
Relational Model
- 데이터와 데이터 관계 표현, Table 을 사용해서.
- 레코드의 집합으로 구성. 각 레코드는 필드의 합 (= attribute의 합)
- DB > Table > attribute
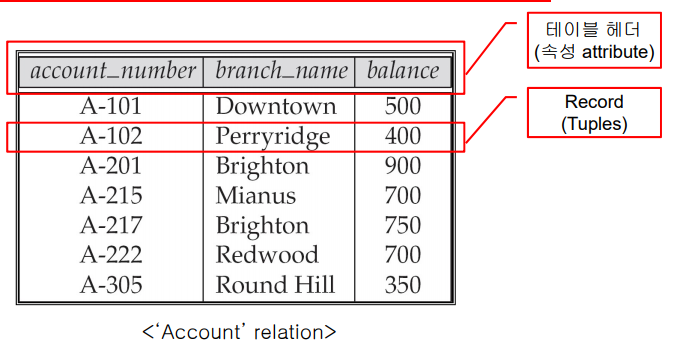
- 한 행을 레코드, 튜플이라고 함.
- 각 열을 속성이라고 함.
- 7의 튜플로 구성된 테이블.
Basic Structure of Relational Model
- Domain: 각 속성이 가질 수 있는 값의 집합. (속성은 이름, 도메인은 그 값들의 집합이니 같지만 조금 다르다.)
- 예컨대 학년 속성의 도메인은 1,2,3,4 이다.
- n개의 속성을 갖는 테이블은 다음 집합의 부분집합.
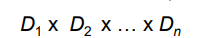
- 집합과 집합 사이 X 곱하기 기호는 Cartesian product 이다.
D1 = {A, B, C}
D2 = {1,2}
Cartesian product = D1 * D2 = {A1, A2, B1, B2, C1, C2}
원소개수 = 3 X 2 = 6 - relation 은 그 부분집합.

- 4 X 3 X 3 = 36 개의 원소 중에 relation이 존재. relation은 부분집합이므로 원소 4개를 갖는 1개 relation.
Attribute Types
- Relation 은 이름과 타입이 있다.
- Attribute 에 저장되는 값들은 원자값이어야 함. (도메인은 원자값이어야 함.)
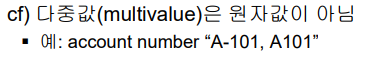
- Atomic domain 원자적 도메인
- attribute 도메인은 원자적이어야 함. - null : 유일하게 모든 도메인에 속할 수 있는 값임.
Relation Schema
- A 가 각 속성일 때, R = (A1, A2 ... An) 은 relation schema 이다.
- r(R) 일 때 r 은 relation 이름, R은 스키마의 이름.
- relation 의 tuple 들을 인스턴스라 한다.
- 튜플(행) 간 순서는 의미 없음.
Database
- 여러 relatoin 이 모여 구성됨.(여러 테이블) relation 의 집합이 DB.
- 각 relation 은 특정 정보를 저장.
- 한 테이블(=relation)에 여러 attribute 가 있을 때 업데이트의 문제, 연쇄적 삭제 문제 발생. null value 가 많이 생김.
- 테이블의 속성을 구성하는 과정이 디자인하는 단계에서 처리가 되므로 이때 Normalization 을 사용한다.

➡️ 공통된 속성을 찾는 게 방법이 된다! (공통된 속성이 있다면 무조건 관계가 있다, customer, depositor Relation)
➡️ 참조관계, refrential intregrity 를 설정하는 게 확실하다.
➡️ 참조 당하는 속성을 main attribute라 하고(Cusomer relation의 customer_name 이 main이다.) 화살표는 거꾸로 긋는다.
Keys
-
튜플을 구분할 수 있는 한 개 또는 여러 개의 속성. 속성의 데이터에 중복된 값이 있다면 key가 아니다.

-
customer_name 은 중복이 없고(키 가능!), street 는 중복이 있고, city 도 중복이 있다(키 불가능!).
-
종류: 슈퍼키, 후보키, 기본키
-
Super key
- 유일성을 갖는 속성의 집합. (이번엔 속성의 조합 간에 중복이 없기만 하면 키가 된다, 일반적인 키 개념)- 슈퍼키를 찾아야 한다면 단일 속성을 먼저, 2개 속성 조합, 3개 속성 조합 해보고 중복만 없으면 슈퍼키가 될 수 있다고 해야함.
- 앞의 Customer 테이블에서 name, name-stree, name-city, name-street-city 4개가 있다. - Deposiotr 테이블에서 account, customer-account 2개가 있다.
- 슈퍼키를 찾아야 한다면 단일 속성을 먼저, 2개 속성 조합, 3개 속성 조합 해보고 중복만 없으면 슈퍼키가 될 수 있다고 해야함.
-
Candidate key
- 유일성 + 최소성.- 슈퍼키 중 속성의 수가 가장 적어야 한다. Customer 에서는 name, Depositor 에서는 account.
- 개수로 정하므로 딱 한 개가 아니라 여러 개일 수 있다.
-
Primary key
- 후보키가 여러 개일 때 DBA 가 선택한 키.- null 값 존재하면 안됨.
- 단일 속성이 아니다.
- null 값 존재하면 안됨.

Mathematics, Algorithm, and IDEA for AI research🦖