SUM : 현재 크레딧 금액 총액
MONDTHS_BALANCE : 신청일 기준 잔액 월
STATUS : 월별 대출 상태(ACTIVE, CLOSED, DPDO-30)
EDA 수행
bureau, bureau_bal 컬럼 및 Null 조사
bureau.info()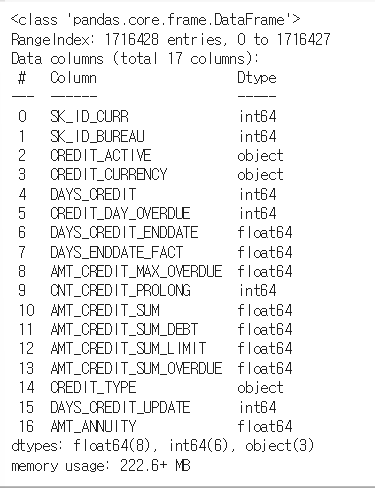
bureau 엔 다음과 같은 feature 들이 존재한다.
# DAYS_ENDDATE_FACT, AMT_CREDIT_MAX_OVERDUE, AMT_CREDIT_SUM_LIMT, AMT_ANNUITY 등이 Null 컬럼이 많음.
bureau.isnull().sum()isnull().sum() 으로 널 값을 확인해줬다. DAYS_ENDDATE_FACT, AMT_CREDIT_MAX_OVERDUE, AMT_CREDIT_SUM_LIMIT, AMT_ANNUITY 등 널 값을 크게 갖는 컬럼들이 존재했다. 처리가 필요해보인다.
bureau_bal.info()bureau_bal 의 컬럼도 보자. bureau_bal 은 3개의 feature 로 구성되어 있다. 행의 수는 굉장히 많다.
bureau_bal.head(30)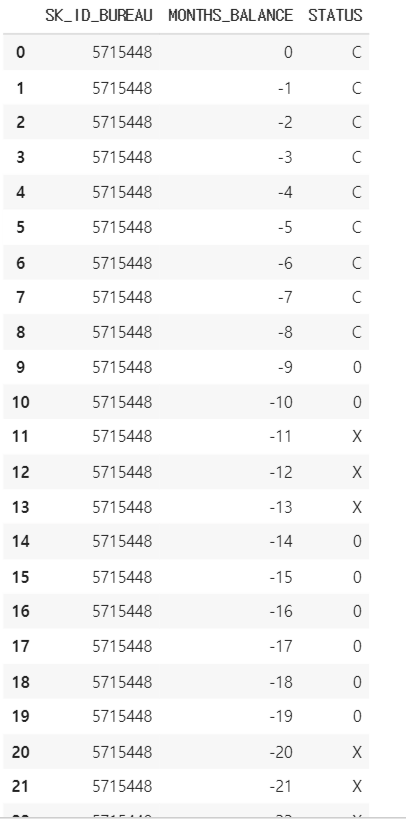
SK_ID 가 중복으로 들어가 있고, MONTHS_BALANCE 는 돈을 갚아나간 월 차를 의미한다. STATUS 는 냈으면 C, 0은 연체 없음, X는 연체를 뜻한다.
Target 에 따른 숫자형 피처 비교
bureau 의 정보를 target 과 함께 보고싶다. 이를 위해 apps 에서 아이디와 target 을 가져와 아이디를 기준으로 병합해보자. 새로운 bureau_app 을 만든다.
# TARGET 값을 가져오기 위해 bureau를 apps와 조인
bureau_app = bureau.merge(apps[['SK_ID_CURR', 'TARGET']], on='SK_ID_CURR', how='left')bureau_app 은 이제 아이디 기준으로 bureau 와 target 을 결합한 데이터프레임이다. 거기서 .dtypes 가 객체가 아닌 것들을 (숫자형 컬럼) 가져와 num_columns 에 저장하고 시각화한다.
#숫자형 컬럼 가져와 리스트
num_columns = bureau_app.dtypes[bureau_app.dtypes != 'object'].index.tolist()
# 숫자형 컬럼중 ID와 TARGET은 제외
num_columns = [column for column in num_columns if column not in['SK_ID_BUREAU', 'SK_ID_CURR', 'TARGET']]
print(num_columns)
def show_hist_by_target(df, columns):
cond_1 = (df['TARGET'] == 1)
cond_0 = (df['TARGET'] == 0)
for column in columns:
print("column:", column)
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), squeeze=False)
# bureau는 특정 컬럼값이 infinite로 들어가있는 경우가 있음. infinite일 경우 KDE histogram 시각화 시 문제 발생하여 이를 제거
sns.violinplot(x='TARGET', y=column, data=df[np.isfinite(df[column])], ax=axs[0][0])
sns.distplot(df[cond_0 & np.isfinite(df[column])][column], label='0', color='blue', ax=axs[0][1])
sns.distplot(df[cond_1 & np.isfinite(df[column])][column], label='1', color='red', ax=axs[0][1])
show_hist_by_target(bureau_app, num_columns)기존 시각화의 경우 x = 'TARGET' 이고 y = column, data = df 였지만 bureau 에 infinite 값이 많아 시각화시에 오류를 일으킬 수 있어서 finite 만 건져주기로 했다.
data = df[np.isfinite(df[column])]
df[cond_0 & np.isfinite(df[column])][column]
으로 해결해 줄 수 있다.
가장 주목할만한 DAYS_CREDIT 의 경우 TARGET 값이 1일 때 상대적으로 최근 값이 많았다. 나머지 feature 은 특이점이 없었다.
TARGET 유형에 따라 카테고리 피처 비교
이번엔 dtypes == 'object' 인 것들만 불러오자. ojbect 의 경우 이전에도 그랬듯 sns.catplot(x = column , col = 'TARGET', data = df, kind = 'count') 를 이용해준다.
object_columns = bureau.dtypes[bureau.dtypes=='object'].index.tolist()
print(object_columns)
def show_category_by_target(df, columns):
for column in columns:
chart = sns.catplot(x=column, col="TARGET", data=df, kind="count")
chart.set_xticklabels(rotation=65)
show_category_by_target(bureau_app, object_columns)CREDIT_ACITVE 의 경우 TARGET 값이 1일 때 상대적으로 Active 인 비율이 더 높았다.
나머지는 의미있는 컬럼을 찾기가 힘들었다.
bureau feature engineering
채무 완료 날짜 및 대출 금액 대비 채무 금액 관련 가공
# 예정 채무 시작 및 완료일과 실제 채무 완료일간의 차이 및 날짜 비율 가공.
bureau['BUREAU_ENDDATE_FACT_DIFF'] = bureau['DAYS_CREDIT_ENDDATE'] - bureau['DAYS_ENDDATE_FACT'] #갚기로 예정된 날짜 - 실제 완료일
bureau['BUREAU_CREDIT_FACT_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_ENDDATE_FACT'] #빌린 날짜 - 실제 갚은 날
bureau['BUREAU_CREDIT_ENDDATE_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_CREDIT_ENDDATE'] #빌린 날짜 - 갚기로 예정된 날짜
# 채무 금액 대비/대출 금액 비율 및 차이 가공
bureau['BUREAU_CREDIT_DEBT_RATIO']=bureau['AMT_CREDIT_SUM_DEBT']/bureau['AMT_CREDIT_SUM'] #채무 금액 / 대출 금액
bureau['BUREAU_CREDIT_DEBT_DIFF'] = bureau['AMT_CREDIT_SUM_DEBT'] - bureau['AMT_CREDIT_SUM'] #채무 금액 - 대출 금액 다음과 같이 가공했다. 모두 주석을 달아뒀으니 이해해보자.
연체 일수 관련 가공
연체 일수는 CREDIT_DAY_OVERDUE 컬럼에 나타나 있었다.
# 연체 건수가 많지 않음.
bureau['CREDIT_DAY_OVERDUE'].value_counts()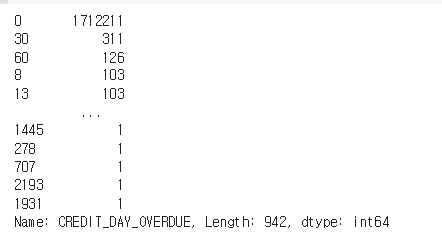
전체 중 연체가 없는 것이 훨씬 많았다!
연체인지, 연체라면 연체가 120일 이상인지 컬럼을 각각 BUREAU_IS_DPD, BUREAU_IS_DPD_OVER120 에 가공해줬다.
bureau['BUREAU_IS_DPD'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x > 0 else 0)
bureau['BUREAU_IS_DPD'].value_counts()
bureau['BUREAU_IS_DPD_OVER120'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x >120 else 0)
bureau['BUREAU_IS_DPD_OVER120'].value_counts()

이렇게 지정하면 연체는 1, 연체 아님은 0, 120 넘은 연체는 1, 아닌 것은 0 으로 각 컬럼에 들어가게 된다.
기존 주요 컬럼과 가공 컬럼으로 agg 컬럼 생성
groupby 와 agg 를 통해 추가 여러 칼럼을 생성해보자. 주로 min, max, mean 을 사용하고 , 방금 구한 BUREAU_IS_DPD, BUREAU_IS_DPD_OVER120 는 0과 1로 여부를 표시해뒀으므로 mean 은 연체 사람 수의 평균, sum 은 총 연체 사람 수를 알 수 있겠으므로 mean sum 을 이용해줬다.
bureau_agg_dict = {
# 기존 컬럼
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'], #예정-실제 갚은 날 차이
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'], #빌린 - 실제 갚은 날 차이
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'], #빌린 - 예정 차이
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'], #채무 / 대출
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'], #채무 - 대출
'BUREAU_IS_DPD':['mean', 'sum'], #연체일수 0 이상 (평균, 합: 몇 명이 연체인지)
'BUREAU_IS_DPD_OVER120':['mean', 'sum'] #연체일수 120 이상 (평균, 합: 몇 명이 120 이상 연체인지)
}
#groupby 중간자 생성하고 .agg(딕셔너리)
bureau_grp = bureau.groupby('SK_ID_CURR')
bureau_day_amt_agg = bureau_grp.agg(bureau_agg_dict)
# BUREAU_ 접두어로 하는 새로운 컬럼명 할당.
bureau_day_amt_agg.columns = ['BUREAU_'+('_').join(column).upper() for column in bureau_day_amt_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_day_amt_agg = bureau_day_amt_agg.reset_index()
print(bureau_day_amt_agg.shape)현재 대출 중 Active 인 건만 별도로 Groupby 수행
cond_active = bureau['CREDIT_ACTIVE'] == 'Active'
bureau_active_grp = bureau[cond_active].groupby('SK_ID_CURR')
bureau_agg_dict = {
# 기존 컬럼
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'],
'BUREAU_IS_DPD':['mean', 'sum'],
'BUREAU_IS_DPD_OVER120':['mean', 'sum']
}
bureau_active_agg = bureau_active_grp.agg(bureau_agg_dict)
# BUREAU_ACT을 접두어로 하는 새로운 컬럼명 할당.
bureau_active_agg.columns = ['BUREAU_ACT_'+('_').join(column).upper() for column in bureau_active_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_active_agg = bureau_active_agg.reset_index()
print(bureau_active_agg.shape)
bureau_active_agg.head(10)bureau 에서 CREDIT_ACTIVE가 Active인 건만 모아서 groupby 를 수행해보자. 그리고 컬럼 이름을 정리하고 reset_index() 로 정리해준 다음 bureau_active_agg 를 만들어준다.
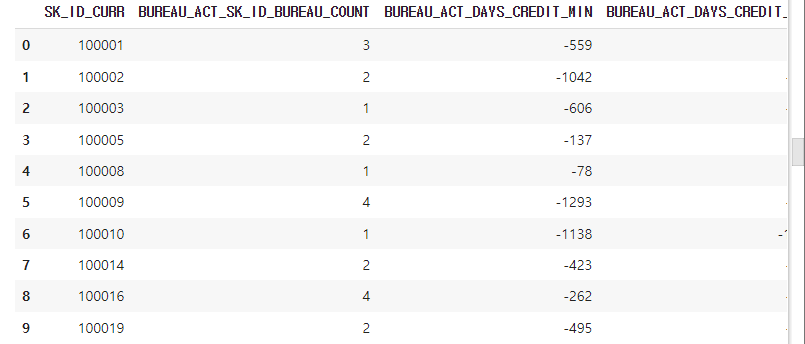
위의 해당 정보들이 들어간 데이터 프레임이 완성되었다!
bureau 전체 가공 프레임인 bureau_day_amt_agg 를 기준으로 bureau_active_agg 를 left 조인 해준다. 최종 프레임은 bureau_agg 로 한다.
bureau_agg = bureau_day_amt_agg.merge(bureau_active_agg, on='SK_ID_CURR', how='left')
bureau_agg.head(20)
아이디 별로 건수 대비 연체 비율 계산
bureau_agg 추가가공을 더 해보자.
# SK_ID_CURR 레벨로 DPD 비율, DPD > 120 비율 확률, Active 상태에서 DPD 비율, DPD > 120 비율 확률
bureau_agg['BUREAU_IS_DPD_RATIO'] = bureau_agg['BUREAU_BUREAU_IS_DPD_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
bureau_agg['BUREAU_IS_DPD_OVER120_RATIO'] = bureau_agg['BUREAU_BUREAU_IS_DPD_OVER120_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
bureau_agg['BUREAU_ACT_IS_DPD_RATIO'] = bureau_agg['BUREAU_ACT_BUREAU_IS_DPD_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']
bureau_agg['BUREAU_ACT_IS_DPD_OVER120_RATIO'] = bureau_agg['BUREAU_ACT_BUREAU_IS_DPD_OVER120_SUM']/bureau_agg['BUREAU_SK_ID_BUREAU_COUNT']아이디 별로 연체 비율, 120 연체 비율, active 일 때 연체 비율, 120 연체 비율을 계산해줬다.
breau_bal 주요 컬럼으로 agg 컬럼 생성
이번엔 bureau_bal 을 가공해보자. bureau 에 SK_ID_CURR 이 없으므로 가져오고, 조인해준다.
# bureau_bal과 bureau join
bureau_bal = bureau_bal.merge(bureau[['SK_ID_CURR', 'SK_ID_BUREAU']], on='SK_ID_BUREAU', how='left')
STATUS 는 다음과 같다.
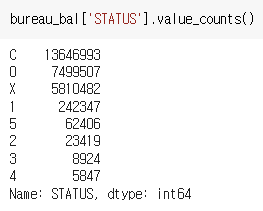
STATUS 가 1,2,3,4,5 면 1로, 아니면 0으로 하는 값을 BUREAU_BAL_IS_DPD 에 넣어주고, STATUS 가 5이면 1, 아니면 0 으로 하는 값을 BUREAU_BAL_IS_DPD_OVER120 에 넣어준다.
bureau_bal['BUREAU_BAL_IS_DPD'] = bureau_bal['STATUS'].apply(lambda x: 1 if x in['1','2','3','4','5'] else 0)
bureau_bal['BUREAU_BAL_IS_DPD_OVER120'] = bureau_bal['STATUS'].apply(lambda x: 1 if x =='5' else 0)
bureau_bal['BUREAU_BAL_IS_DPD'].value_counts()
bureau_bal['BUREAU_BAL_IS_DPD_OVER120'].value_counts()
또한 groupby 중간자 만들고 agg 컬럼 만드는 것도 수행해준다. 최종은 bureau_bal_agg에 담았다.
# SK_ID_CURR 레벨로 건수와 MONTHS_BALANCE의 aggregation 가공
bureau_bal_agg_dict = {
'SK_ID_CURR':['count'],
'MONTHS_BALANCE':['min', 'max', 'mean'],
'BUREAU_BAL_IS_DPD':['mean', 'sum'],
'BUREAU_BAL_IS_DPD_OVER120':['mean', 'sum']
}
bureau_bal_grp = bureau_bal.groupby('SK_ID_CURR')
bureau_bal_agg = bureau_bal_grp.agg(bureau_bal_agg_dict)
# BUREAU_BAL을 접두어로 하는 새로운 컬럼명 할당.
bureau_bal_agg.columns = [ 'BUREAU_BAL_'+('_').join(column).upper() for column in bureau_bal_agg.columns.ravel() ]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_bal_agg = bureau_bal_agg.reset_index()
print(bureau_bal_agg.shape)
bureau_bal_agg.head()
bureau_bal_agg 도 앞서 burea_agg 처럼 비율 가공도 해주었다. 최종적으로 둘을 조인해준 것은 bureau_agg 에 넣어줬다.
# SK_ID_CURR 레벨로 DPD 비율, DPD > 120 비율 가공
bureau_bal_agg['BUREAU_BAL_IS_DPD_RATIO'] = bureau_bal_agg['BUREAU_BAL_BUREAU_BAL_IS_DPD_SUM']/bureau_bal_agg['BUREAU_BAL_SK_ID_CURR_COUNT']
bureau_bal_agg['BUREAU_BAL_IS_DPD_OVER120_RATIO'] = bureau_bal_agg['BUREAU_BAL_BUREAU_BAL_IS_DPD_OVER120_SUM']/bureau_bal_agg['BUREAU_BAL_SK_ID_CURR_COUNT']
##### bureau_day_amt_agg, bureau_bal_agg 조인.
bureau_agg = bureau_day_amt_agg.merge(bureau_active_agg, on='SK_ID_CURR', how='left')
bureau_agg = bureau_agg.merge(bureau_bal_agg, on='SK_ID_CURR', how='left')최종 함수화
먼저 bureau 와 bureau_day_amt_agg, bureau_active_agg, bureau_bal_agg 를 받아와 결합하는 함수다. 최종적으론 bureau_agg 를 리턴한다.
# bureau 채무 완료 날짜 및 대출 금액 대비 채무 금액 관련 컬럼 가공.
def get_bureau_processed(bureau):
# 예정 채무 시작 및 완료일과 실제 채무 완료일간의 차이 및 날짜 비율 가공.
bureau['BUREAU_ENDDATE_FACT_DIFF'] = bureau['DAYS_CREDIT_ENDDATE'] - bureau['DAYS_ENDDATE_FACT']
bureau['BUREAU_CREDIT_FACT_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_ENDDATE_FACT']
bureau['BUREAU_CREDIT_ENDDATE_DIFF'] = bureau['DAYS_CREDIT'] - bureau['DAYS_CREDIT_ENDDATE']
# 채무 금액 대비/대출 금액 비율 및 차이 가공
bureau['BUREAU_CREDIT_DEBT_RATIO']=bureau['AMT_CREDIT_SUM_DEBT']/bureau['AMT_CREDIT_SUM']
#bureau['BUREAU_CREDIT_DEBT_DIFF'] = bureau['AMT_CREDIT_SUM'] - bureau['AMT_CREDIT_SUM_DEBT']
bureau['BUREAU_CREDIT_DEBT_DIFF'] = bureau['AMT_CREDIT_SUM_DEBT'] - bureau['AMT_CREDIT_SUM']
#연체 여부 및 120일 연체 여부 가공
bureau['BUREAU_IS_DPD'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x > 0 else 0)
bureau['BUREAU_IS_DPD_OVER120'] = bureau['CREDIT_DAY_OVERDUE'].apply(lambda x: 1 if x >120 else 0)
return bureau
# bureau 주요 컬럼 및 앞에서 채무 및 대출금액 관련 컬럼들로 SK_ID_CURR 레벨의 aggregation 컬럼 생성.
def get_bureau_day_amt_agg(bureau):
bureau_agg_dict = {
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'],
'BUREAU_IS_DPD':['mean', 'sum'],
'BUREAU_IS_DPD_OVER120':['mean', 'sum']
}
bureau_grp = bureau.groupby('SK_ID_CURR')
bureau_day_amt_agg = bureau_grp.agg(bureau_agg_dict)
bureau_day_amt_agg.columns = ['BUREAU_'+('_').join(column).upper() for column in bureau_day_amt_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_day_amt_agg = bureau_day_amt_agg.reset_index()
print('bureau_day_amt_agg shape:', bureau_day_amt_agg.shape)
return bureau_day_amt_agg
# Bureau의 CREDIT_ACTIVE='Active' 인 데이터만 filtering 후 주요 컬럼 및 앞에서 채무 및 대출금액 관련 컬럼들로 SK_ID_CURR 레벨의 aggregation 컬럼 생성
def get_bureau_active_agg(bureau):
# CREDIT_ACTIVE='Active' 인 데이터만 filtering
cond_active = bureau['CREDIT_ACTIVE'] == 'Active'
bureau_active_grp = bureau[cond_active].groupby(['SK_ID_CURR'])
bureau_agg_dict = {
'SK_ID_BUREAU':['count'],
'DAYS_CREDIT':['min', 'max', 'mean'],
'CREDIT_DAY_OVERDUE':['min', 'max', 'mean'],
'DAYS_CREDIT_ENDDATE':['min', 'max', 'mean'],
'DAYS_ENDDATE_FACT':['min', 'max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['max', 'mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean', 'sum'],
# 추가 가공 컬럼
'BUREAU_ENDDATE_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_FACT_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_ENDDATE_DIFF':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_RATIO':['min', 'max', 'mean'],
'BUREAU_CREDIT_DEBT_DIFF':['min', 'max', 'mean'],
'BUREAU_IS_DPD':['mean', 'sum'],
'BUREAU_IS_DPD_OVER120':['mean', 'sum']
}
bureau_active_agg = bureau_active_grp.agg(bureau_agg_dict)
bureau_active_agg.columns = ['BUREAU_ACT_'+('_').join(column).upper() for column in bureau_active_agg.columns.ravel()]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_active_agg = bureau_active_agg.reset_index()
print('bureau_active_agg shape:', bureau_active_agg.shape)
return bureau_active_agg
# bureau_bal을 SK_ID_CURR 레벨로 건수와 MONTHS_BALANCE의 aggregation 가공
def get_bureau_bal_agg(bureau, bureau_bal):
bureau_bal = bureau_bal.merge(bureau[['SK_ID_CURR', 'SK_ID_BUREAU']], on='SK_ID_BUREAU', how='left')
bureau_bal['BUREAU_BAL_IS_DPD'] = bureau_bal['STATUS'].apply(lambda x: 1 if x in['1','2','3','4','5'] else 0)
bureau_bal['BUREAU_BAL_IS_DPD_OVER120'] = bureau_bal['STATUS'].apply(lambda x: 1 if x =='5' else 0)
bureau_bal_grp = bureau_bal.groupby('SK_ID_CURR')
# SK_ID_CURR 레벨로 건수와 MONTHS_BALANCE의 aggregation 가공
bureau_bal_agg_dict = {
'SK_ID_CURR':['count'],
'MONTHS_BALANCE':['min', 'max', 'mean'],
'BUREAU_BAL_IS_DPD':['mean', 'sum'],
'BUREAU_BAL_IS_DPD_OVER120':['mean', 'sum']
}
bureau_bal_agg = bureau_bal_grp.agg(bureau_bal_agg_dict)
bureau_bal_agg.columns = [ 'BUREAU_BAL_'+('_').join(column).upper() for column in bureau_bal_agg.columns.ravel() ]
# 조인을 위해 SK_ID_CURR을 reset_index()로 컬럼화
bureau_bal_agg = bureau_bal_agg.reset_index()
print('bureau_bal_agg shape:', bureau_bal_agg.shape)
return bureau_bal_agg
# 가공된 bureau관련 aggregation 컬럼들을 모두 결합
def get_bureau_agg(bureau, bureau_bal):
bureau = get_bureau_processed(bureau)
bureau_day_amt_agg = get_bureau_day_amt_agg(bureau)
bureau_active_agg = get_bureau_active_agg(bureau)
bureau_bal_agg = get_bureau_bal_agg(bureau, bureau_bal)
# 가공된 bureau관련 aggregation 컬럼들을 모두 조인하여 결합 후 return
bureau_agg = bureau_day_amt_agg.merge(bureau_active_agg, on='SK_ID_CURR', how='left')
bureau_agg = bureau_agg.merge(bureau_bal_agg, on='SK_ID_CURR', how='left')
print('bureau_agg shape:', bureau_agg.shape)
return bureau_agg다음은 기존 application, previous 데이터 가공 코드이다.
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
def get_apps_processed(apps):
# EXT_SOURCE_X FEATURE 가공
apps['APPS_EXT_SOURCE_MEAN'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].mean(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']].std(axis=1)
apps['APPS_EXT_SOURCE_STD'] = apps['APPS_EXT_SOURCE_STD'].fillna(apps['APPS_EXT_SOURCE_STD'].mean())
# AMT_CREDIT 비율로 Feature 가공
apps['APPS_ANNUITY_CREDIT_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_CREDIT']
apps['APPS_GOODS_CREDIT_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_CREDIT']
# AMT_INCOME_TOTAL 비율로 Feature 가공
apps['APPS_ANNUITY_INCOME_RATIO'] = apps['AMT_ANNUITY']/apps['AMT_INCOME_TOTAL']
apps['APPS_CREDIT_INCOME_RATIO'] = apps['AMT_CREDIT']/apps['AMT_INCOME_TOTAL']
apps['APPS_GOODS_INCOME_RATIO'] = apps['AMT_GOODS_PRICE']/apps['AMT_INCOME_TOTAL']
apps['APPS_CNT_FAM_INCOME_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['CNT_FAM_MEMBERS']
# DAYS_BIRTH, DAYS_EMPLOYED 비율로 Feature 가공
apps['APPS_EMPLOYED_BIRTH_RATIO'] = apps['DAYS_EMPLOYED']/apps['DAYS_BIRTH']
apps['APPS_INCOME_EMPLOYED_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_EMPLOYED']
apps['APPS_INCOME_BIRTH_RATIO'] = apps['AMT_INCOME_TOTAL']/apps['DAYS_BIRTH']
apps['APPS_CAR_BIRTH_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_BIRTH']
apps['APPS_CAR_EMPLOYED_RATIO'] = apps['OWN_CAR_AGE'] / apps['DAYS_EMPLOYED']
return apps
def get_prev_processed(prev):
# 대출 신청 금액과 실제 대출액/대출 상품금액 차이 및 비율
prev['PREV_CREDIT_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_CREDIT']
prev['PREV_GOODS_DIFF'] = prev['AMT_APPLICATION'] - prev['AMT_GOODS_PRICE']
prev['PREV_CREDIT_APPL_RATIO'] = prev['AMT_CREDIT']/prev['AMT_APPLICATION']
# prev['PREV_ANNUITY_APPL_RATIO'] = prev['AMT_ANNUITY']/prev['AMT_APPLICATION']
prev['PREV_GOODS_APPL_RATIO'] = prev['AMT_GOODS_PRICE']/prev['AMT_APPLICATION']
prev['DAYS_FIRST_DRAWING'].replace(365243, np.nan, inplace= True)
prev['DAYS_FIRST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE_1ST_VERSION'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_TERMINATION'].replace(365243, np.nan, inplace= True)
# 첫번째 만기일과 마지막 만기일까지의 기간
prev['PREV_DAYS_LAST_DUE_DIFF'] = prev['DAYS_LAST_DUE_1ST_VERSION'] - prev['DAYS_LAST_DUE']
# 매월 납부 금액과 납부 횟수 곱해서 전체 납부 금액 구함.
all_pay = prev['AMT_ANNUITY'] * prev['CNT_PAYMENT']
# 전체 납부 금액 대비 AMT_CREDIT 비율을 구하고 여기에 다시 납부횟수로 나누어서 이자율 계산.
prev['PREV_INTERESTS_RATE'] = (all_pay/prev['AMT_CREDIT'] - 1)/prev['CNT_PAYMENT']
return prev
def get_prev_amt_agg(prev):
# 새롭게 생성된 대출 신청액 대비 다른 금액 차이 및 비율로 aggregation 수행.
agg_dict = {
# 기존 컬럼 aggregation.
'SK_ID_CURR':['count'],
'AMT_CREDIT':['mean', 'max', 'sum'],
'AMT_ANNUITY':['mean', 'max', 'sum'],
'AMT_APPLICATION':['mean', 'max', 'sum'],
'AMT_DOWN_PAYMENT':['mean', 'max', 'sum'],
'AMT_GOODS_PRICE':['mean', 'max', 'sum'],
'RATE_DOWN_PAYMENT': ['min', 'max', 'mean'],
'DAYS_DECISION': ['min', 'max', 'mean'],
'CNT_PAYMENT': ['mean', 'sum'],
# 가공 컬럼 aggregation
'PREV_CREDIT_DIFF':['mean', 'max', 'sum'],
'PREV_CREDIT_APPL_RATIO':['mean', 'max'],
'PREV_GOODS_DIFF':['mean', 'max', 'sum'],
'PREV_GOODS_APPL_RATIO':['mean', 'max'],
'PREV_DAYS_LAST_DUE_DIFF':['mean', 'max', 'sum'],
'PREV_INTERESTS_RATE':['mean', 'max']
}
prev_group = prev.groupby('SK_ID_CURR')
prev_amt_agg = prev_group.agg(agg_dict)
# multi index 컬럼을 '_'로 연결하여 컬럼명 변경
prev_amt_agg.columns = ["PREV_"+ "_".join(x).upper() for x in prev_amt_agg.columns.ravel()]
return prev_amt_agg
def get_prev_refused_appr_agg(prev):
# 원래 groupby 컬럼 + 세부 기준 컬럼으로 groupby 수행. 세분화된 레벨로 aggregation 수행 한 뒤에 unstack()으로 컬럼레벨로 변형.
prev_refused_appr_group = prev[prev['NAME_CONTRACT_STATUS'].isin(['Approved', 'Refused'])].groupby([ 'SK_ID_CURR', 'NAME_CONTRACT_STATUS'])
prev_refused_appr_agg = prev_refused_appr_group['SK_ID_CURR'].count().unstack()
# 컬럼명 변경.
prev_refused_appr_agg.columns = ['PREV_APPROVED_COUNT', 'PREV_REFUSED_COUNT' ]
# NaN값은 모두 0으로 변경.
prev_refused_appr_agg = prev_refused_appr_agg.fillna(0)
return prev_refused_appr_agg
def get_prev_agg(prev):
prev = get_prev_processed(prev)
prev_amt_agg = get_prev_amt_agg(prev)
prev_refused_appr_agg = get_prev_refused_appr_agg(prev)
# prev_amt_agg와 조인.
prev_agg = prev_amt_agg.merge(prev_refused_appr_agg, on='SK_ID_CURR', how='left')
# SK_ID_CURR별 과거 대출건수 대비 APPROVED_COUNT 및 REFUSED_COUNT 비율 생성.
prev_agg['PREV_REFUSED_RATIO'] = prev_agg['PREV_REFUSED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
prev_agg['PREV_APPROVED_RATIO'] = prev_agg['PREV_APPROVED_COUNT']/prev_agg['PREV_SK_ID_CURR_COUNT']
# 'PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT' 컬럼 drop
prev_agg = prev_agg.drop(['PREV_REFUSED_COUNT', 'PREV_APPROVED_COUNT'], axis=1)
return prev_agg
def get_apps_all_with_prev_agg(apps, prev):
apps_all = get_apps_processed(apps)
prev_agg = get_prev_agg(prev)
print('prev_agg shape:', prev_agg.shape)
print('apps_all before merge shape:', apps_all.shape)
apps_all = apps_all.merge(prev_agg, on='SK_ID_CURR', how='left')
print('apps_all after merge with prev_agg shape:', apps_all.shape)
return apps_all
def get_apps_all_encoded(apps_all):
object_columns = apps_all.dtypes[apps_all.dtypes == 'object'].index.tolist()
for column in object_columns:
apps_all[column] = pd.factorize(apps_all[column])[0]
return apps_all
def get_apps_all_train_test(apps_all):
apps_all_train = apps_all[~apps_all['TARGET'].isnull()]
apps_all_test = apps_all[apps_all['TARGET'].isnull()]
apps_all_test = apps_all_test.drop('TARGET', axis=1)
return apps_all_train, apps_all_test
def train_apps_all(apps_all_train):
ftr_app = apps_all_train.drop(['SK_ID_CURR', 'TARGET'], axis=1)
target_app = apps_all_train['TARGET']
train_x, valid_x, train_y, valid_y = train_test_split(ftr_app, target_app, test_size=0.3, random_state=2020)
print('train shape:', train_x.shape, 'valid shape:', valid_x.shape)
clf = LGBMClassifier(
nthread=4,
n_estimators=2000,
learning_rate=0.02,
max_depth = 11,
num_leaves=58,
colsample_bytree=0.613,
subsample=0.708,
max_bin=407,
reg_alpha=3.564,
reg_lambda=4.930,
min_child_weight= 6,
min_child_samples=165,
silent=-1,
verbose=-1,
)
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], eval_metric= 'auc', verbose= 100,
early_stopping_rounds= 200)
return clfapps_all 과 prev_agg, bureau_agg 를 결합하자.
def get_apps_all_with_prev_bureau_agg(apps, prev, bureau, bureau_bal):
#지금까지 한 3개
apps_all = get_apps_processed(apps)
prev_agg = get_prev_agg(prev)
bureau_agg = get_bureau_agg(bureau, bureau_bal)
print('prev_agg shape:', prev_agg.shape)
print('bueau_agg shape:', bureau_agg.shape)
print('apps_all before merge shape:', apps_all.shape)
#apps_all 기준 조인
apps_all = apps_all.merge(prev_agg, on='SK_ID_CURR', how='left')
apps_all = apps_all.merge(bureau_agg, on='SK_ID_CURR', how='left')
print('apps_all after merge with prev_agg, bureau_agg shape:', apps_all.shape)
return apps_all학습 수행
apps, prev, bureau, bureau_bal = get_dataset()
# application, previous, bureau, bureau_bal 관련 데이터셋 가공 및 취합.
apps_all = get_apps_all_with_prev_bureau_agg(apps, prev, bureau, bureau_bal)
# Category 컬럼을 모두 Label 인코딩 수행.
apps_all = get_apps_all_encoded(apps_all)
# 학습과 테스트 데이터로 분리.
apps_all_train, apps_all_test = get_apps_all_train_test(apps_all)
#학습수행.
clf = train_apps_all(apps_all_train)데이터 셋을 모두 가져와 인코딩하고, 분리하고 학습 수행하는 코드이다.
preds = clf.predict_proba(apps_all_test.drop(['SK_ID_CURR'], axis=1))[:, 1 ]
apps_all_test['TARGET'] = preds
apps_all_test[['SK_ID_CURR', 'TARGET']].to_csv('bureau_baseline_01.csv', index=False)이제 예측한 값을 apps_all_test 에 넣고 파일로 만들면 된다.

