📚 목차
SPPNet 이해
- spp net
- bag of visual words
- SPM
Fast RCNN 이해
- ROI
- ROI in Fast RCNN
- Fast RCNN 구조
- Multi-task loss
SPP(Spatial Pyramid Pooling) Net
Fast RCNN의 경우 SPP Net 을 차용하므로 선세적인 이해가 필요하다.
RCNN 의 문제점으로는
- 2000개의 region 을 설정하면서 수행시간이 오래걸린다는 점 (학습뿐 아니라 Inference 도 오래걸린다..)
- region 영역 이미지가 Crop/Warp 되어야 한다는 점 등이 있다.
➡️ RCNN 개선 방안
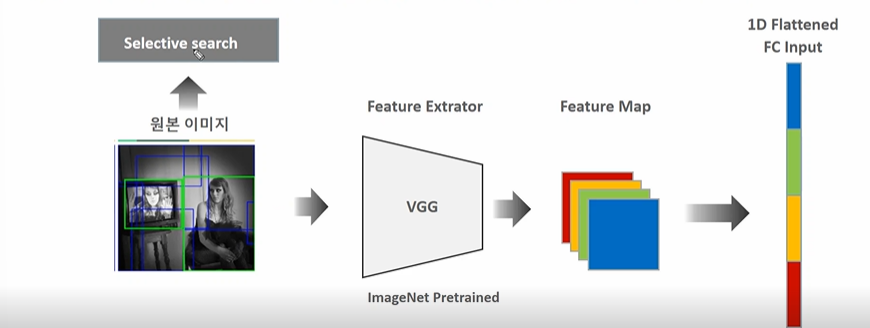
- 원본이미지를 CNN 으로 피처맵 생성
- 뒤에 원본 이미지의 SS 로 추천된 영역의 이미지만 피처맵으로 매핑하여 도출 (순서 바꿈!)
- 그러나 이 방법은 3차원의 피처맵 (13 X 13 X 512) 을 FC 레이어로 바꿀 때 이 크기의 고정이 되어야 하는데 이것이 불가능하므로 안된다.
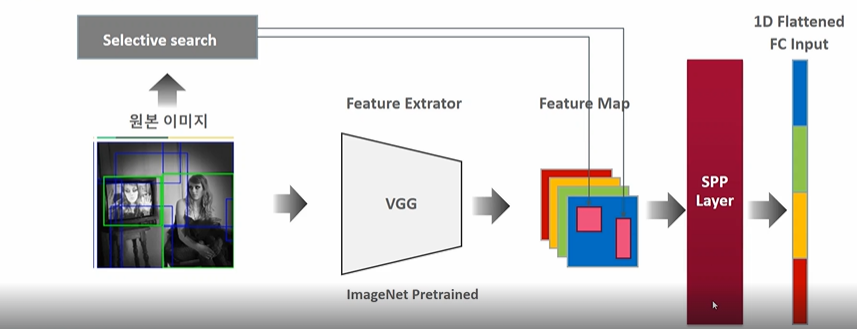
그래서 SPP레이어를 추가한다. (고정된 크기의 벡터로 미리 변환하여 FC에 제공)
SPP 는 서로 다른 크기의 이미지를 고정크기로 변환하는 기법으로 소개된 것이다.
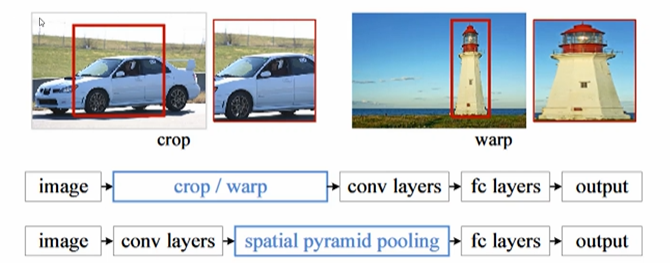
- 1: 기존 방법: 이미지를 찌그러트려야 했음
- SPP: 이미지 -> 피처맵 -> SPP -> FC layers -> 아웃풋
그렇다면 SPP, Spatial Pyramid matching 은 무엇일까?
Spatial Pyramid Matching
Bag of Visual Words
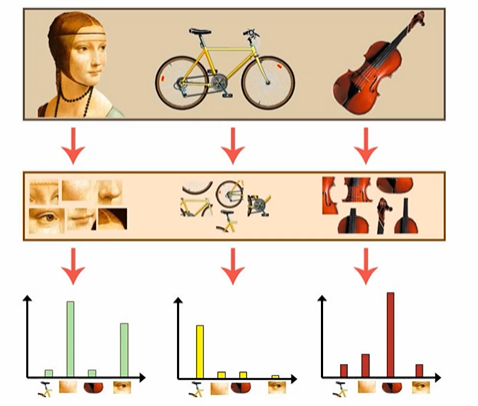
BOWs 방법처럼 사진을 쪼개서 그것들의 count histogram 을 보는 것이다.
원본 사람의 사진을 쪼개고, count 하고, 분류하는 방식이다. -> 원본이 가진 정보를 새로운 매핑 정보로 변환. 이때 매핑 정보의 기준을 히스토그램으로 하는 것이다.
그러나 이렇게 단순히 자르고, count 하는 방식은 사진 내에서의 위치를 감안하지 않기 때문에 위치를 어떻게 계산할 것인지, 여기서 등장한 것이 SPM 이다.
SPM(Sptial Pyramid Matching)
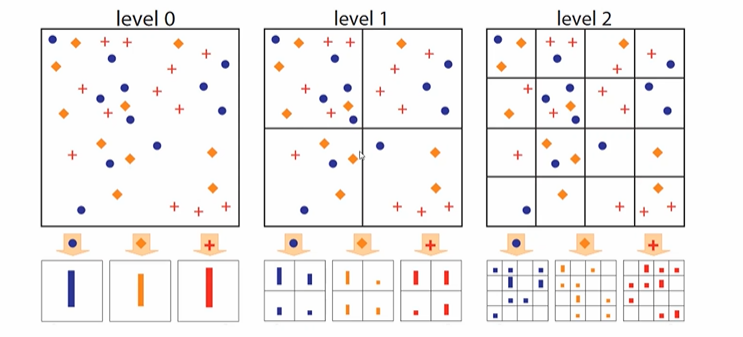
- 분면을 쪼개고
- 각각의 분면에서 count 하는 것이다.
- 위의 피처값들을 이용해서 분류 작업을 수행하는 것이다.
이렇게 하면 아래와 같이 정보를 늘리는 것이 가능해진다.
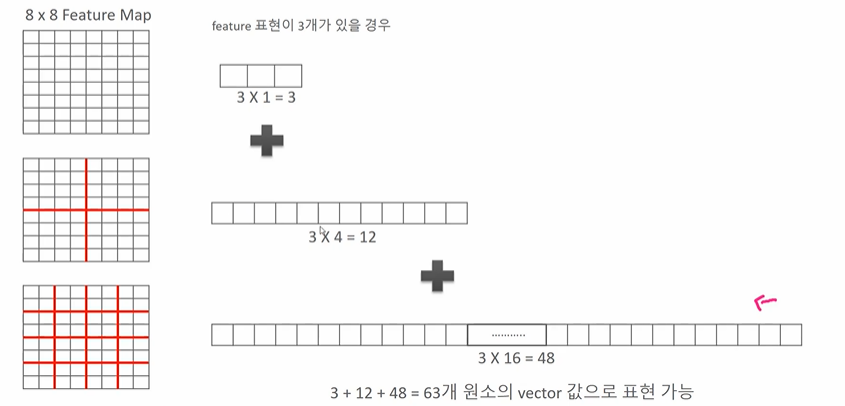
- 8 X 8 의 피처맵이 있을 때 쪼개지 않을 경우 3, 4분면으로 쪼갤 경우 12, 16분면으로 나눌 경우 48이 든다.
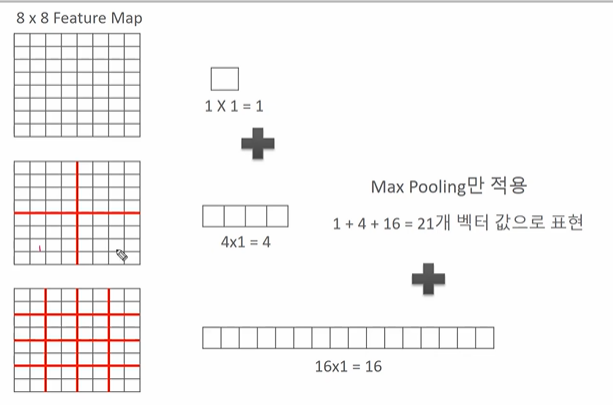
- 따라서 pooling 만 적용했을 때 21개의 벡터값으로 표현하는 것이 가능해진다. 그러나 이렇게 분면으로 나눠서 max pooling 을 적용할 경우
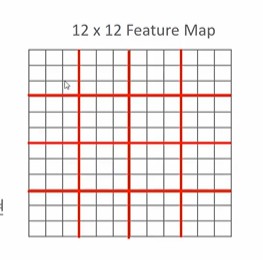
- 위와 같이 12 X 12 로 피처맵의 크기가 달라져도 분면 기준으로 짜르고, 합치므로 괜찮다. (사이즈가 달라져도 결과물 사이즈가 같다.)
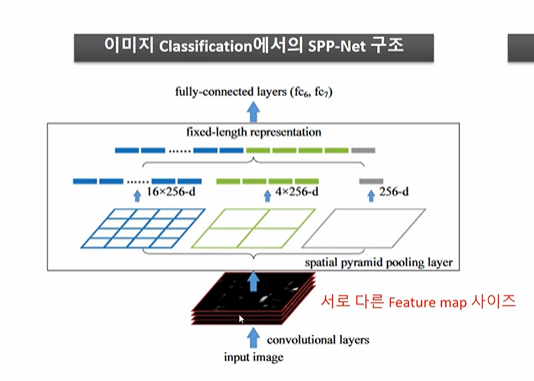
- 서로 다른 피처맵 사이즈가 있다고 해보자
- 234 X 234 를 1분면, 4분면, 16분면으로 짤라 max pooling 할 경우나
- 448 X 448 을 1, 4, 16분면으로 짤라 max pooling 할 경우나 결과적으로 fixed length representation 을 추출하는 게 가능해진다.
- 테스트 결과 손실 대비 고정 크기를 유지하면서 (Warp 없이) 계산한다는 점의 성능 향상 정도가 더 컸다는 것이 확인되었다.
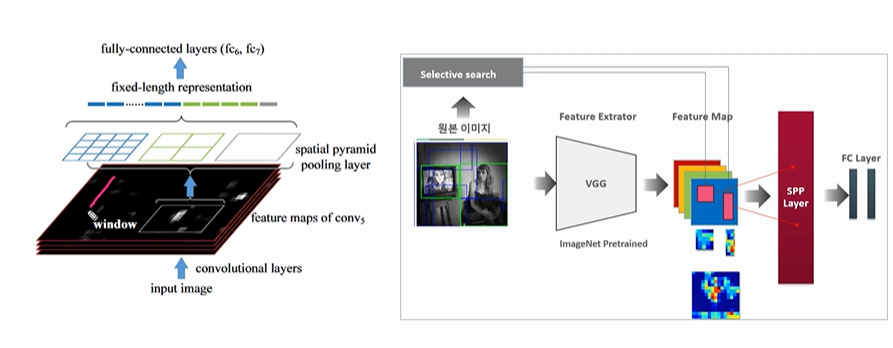
따라서 SS 로 추출한 피처맵의 크기가 어떻듯 SPP 레이어를 지나면 같은 고정크기를 도출하는 것이 가능해진다. 그 후 FC layer 계산을 하면된다!
결과적으로 원본 이미지에서 2000개의 region 을 뽑아 계산하지 않고 원본 이미지 하나에서 피처를 뽑고, 피처에서 SS를 뽑아 SPP 레이어를 통과시키고 학습시키는 것이다. 이미지는 한번만 CNN을 통과한다!
Fast RCNN
-
이미지 하나 > CNN 연산 > ROI Pooling 연산 적용하는: Fast R-CNN
-
Selective search 를 딥러닝 네그워크로 들어오게 한 RPN: Faster R-CNN
✅ Fast R-CNN 주요 특징 (from SPP Net)
1. SPP layer 을 ROI Pooling layer 로 교체
2. End to End Network Larning (SVM -> Softmax 로 변환, Multi-task loss 함수로 분류와 회귀 함께 최적화)
ROI Pooling
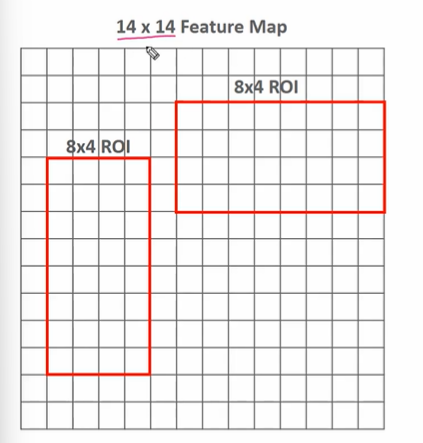
- SS로 8 X 4, 8 X 4 두개를 찾았다고 하자.
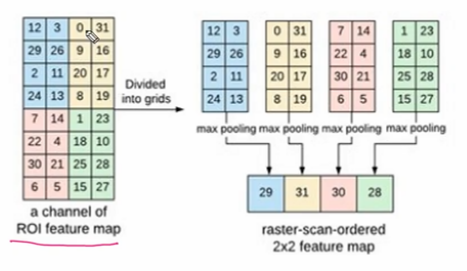
- 2 X 2 Poling 매핑을 적용한 결과이다. (4개의 값)
Fast RCNN - ROI Pooling
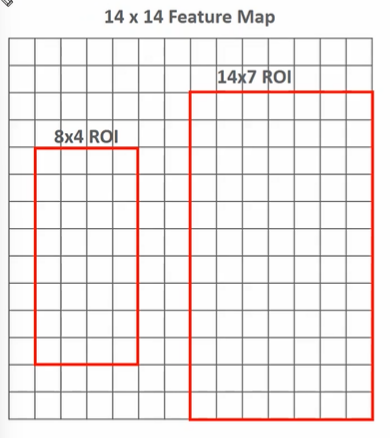
- 두개의 SS 가 있다고 할 때
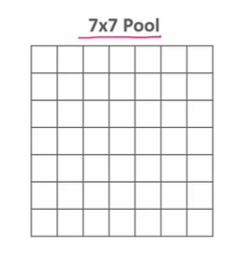
- pool 크기를 보통 7 X 7 로 설정해서 매핑한다.
- 이때 8 X 4 와 같이 애매한 어떻게 할까? 8:7, 4:7로 나눠지지 않는 수일 경우 보간법 또는 image.resize를 적용하여 매핑한다.
ROI결합된 Fast RCNN 구조
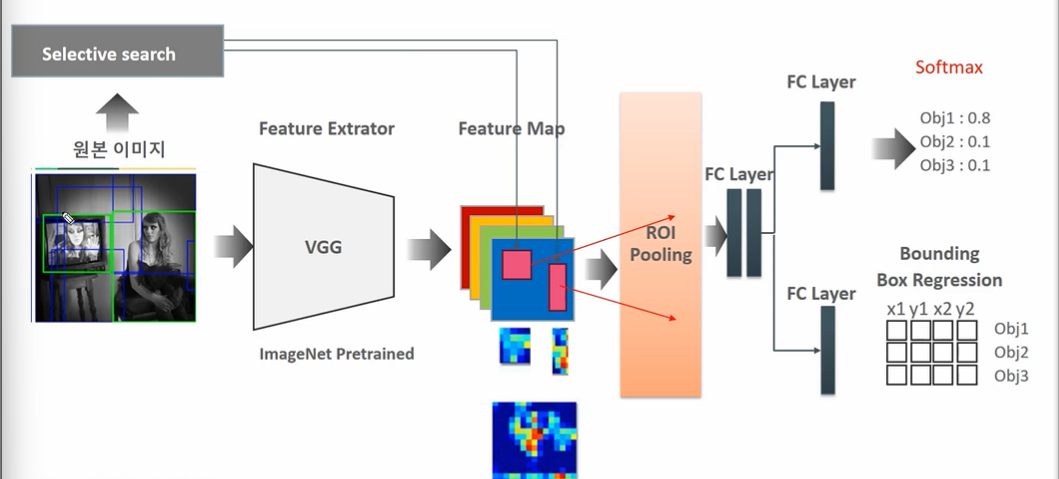
- 7 X 7 로 ROI Pooling (사이즈 고정)
- (2000, 7, 7, 256) -> 배치를 고려할 경우 (4, 2000, 7, 7, 256)
- SPP와 달리 일차원으로 하진 않고 사이즈만 고정하는 기법이다.
다시 순서를 정리해보자.
-
CNN Feature extraction
원본이미지에서 CNN 연산을 통해 피처맵을 추출한다. 논문의 숫자로는 (14, 14, 512)
동시에 2000개의 bounding box 를 Selective Search 로 생성한다. -
Region projection
추출한 2000개의 region 을 피처맵과 매핑한다. -
ROI Pooling
VGG의 max pooling layer 을 ROI로 바꿈으로써 구현된다. ROI Pooling 을 적용시키면 항상 동일한 크기의 input을 얻게되는데 이는 배치까지 고려하면 5차원이다.
- inpput (4, 2000, 14, 14, 512)
- output (4, 2000, 7, 7, 512)
- 4는 배치 이미지 수이다
- 2000은 region proposal 개수
- 7 X 7 은 ROI pooling 각 roi들의 크기이다
- 512는 피처맵의 개수이다.
- FC layer flatten
5차원을 FC Layer 로 변환시키기 위해서는 TimeDistributed Denser layer (문서참조) 를 하나 연결한다. 이를 통해 개별 ROI별로 따로 Dense를 연결할 수 있게 된다. (모든 ROI가 Denser layer 로 연결되며 Softmax 를 통한 학습 등이 가능해진다.)
결과적으로는 2000개의 bounding box마다 7 x 7 x 5012 의 피처맵을 flatten 하기 때문에 4096 크기의 벡터가 완성된다.
5-1. Image Classification
4096 크기의 feature vector 를 FC layer 에 입력한다. FC layer 에선 K개의 클래스와 1개의 배경까지 예측할 수 있도록 (K+1) 크기의 피처벡터를 출력한다. 따라서 2000개의 region 이 하나씩 FC layer 를 통과하여 K+1 크기의 피처벡터를 하나씩 가진다.
5-2. Bounding Box Prediction
class 별로 bounding box좌표를 예측해야 하므로 (K+1) X 4 크기의 피처벡터가 출력 크기이고, 2000개의 bounding box 가 한번씩 FC layer 를 통과하여 피처벡터를 1개씩 갖는다.
Multi-task loss
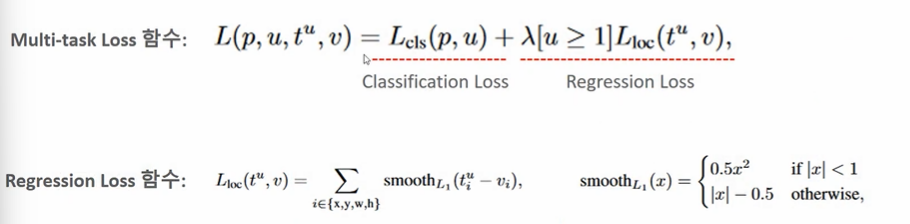
- p: (K+1) 개의 class score
- u: ground truth score
- t: 예측한 bounding box 좌표 조정하는 값
- v: 실제 bounding box 좌표값
- 람다: balancing hyperparameter
따라서 예측 class score 과 GT 의 class score 분류 오차로 Log loss로 계산하고, 회귀 손실은 Smooth L1 loss 로 게산한다. 만약 값이 1이하일 경우 오차를 선형보다 더 줄여서 계산하고, 그렇지 않으면 -0.5 해준 값을 이용한다.
- smooth l1 loss 를 사용하여 Regression 을 계산한다가 포인트
- 1보다 작을 때는 loss 를 줄여주는 방식이다.
- smooth l1 loss 살펴보기
