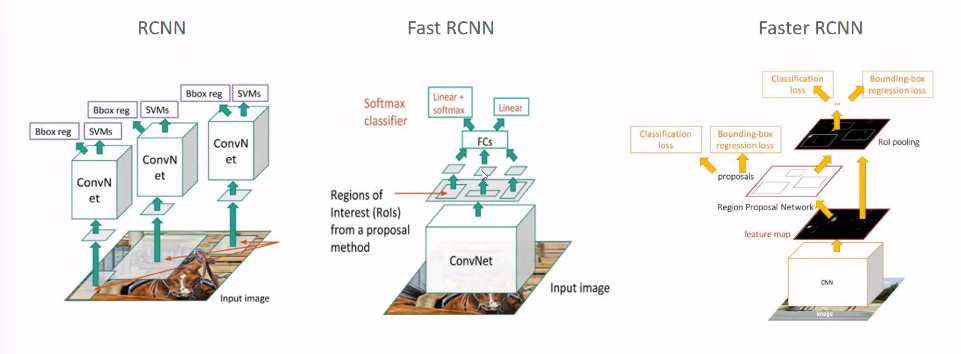
Faster RCNN
Faster RCNN = RPN + Fast RCNN
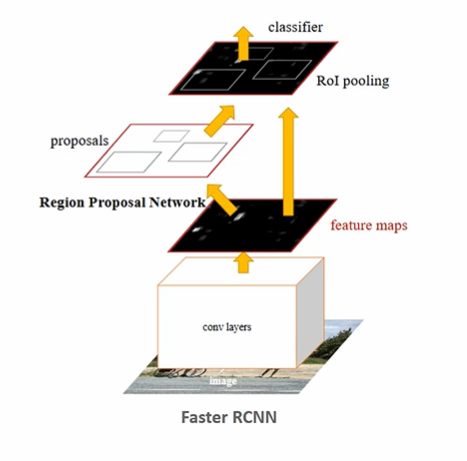
Selective Search 를 통해 ROI 를 만드는 부분을 RPN 으로 구성한 모델이다. 따라서 비로소 딥러닝만으로 Object Detection 을 구성하는 것이 가능해졌다.
📚 목차
Faster RCNN
- anchor box
- RPN
- Training
- 성능비교
Faster RCNN 구조
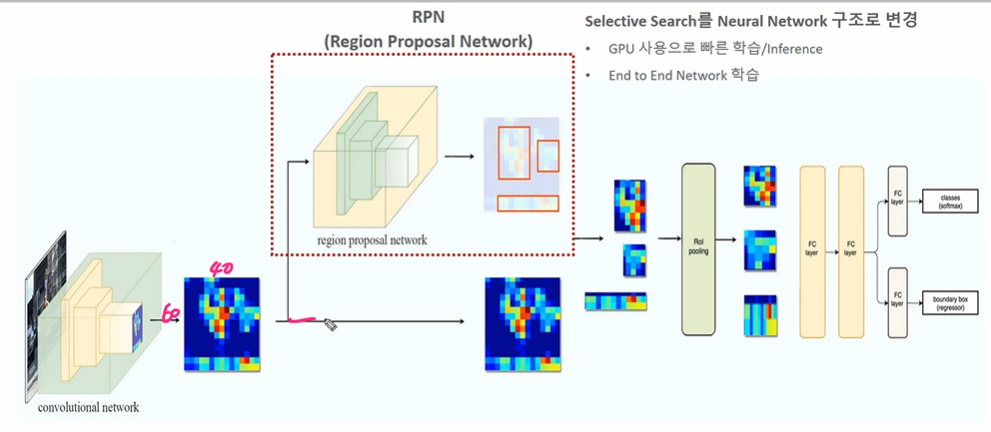
- CNN 연산을 통해 피처맵 추출
2-1. RPN
Region Proposal Network 를 통해 Object가 있을만한 위치를 찾아준다. (기존 2000개인 proposal 을 800개로 줄이면서도 성능 향상)
2-2. 찾은 region proposal 을 feature map에 ROI pooling 수행하여 고정된 크기의 feature map 을 얻는다.
- ROI Pooling 부터 마지막까지는 Fast RCNN 과 동일
따라서 SS를 딥러닝 네트워크로 변경했다는 점이 눈에 띤다.
✅ Region Proposal Network 구현 이슈
데이터로 주어질 피쳐는 픽셀 값, target 은 GT bounding box인데 이를 어떻게 region proposal 할 것인가? -> Anchor Box!
앵커박스란 박스를 촘촘하게 채운 네모박스들을 뜻한다. 여기에 데이터를 넣은 후 학습을 시키는 방식을 RPN 이라고 하고, 도드라지는 앵커박스를 기반으로 학습한다.
1. Anchor Box
(추가) 앵커의 도입이유 ➡️ 딥러닝이라고 하더라도 GT 박스에 대한 정보를 가지고만 Predict 하기엔 성능이 너무 떨어진다. 결국엔 어떤 정보를 추가로 더 주어 이를 기반으로한 예측이 필요하며, 그것이 지난번까지 도입된 SS였다. (RCNN, Fast RCNN) 그러나 SS의 경우 딥러닝 네트워크에 포함되지 않는 별개의 알고리즘으로 효율성이 떨어진다. 그래서 앵커 박스를 도입해서, 후보 박스를 만들고, 앵커도 학습시키고 (RPN) 그 중 선택하는 알고리즘 도한 훈련시켜 Object Detection 을 수행하는 것이다.
앵커는 총 9개의 Anchor box, 3개의 서로 다른 크기, 3개의 서로 다른 ratio 로 구성된다.
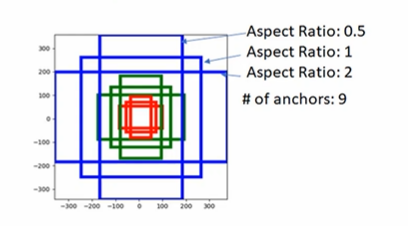
- Ratio 2라는 것은 세로가 가로의 2배라는 것, 0.5 라는 것은 가로가 세로의 2배라는 것이다.
- 이렇게 다양한 비율의 앵커박스를 설정하는 이유는 결국 Object 가 앵커박스에 정확히 잘 들어올 확률을 높이기 위해서다.
결국 앵커박스는 만들어진 피처맵에 적용되는 것이며, 포인트를 기준으로 하나의 포인트에 위의 9개의 앵박스를 만들게 된다. 아래의 그림을 참고하자.

피처맵에서 가로 50, 세로 38의 포인트가 나올 때 50 X 38 = 1900개의 앵커박스 포인트(그리드)가 만들어지게 되고, 앵커박스는 여기에 X9 = 17100개가 만들어진다. 각 포인트에서 9개의 앵커박스를 만든다는 것! 결국 앵커박스끼리의 영역또한 겹치게 되므로

앵커박스 구성 -> 특정 한 점에서의 앵커박스 -> 모든 그리드 셀에서 앵커박스 적용한 사진이다.
2. RPN
이전 Fast RCNN 의 경우 피처맵에 SS에서 구한 ROI 영역을 매핑시켰다. 그러나 Faster RCNN 의 경우, RPN 을 적용하게 된다. RPN 은 피처맵을 입력받아 앵커에 대한 clas score, bounding box reggresion 2개를 반환한다.
RPN역시 영역을 추천하는 네트워크인데, 어떻게 가능할까?
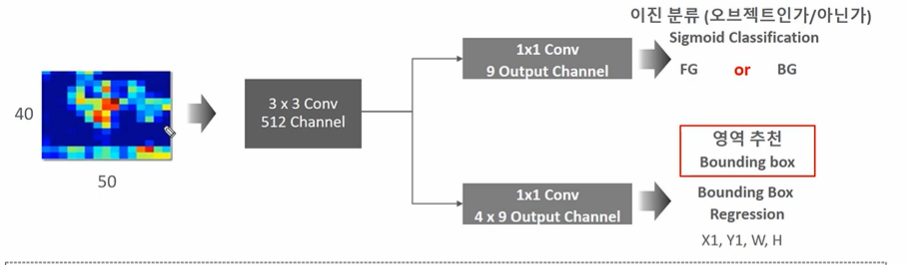
- 3 X 3 conv 연산을 적용한다. (결과로 40 X 50 X 512)
2-1. 1 X 1 conv 연산으로 오브젝트인지, 아닌지 이진분류를 하게된다. (class score)
- FG or BG
- Sigmoid Classification
- 9 X 9 output channel 로 변환하게 된다. (40, 50, 9) 만큼의 anchor 박스별로 object 인지 아닌지 판단
- 후에 loss 를 확인하면 알겠지만 앵커가 Objective 인 확률, 실제 GT의 여부를 loss로 분류에 있어서 정확도를 높인다. -> 아래 ✅ RPN Loss에서 확인하자.
2-2. 1 X 1 conv 연산으로 영역추천을 하게된다. (bounding box regression)
- 4 X 9 채널. (40, 50, 9, 4) 만큼의 앵커박스별로 회귀를 하게된다. -> 좌상단 우하단 4개
- 후에 loss 를 확인하면 알겠지만 GT와 positive anchor, predict 와 positive anchor 사이 거리를 동일하게 맞추는 방식으로 예측에 있어서 정확도를 올린다. - > 아래 ✅ RPN Loss와 ✅ RPN Bounding Box Regression 를 통해 확인하자.
결국 1 X 1 conv 연산을 한다는 것은 매 그리드 포인트를 움직이며 매 픽셀에서 앵커박스 연산을 한다는 것이다.
# rpn 연산구현, base 는 입력 네트워크
def rpn(base, num_anchors):
x = Convolution2D(512, (3,3), padding ='same', activation = 'relu', kernel_initializer = 'normal', name = 'rpn_conv1')(base_layers)
x_class = Convolution2D(num_anchors, (1, 1), activation = 'sigmoid', kernel_initializer = 'uniform', name = 'rpn_out_class')(x)
x_regr = Convolution2D(num_anchors = 4, (1, 1), activation= 'linear', kernel_initializer= 'zero', name = 'rpn_out_regress')(x)
return [x_class, x_regr, base_layers] ✅ (참고) RPN Bounding Box Regression

이번엔 Anchor Box와 센터 좌표, Predicted Ground Truth 를 사용한다.
수정 예측값 4가지 (GT의 예측좌표로써 GT의 중심좌표 x, y 와 너비, 높이를 예측한다.)
- 앵커박스의 x, y 좌표에서 예측박스 x,y 까지 거리의 차만큼을 예측해서 더한 값 (실제 찾는 것은 차이이다.)
- 앵커박스의 너비, 높이 좌표에서 예측박스 너비, 높이 차이만큼을 곱한 값 (실제 찾는 것은 역시나 차이이다.)
- 따라서 4가지 차이를 예측하는 것이다.
Target
차이 4가지를 Target 으로 한다.
- 차이는 아까 전에 구한 예측값에서 좌, 우변을 조착해 델타만큼을 남긴 값이다.
- x, y 중심좌표 차이의 경우 (GT의 좌표 - Predict 좌표)/(너비 or 높이)
- 너비, 높이 차이의 경우 (GT너비 or 높이 / Predict너비 or 높이)로 구한다.
논문표기
논문표기일 경우 역시나 x,y,w,h 의 차이를 구하는 것이 목표이나 아까 전과 밝혔듯이
예측좌표 - anchor 좌표 (x,y,w,h)와
Ground truch 좌표 - anchor 좌표 (x, y,w, h) 를 같게 하는 것이다.
✅ (참고) Positive Anchor Box, Negative Anchor Box (Anchor target layer)
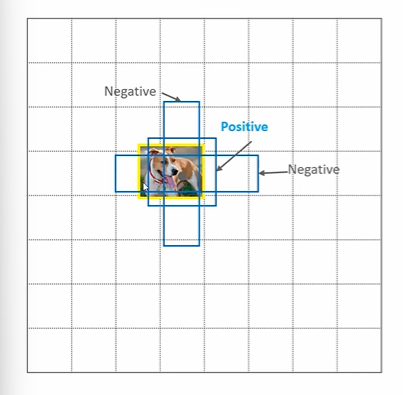
RPN이 학습하는데 사용할 수 있는 Anchor 을 확정짓도록 Anchor target layer 에서는 데이터를 positive, negative 로 나눈다. 이를 위해 앵커와 GT 의 바운딩박스와 겹치는 IOU값에 따라 positive, negative anchor box 로 또다시 분류한다.
- IOU가 가장 높은 Anchor 는 positive
- IOU가 0.7 이상이면 Positive
- IOU가 0.3 이하면 Negative -> Not object 로 분류하기 위해서 학습시킨다.
- 그 사이의 IOU 는 filtering out, 학습과정에서 제외한다.
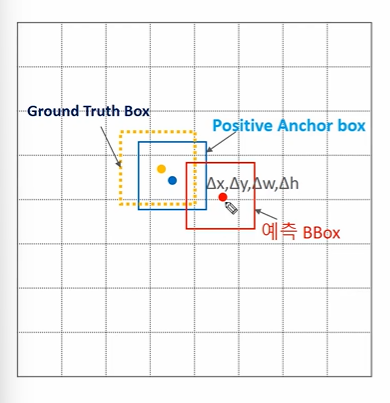
- 예측 값(예측), positive anchor, GT가 있다.
- 예측과 positive anchor box, GT와 positive anchor box 와의 차이가 동일하게 되도록 회귀를 학습시킨다.
- 왜? 이 차이를 비슷하게 하도록 학습시킨다면 목표하고자하는 예측 박스의 위치가 GT 박스의 위치와 가까워질 수 있기 때문이다.
✅ RPN Loss
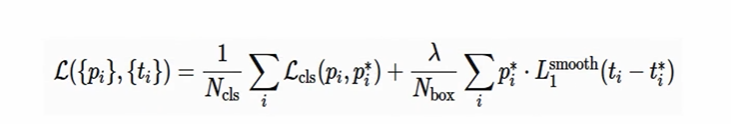
: 앵커 i가 오브젝트일 확률
: 앵커 i의 GT 여부(positive 1, negative 0)
: 앵커 i와 예측좌표 차이 (x, y, w, h)
: 앵커 i와 GT좌표 차이 (x, y, w, h)
Ncls 는 미니배치에 따른 정규화(256), Nbox 는 박스개수 정규화값(최대 2400) 을 의미하고, 람다는 밸런싱 하이퍼파라미터이다.
따라서 첫번째 term 은 앵커가 오브젝트일 '예측'과 '실제여부'의 차이를 바탕으로 Loss 를 측정(sigmoid)하는 것이다. 두번째 term 은 앵커와 예측, 앵커와 GT 사이 거리를 최소화하는 식으로 훈련하는 것이다. (L1 loss) 이때 곱해지는 p는 결국 positive anchor 에서에만 regression loss 를 측정하겠다는 의도이다.
3. Faster RCNN Training
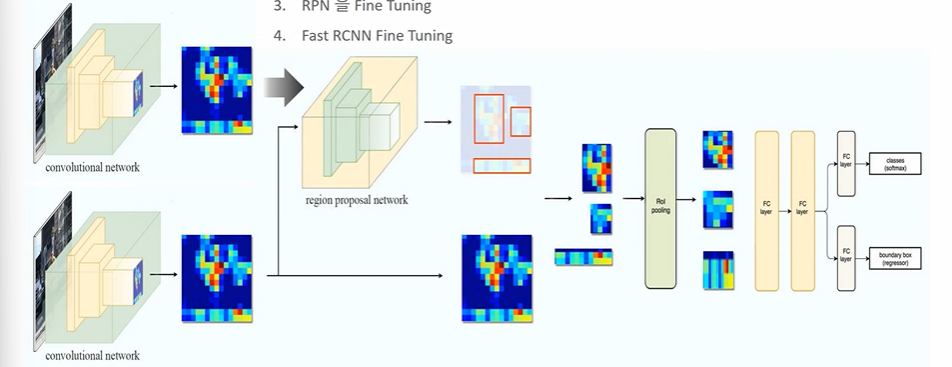
- RPN을 먼저 학습
- Fast RCNN 분류, 회귀 학습 : rpn 의 proposal 을 사용하기 위해
- RPN을 Fine Tuning (2의 loss 를 바탕으로)
- Fast RCNN Fine Tuning
먼저 학습 후 freeze 시키는 방식으로 조금은 복잡하게 학습된다.
성능비교
- Faster RCNN 은 어쨌든 SS를 사용하여 계산한 Region proposal 문제를 딥러닝으로 계산하여 진정한 end to end object Detection 모델을 제시했다는 것에 의의가 있다.
< 성능 지표 >


- mAP는 올라갔으나 수행시간 증가
- ss -> RPN 으로 바꿀 때의 시간이 증가 (5fps)
