OpenCV 이미지처리
OpenCV 이미지 처리를 이해함과 동시에 다른 패키지와 비교해보자!
가져올 사진은 다음 깃허브에 있는 이미지이다. 파일 이름은 'beatles01.jpg'이고 이미지를 /content/data 아래에 저장했다.
✅ PIL 패키지를 이용하여 이미지를 로드하기
첫번째로 OpenCV가 아닌 PIL 패키지를 이용해서 이미지를 로드해보자.
import matplotlib.pyplot as plt
import os
%matplotlib inline
# PIL 사용하기
from PIL import Image
# PIL은 oepn()으로 image file을 읽어서 ImageFile객체로 생성. (객체 vs. 배열)
pil_image = Image.open('/content/data/beatles01.jpg')
print('image type:', type(pil_image))
plt.figure(figsize=(10, 10))
plt.imshow(pil_image)
#plt.show()
PIL 을 사용하기 위해선 from PIL import Image 명령어를 사용하면 된다. 주요한 특징으로는
.open을 사용한다는 점- 배열이 아닌 객체로 불러온다는 점
이 있다. 이 두가지가 나머지 것들과 차이를 이루니 주의해서 보자.
✅ skimage(사이킷이미지)로 이미지 로드하기
이번엔 사이킷이미지로 이미지를 가져와보자.
from skimage import io
#skimage는 imread()를 이용하여 image를 numpy 배열로 반환함.
sk_image = io.imread('/content/data/beatles01.jpg')
print('sk_image type:', type(sk_image), ' sk_image shape:', sk_image.shape)
plt.figure(figsize=(10, 10))
plt.imshow(sk_image)
#plt.show()
# 633(행) 806(열) 3 (RGB)
사이킷이미지를 사용하려면 from skimage import io 명령을 사용한다. 역시나 같은 사진이 뜨지만
io.imread를 사용한다는 점- 타입을 찍어보면 넘파이 배열, shape 을 찍어보면 행, 열, RGB(3) 이 뜬다는 것을 확인할 수 있다.
✅ OpenCV 로 이미지 로드하기
OpenCV 의 경우
- import cv2 를 해주고
- cv2.imread 를 해줘서 이미지를 읽는다. 주의할 것은 이때 OpenCV 는 BGR로 이미지를 읽어온다는 점.
- 따라서 cv2.imwrite 를 해서 다른 파일에 한번 쓰고 그 파일을 plt.imread 로 읽어오거나
- 이 과정이 번거러우므로 cv2.cvtColor(이미지, cv2.COLOR_BGR2RGB) 로 읽어온다.
import cv2
cv2_image = cv2.imread('/content/data/beatles01.jpg') # -> BGR 로 읽음
cv2.imwrite('/content/data/beatles02_cv.jpg', cv2_image) # BGR -> RGB 로 바꿔서 씀
print('cv_image type:', type(cv2_image), ' cv_image shape:', cv2_image.shape)
plt.figure(figsize=(10, 10))
img = plt.imread('/content/data/beatles02_cv.jpg')
plt.imshow(img)방법 1로 다른 파일에 쓰고(imwrite 의 경우 RGB로 바꿔서 쓴다.) 가져오거나
cv2_image = cv2.imread('/content/data/beatles01.jpg')
draw_image = cv2.cvtColor(cv2_image, cv2.COLOR_BGR2RGB) # BGR -> RGB
plt.figure(figsize=(10, 10))
plt.imshow(draw_image)
plt.show()방법 2로 파일을 읽고 cv2.cvtColor(이미지, cv2.COLOR_BGR2RGB) 를 하는 방법이 있다.
이제 두 과정을 거치지 않고 바로 읽고 plt.figure, plt.imshow 를 하게되면 다음과 같은 참사가 벌어진다..
cv2_image = cv2.imread('/content/data/beatles01.jpg')
plt.figure(figsize=(10, 10))
plt.imshow(cv2_image)
plt.show()
OpenCV 영상처리 개요
추후 Object detection 을 할 때 기본코드가 되는 부분이다.
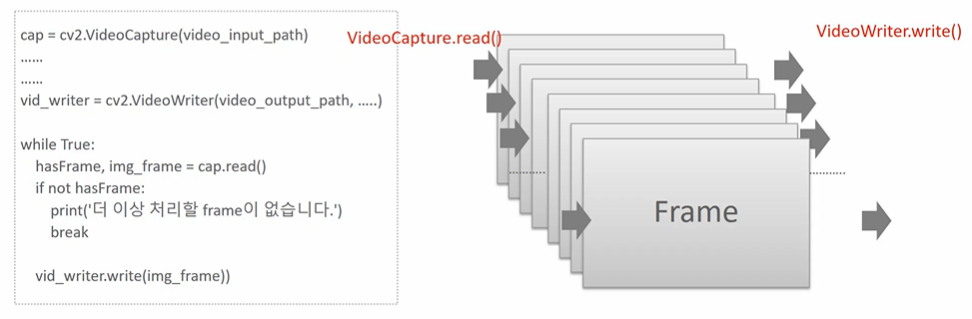
cv2.VideoCapture(영상경로)를 지정 후
.read() : 반복문안에서, hasframe(다음 프레임이 있는지, true or false 반환), img_frame(배열 반환) 을 한다.
cv2.VideoWriter(아웃풋 경로, ...)지정 후
.write(img_frame) : 이미지 프레임을 쓸 수 있다.
조금 더 구체적으로 알아보자!
✅ VideoCapture
1. 생성인자로, 입력비디오 파일 위치를 받아 생성한다.
cap = cv2.VideoCapture(경로) - 생성된 cap 객체는 비디오 파일의 다양한속성을 가져올 수 있다.
- 영상 너비 : cap.get(cv2.CAP_PROP_FRAME_WIDTH)
- 영상 높이 : cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
- 영상 FPS : cap.get(cv2.CAP_PROP_FPS)
- 객체 cap.read 는 마지막 프레임까지 차례로 프레임을 읽는다.
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더이상 처리할 프레임 없음')
break✅ VideoWriter
1. VideoWriter 객체는 동영상파일 위치, 코덱 유형, fps 수치, frame 크기를 생성자로 입력받아 write 를 수행한다.
- 특정 포맷으로 인코딩할 수 있다.
cap = cv2.VideoCapture(video_input_path)
codec= cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDHT),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) # -> 프레임크기
vid_fps = cap.get(cv2.CAP_PROP_FPS) # -> fps
vid_writer = cv2.VideoWriter(video_output_paht, codec, vid_fps, vid_size) # 인자로 경로, 코덱, fps, 프레임크기를 쓴다. 인자로 경로, 코덱, fps, 프레임크기를 쓴다는 점이 까다롭긴하지만 중요한 부분.
영상처리 실습
import cv2
video_input_path = '/content/data/Night_Day_Chase.mp4'
# linux에서 video output의 확장자는 반드시 avi 로 설정 필요.
video_output_path = '/content/data/Night_Day_Chase_out.avi'
cap = cv2.VideoCapture(video_input_path)
# Codec은 *'XVID'로 설정.
codec = cv2.VideoWriter_fourcc(*'XVID')
# 프레임 사이즈, cap 의 가로와 세로를 그대로 사용
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) #(200, 400)
# fps, cap으로 fps 를 그대로 사용
vid_fps = cap.get(cv2.CAP_PROP_FPS )
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, 'FPS:', round(vid_fps), 'Frame 크기:', vid_size)비디오캡쳐로 만든 cap 객체로, 프레임 사이즈(가로, 세로)와 fps 를 가져올 수 있다. 이제 이미지 프레임
import time
green_color=(0, 255, 0)
red_color=(0, 0, 255)
start = time.time()
index=0
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
index += 1
print('frame :', index, '처리 완료')
cv2.rectangle(img_frame, (300, 100, 800, 400), color=green_color, thickness=2)
caption = "frame:{}".format(index)
cv2.putText(img_frame, caption, (300, 95), cv2.FONT_HERSHEY_SIMPLEX, 0.7, red_color, 1)
vid_writer.write(img_frame)
print('write 완료 시간:', round(time.time()-start,4))
vid_writer.release()
cap.release() -
time 을 불러와서 time.time() 을 하면 완료까지의 시간을 계산할 수 있다.
-
반복문을 돌며. cap.read() 를 수행해준다. 아까도 봤듯이 cap.read() 가 반환하는 것은 [다음 프레임이 있는지, 그 프레임의 배열] 두 가지이다.
-
지금은 cv2.reactangle, cv2.putText 로 이미지 프레임 안에 박스를 고정해서 쳐줬지만 나중엔 프레임마다 Objectdetection 한 결과를 넣을 수 있을 것이다!
-
vid_writer 는 아까 VideoWriter 로 만든 객체였다. 이미 인자로 아웃풋 경로와 코덱, 사이즈, fps 등이 저장되어 있으니 프레임마다 써주기만 하면 될 것이다. 쓰는 것은
vid_writer.write(프레임)이다. -
모든 작업이 끝나면 Videocapture 과 VideoWriter 을 종료해준다.
.release를 사용하면 된다.
