Keys
Query Lg.
Procedural dml
- relational algebra
Non-procedural dml
- sql
Relational Algebra
- 프로시저 언어
- 인풋, 아웃풋 모두 릴레이션 = 테이블

Select Operation
- 컨디션에 맞는(predicate; 조건문) 튜플(수평)을 선택
- 수평적인 파티셔닝.
- : r 테이블의 조건 p를 만족시키는 튜플 반환.
- p는 조건문으로 비교연산을 쓰거나 로지컬 오퍼레이터를 쓴다
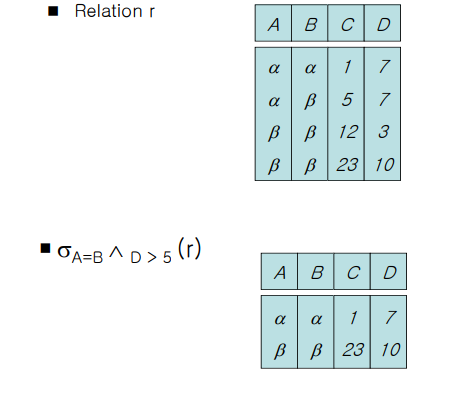
가운데에 and 기호가 있다. A=B 가 참이고 D>5 인 튜플을 찾는 것이다.
선택되는 튜플은 1번, 4번 튜플이 될 것이다!
정의를 다시해보면 다음과 같다.
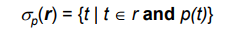
r에 속한 원소 튜플 t에 대해 조건 p를 만족하는 튜플을 선택하는 것이다.

- account 에서 branch_name = 'HUFS' 인 튜플들
- account 에서 balance > 1200 인 튜플들
- account 에서 HUFS 이면서 1200이상인 튜플들
Project Operation
- 수직 파티셔닝 (수직으로 자르자, 어트리뷰트 단위로 뽑기)
- 수식
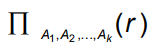
r 에서 뽑아내려고 하는 어트리뷰트의 리스트를 쓰고 뽑는다.
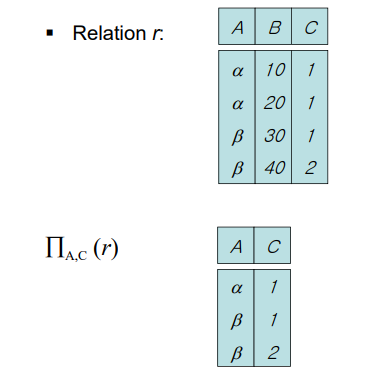
A,C만 뽑으면 된다. 단 뽑은 결과가 중복 튜플이라면 버린다. 위의 연산에서도 (알파, 1)이 중복되어 뽑히므로 하나만 선택했다. 중복된 튜플이 나오는 건 project 만이므로 잘 기억해두자.
Composition of Operations
-
두 연산을 모두 포함할 수 있다.
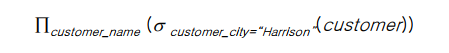

-
이를 Composition of Operations라 한다.
-
다음을 간추리면 해리슨 시티에 거주하는 고객의 이름만 찾아라! 가 된다.
Union Operation
합집합을 뜻한다!
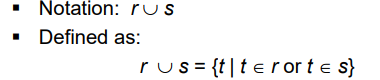
r에 속해있는 튜플이거나 s에 속해있는 튜플이면 모두 선택한다.
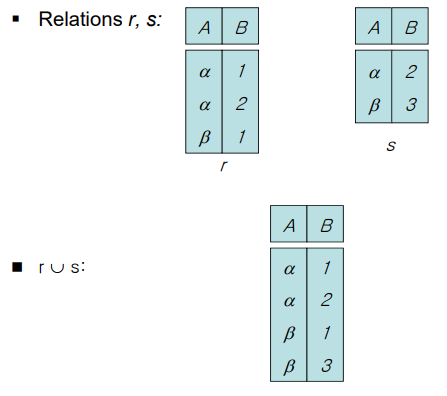
역시나 중복 튜플은 허용하지 않는다. 또한 합하려면
- 어트리뷰트의 개수와 이름이 같아야 한다(같은 열만 있어야 한다.)는 조건이 필요하다.
- 또한 어트리뷰트에 대응되는 도메인이 같아야 한다라는 조건도 필요하다. (= 해당 어트리뷰트가 가질 수 있는 값의 집합)
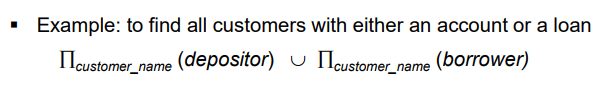
depositor 에 어트리뷰트와 borrower 의 어트리뷰트 모두 달라(도메인도 당연히 달랐다) 무작정 합할 수 없다. 그러나 customer_name 은 공통되므로 project 연산을 각각 적용시키면 합할 수는 있다. 위 식은 먼저 project 한 다음 합했으므로 연산 가능!
Set Difference Operation
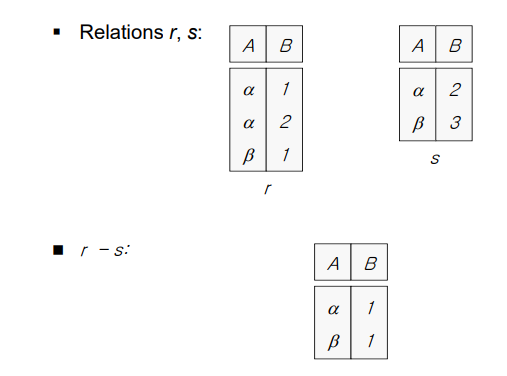
- r-s : r에는 포함, s에는 없는 튜플 찾기
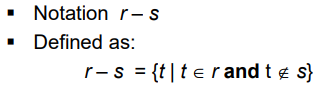
조건
두 테이블 간 어트리뷰트(이름, 개수)와 도메인이 같아야 한다.
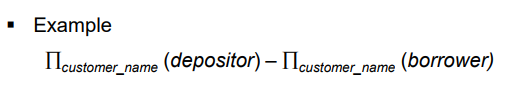
예금 고객에서 대출 고객을 뺀, 예금만 가지고 있는 고객을 뽑는 연산.
Cartesian-Product Operation
- 집합끼리의 연산
- 원소들끼리 묶는 연산 = 튜플끼리 묶는다
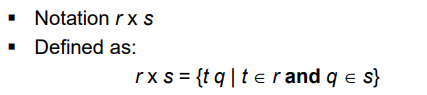
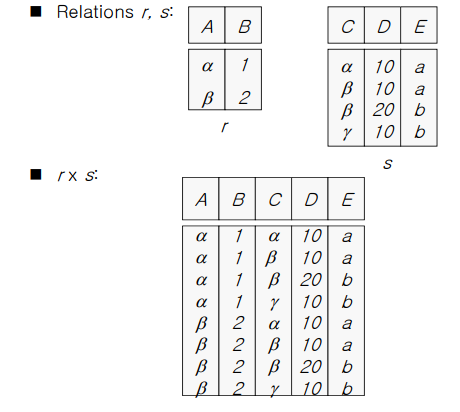
다음과 같이 곱해주듯이 (2 X 4) 연산해주는 것이 Catesian-Product 이다.
- 튜플의 수는 A튜플 수 X B튜플
- 어트리뷰트의 수는 A어트리뷰트 수 + B어트리뷰트 수이다.
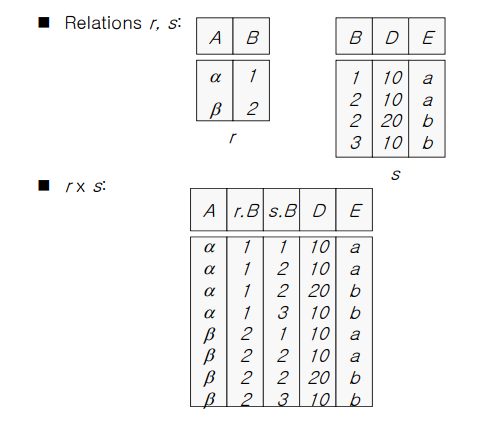
🤔 공통된 이름의 어트리뷰트가 포함된 경우에는 어떻게 할까?
-
한 테이블에 같은 이름의 어트리뷰트가 있으면 안된다 > r.B/s.B으로 구분
-
공식에 따라 A + B개 어트리뷰트 / A * B개 튜플 수 유지
-
r과 s의 각 스키마 = 어트리뷰트의 집합 = r의 어트리뷰트 집합 , s의 어트리뷰트의 집합은 서로 교집합이 없다고 가정.
-
교집합이 있다면 리네이밍 필요!
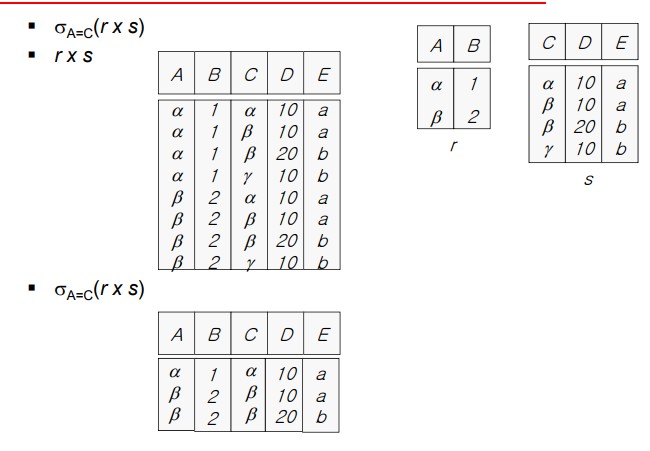
Rename Operation
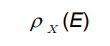
- 테이블 이름 바꿀 때: E 기존 이름, 새로운 이름 x
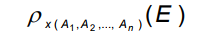
- 어트리뷰트 이름 바꿀 때: 새로운 이름 A1 - An

- rename > cartesian > select > project
account 테이블의 이름을 d로 바꾼다.
- rename > cartesian > select > project
d 테이블에 account 을 cartesian product 해준다. (자기 자신을 곱하기 위해 이름을 바꿔줬다.) > account.account_number, account.balance, d.account_number, d.balance 가 된다. / 튜플은 7 X 7 = 49개가 된다.
select로 account.balance < d.balance 인 튜플을 골라준다. 예컨대 account가 500일 경우 700, 900, 750, 700이 살아남는다. 또다시 account 가 700일 경우 900, 750이 살아남는다. 900의 경우는 살아남을 수 없다.
project 로 account.balance 만 뽑으면 정리하며 중복 제거가 가능하다. 따라서 900만 뺀 결과가 남는다. 만약 900만 남기고 싶다면 원래 테이블의 balance 집합에서 위 전체 연산을 빼준다.
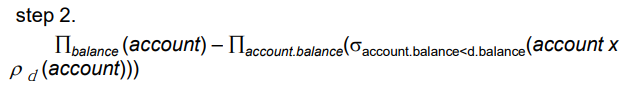
- account 테이블의 balance 열에서 위의 연산(900 제외 모두) 를 빼어 900 도출
350만 빼고 싶다면 비교 연산을 뒤집자!
Banking Example
스키마(=어트리뷰트 집합) 다이어그램
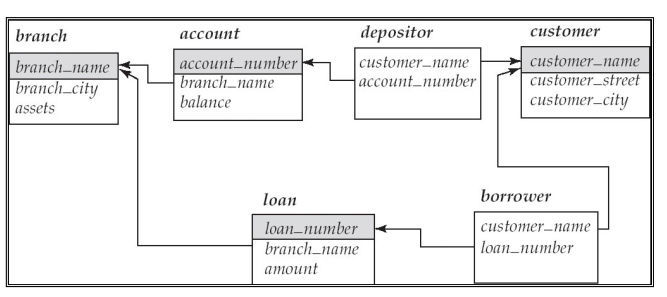
- 박스 : 어트리뷰트
- 위 : 테이블 이름
- 회색 : primary key
- 화살표의 의미 : 참조 무결성(refrential integrity) 이다. 공통 어트리뷰트끼리 설정할 수 있는 것으로,
- 테이블을 만들면서 설정한다
- loan 의 bracn_name 은 branch의 branch_name 에 있는 이름만 가져올 수 있다.
- 참조 당하는 branch 의 branch_name, 참조하는 loan의 branch_name.
Perryridge 지점의 대출 계좌를 가지고 있는 모든 고객의 이름을 찾으시오
-
branch_name, loan_nubmer, customer_name 이 필요하다.
-
loan 테이블에서 L-15,16 을 찾고 borrower 에서 customer_name 과 연결시킨다.
-
borrower(customer_name, loan_number)
-
loan(loan_number, branch_name, amount)
borrower X loan (Cartesian 연산, 총 5개 어트리뷰트)
Perryridge 를 뽑으면 (select 연산) 16개가 나온다. > 사실과 달라지는 문제
borrower.loan_number = loan.loan_number 을 확인하면 사실과 같은 튜플이 추출된다. (select 연산)
이름만 추출, customer_name (project 연산)

의 끝에 project customer_name 을 추가해준다!
++
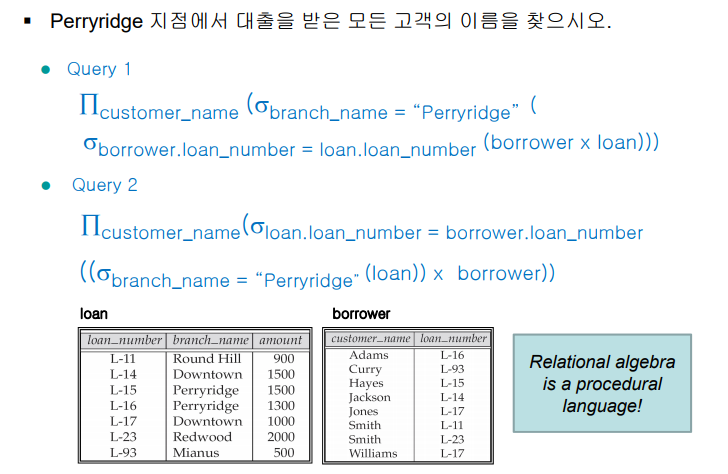
56 > 16개로 cartesian 의 결과가 줄어들었다. 당연히 2번 쿼리가 더 좋은 쿼리다. (비교 횟수와 메모리 측면에서) 이를 최적화Optimization이라고 한다.
