Object Detection 구조
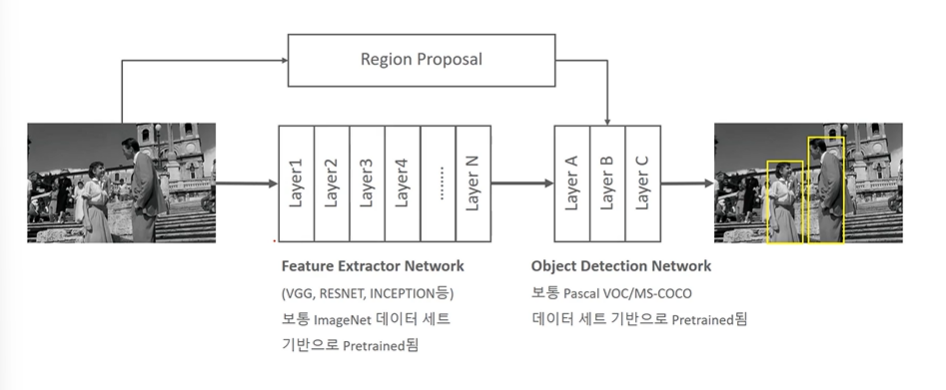
-
Feature Extractor Network (이미지 분류에서 활용하는 CNN 네트웍 모델을 따라간다, backbone 이라고도 불린다. 맵의 크기는 줄어들지만 개수는 늘어나는 구조. 원본이미지에서 주요 feature 들을 뽑아내는 구조를 말함!)
-
Object Detection Network (별도의 네트웍. 바운딩박스는 어떻게 계산할 것이며, Classification 은 어떻게 할 것이냐?를 계산하는 범위. 계산된 Region Proposal을 받아 마무리 계산.)
Image Resolution, FPS, Detection 상관관계
- 높은 Image Resolution 일 경우 Detection 성능도 높아지나, FPS(1초에 Detect 할 수 있는 이미지 개수) 는 떨어진다. -> 배열 크기가 커지므로 속도가 떨어진다.
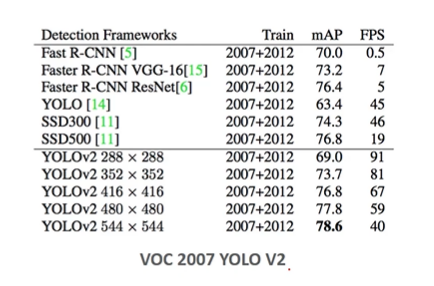
-
288에서 544로 오르면 mAP는 늘었지만 (성능은 굿) FPS 는 떨어진다 (시간이 늘어난다)는 것을 알 수 있다.
-
결론적으로 두마리 토끼 사이에서 무엇을 잡을지, 둘 다 1등할 순 없지만 크게 뒤떨어지지 않게 잘하는 모델이 좋은 모델이라 할 수 있다. (이마저도 도메인에 따라 중요한 모델이 다를 것이다.)
R-CNN(Region Proposal 기반 Detection 모델)
Object Detection 에 처음으로 딥러닝을 적용한 모델이다.
Object Localization 은 기존 분류 모델(이미지 > Feature Extractor > Feature Map > FC Layer > Softmax score) 에 좌표값을 찾는 Regression 문제가 포함된 것이다. (Feature Map > Bounding Box Regression)
Detection 의 경우 여기에 Object 가 있을만한 위치를 먼저 예측하는 Region Proposal 을 더한다고 했다. (색, 무늬, 형태의 차이로 계층적 결합 vs. Sliding Window)

이렇게 Region Proposal 은 어디에 더해질까? 2000개의 Region proposal 을 뽑는다고 했을 때, 이들의 사이즈를 맞추고 Feature Extractor 네트웍에 집어넣는다.
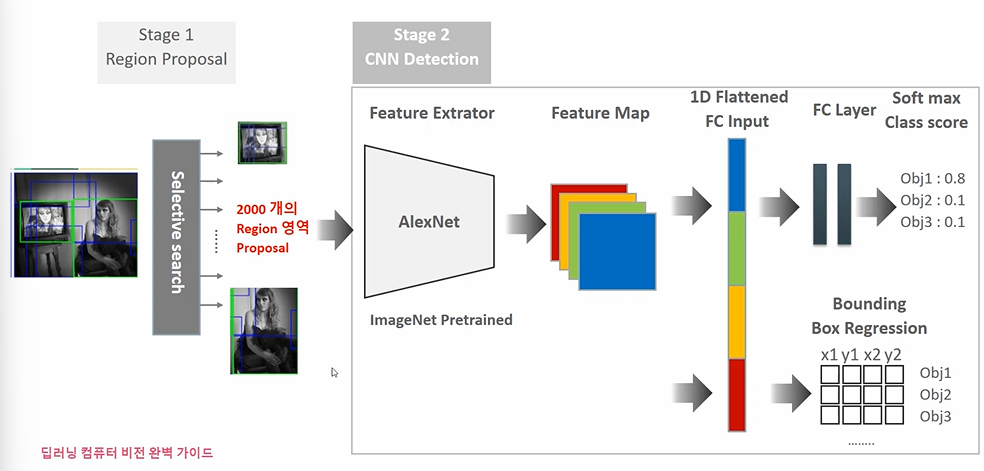
- 2000개의 Proposal 된 이미지들은 사이즈가 동일해야 한다. (모델에 들어가기 위해서) -> Region 들이 같은 크기로 맞춰지므로 찌그러져 보일 수 있다.
- FC Layer 다음에 소프트맥스가 아닌 SVM Classifier 을 붙인다.
다음은 논문의 그림이다.
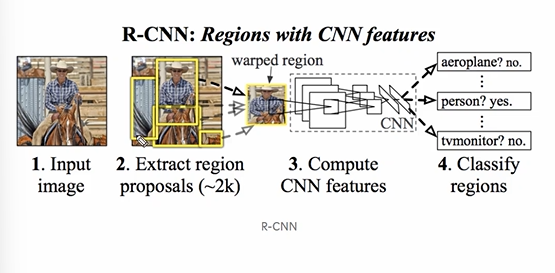
- 인풋이미지
- Region proposal
- CNN 계산 (통일된 사이즈로, 따라서 어떤 proposals 들은 찌그러진다.)
- Classify + Regression
따라서 각 proposal (2000개) 마다 CNN 계산을 적용시킨 후 SVM, regression 적용시킨다고 생각하면 된다. Inference 자체에서도 이 과정을 거치기 때문에 연산량이 많고 시간이 오래걸린다.
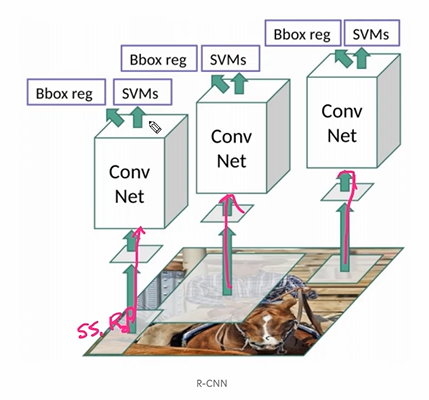
R-CNN Training
✅ Classification
분류는 어떻게 훈련될까?

- 원본 이미지에 Selective Search 적용 (GT vs. SS predicted)
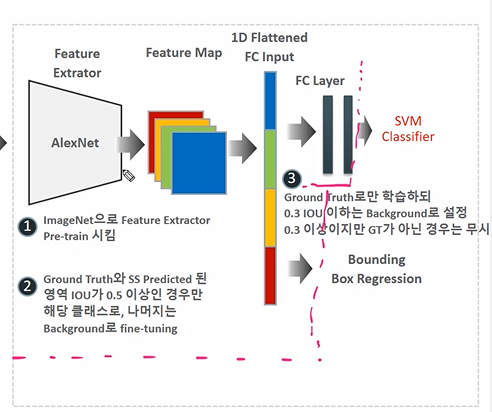
- 이미지넷 데이터셋으로 Feature Extractor 을 학습시킨다. (20개)
- Fine-tuning: GT와 SS의 겹치는 IOU가 0.5 이상이라면 해당 클래스에 속하는 것으로, 나머지는 Background 로 파인튜닝
- 만들어진 FC Layer 을 GT 로 학습. 0.3 IOU 이하는 배경, 0.3 이상이지만 GT가 아닌 경우는 무시하여 SVM 학습.
✅ Regression
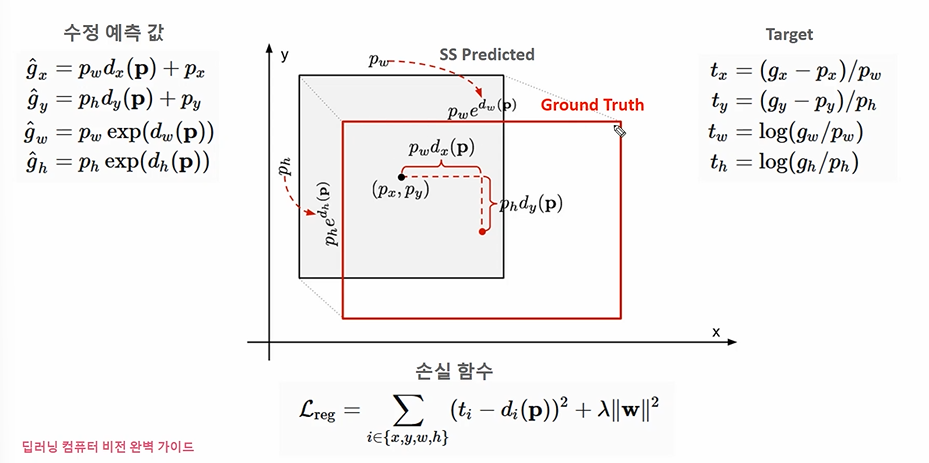
가운데 좌표와 너비로 구성된다.
모델의 목표는 SS proposal 영역의 가운데, GT의 가운데가 최소화되는 것이다. 너비의 차이도 최소화되어야 한다.
예측값을 만들 땐
- g'x = ss의 x좌표 + 가중치 X dx(p) (x좌표 예측)
- g'y = ss의 y좌표 + 가중치 X dy(p) (y좌표 예측)
- g'w (너비 예측)
- g'h (높이 예측)
를 이용하여 예측값을 만든다. 따라서 구해야 하는 변수는 dx(p), dy(p) 이 변해가며 최적의 값을 도출하는 것이다.
Target
- gt의 좌표인 gx 에서 예측좌표인 px 를 뺀 값을 pw 로 나눈 값 tx
- gy에서 py를 뺀 값을 ph 로 나눈 값 ty
- gt의 너비인 gw를 pw 로 나눈 tw
- gt의 높이인 gh를 ph 로 나눈 th
따라서 손실함수에선 위 x, y, w, h 를 모두 손실로 감안하여 계산하고, 앞의 Target 에서 뒤의 di(p) 를 뺀 것을 Objective 로 사용한다. 이때 d(p)는 위의 예측값을 좌변으로 조작하고 나눈 그 값이다! d(p) 는 결국 가중치의 값인데 이 loss 계산시 계산값이 아니라 가중치값만 이용하고 싶었던 거다.)
R-CNN 장단점
높은 Detection 정확도, but
너무 느린 Detection 시간과 복잡한 아키텍쳐, 학습 프로세스
- 하나의 이미지에 2000개의 proposal 을 도출한다는 점
- 각기 따로 노는 구성 요소들 (SS, CNN, SVM ..)
이라는 문제들이 있었다.
그러나 RCNN은 딥러닝 기반에서 Object Detection 성능을 입증한 논문이며, Region Proposal 아이디어를 내었다는 점에서 의미가 깊다.
