QUIZ
- North steet 에 거주하는 모든 고객의 이름
select customer_name
from customer
where customer_street = 'North'- Perryridge 지점에서 발행된 예금 계좌를 가지고 있는 모든 고객의 이름
select distinct customer_name
from depositor, account
where account.account_number = depositor.account_number and branch_name = 'Perryridge'한 사람이 많은 예금 계좌를 가지고 있다면 중복되므로 distinct 키워드를 썼다. 주의하자!
The Rename Operation
select old name as new-name
from old name as new-name
as 구문을 select, from 에 써서 각각 어트리뷰트 이름이나 테이블 이름을 바꿔 출력한다. (출력만 바꿔서 하는 것.)

select customer_name, borrower.loan_nubmer as loan_id, amount
from borrower, loan
where borrower.loan_number = loan.loan_number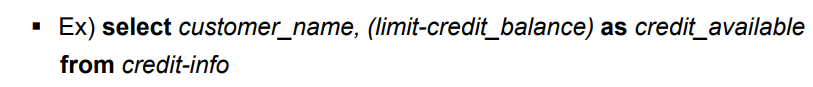
또한 다음과 같은 예에서 limit-credit_balance 같이 이름이 별로 인 것을 credit_available 로 바꿔 출력한다.
Tuple Variables
튜플 변수: 테이블 이름 잠시 재명명하기 위해 사용하는 변수, (이름이랑 다르게 튜플이랑은 상관없음.), as 사용, from절에서 정의.

해당 실행문 범위에서 아래처럼 borrower 를 잠깐 T, loan 을 잠깐 S로 부르겠다고 지정하는 것이다. (쓸 때나 읽을때나 from 먼저 읽어야겠지?)
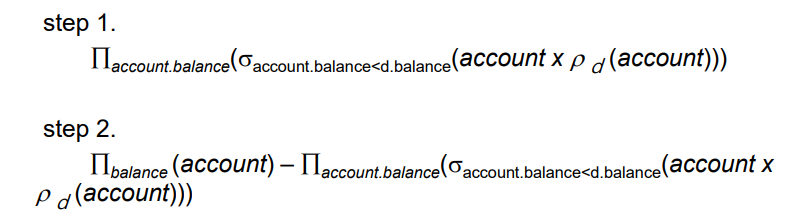
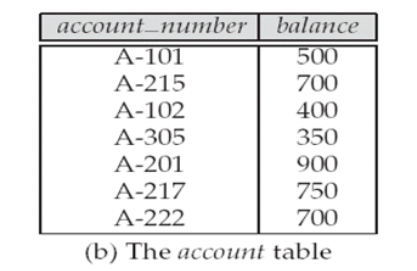
Step1의 결과는 900을 제외한 값들이 나오고, 2는 900만 나온다!
결과적으로 튜플 변수도 동일한 테이블에 대해 튜블을 비교할 때 유용하다.
예를 보자.
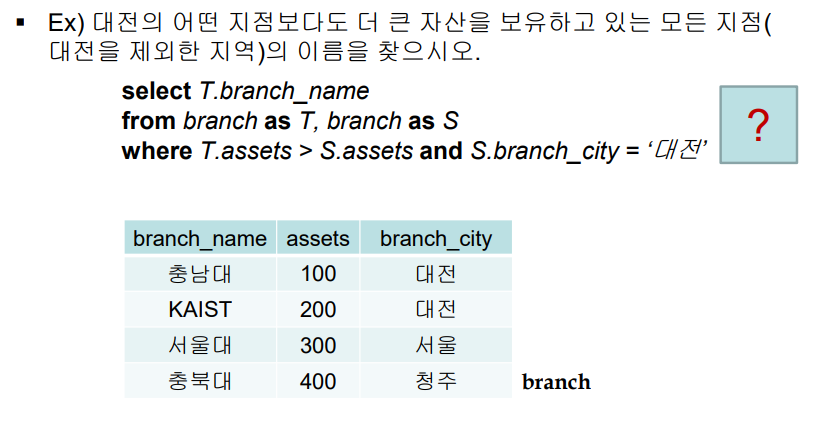
서울대, 충북대가 출력되어야 한다.
어떤 지점보다도 > 충남대 100보다 크면 된다
모든 지점보다도 > 카이스트 200보다 커야한다
이제 쿼리를 보자.
같은 테이블을 T,S로 정의해 곱한다. (어트리뷰트는 6, 튜플은 16개가 된다.)
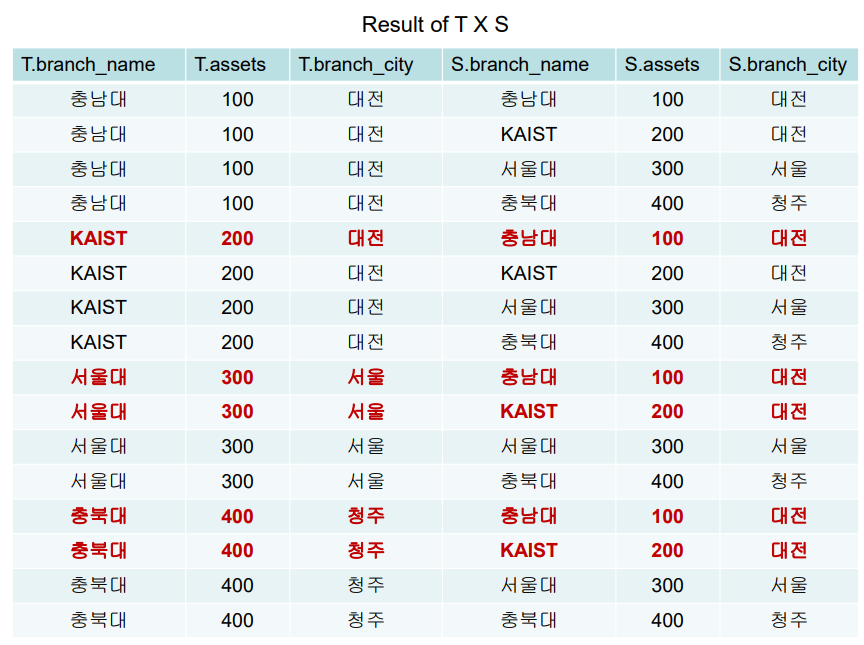
이제 where 로 T.assets 과 S.assets(기준) 을 비교. 찾는다.
마지막으로 select로 T 의 이름을 출력. 그런데 이렇게 하면 KAIST 대전도 포함된다. 대전은 빼야하므로 where 에 and T.branch_cit <>'대전' 을 추가한다.

이처럼 같은 테이블을 곱할 때 튜플 변수를 사용한다.
String Operations
like 연산자: 문자열 패턴을 지정해서 찾을 때 사용
% : 여러 문자 >> Perry%라면 Perry 로 시작하는 모든 문자열.
_ : 딱 한 문자 >> ___ 이라면 세개의 문자로 이루어진 모든 문자열.
%와 _ 앞에 like 를 써주면 된다.

HUFS 를 포함하는 다섯글자 branchname?
: branch_name like 'HUFS' or '_HUFS' 이거나
'_' and '%HUFS%' 이렇게 해도 된다.
Ordering the Display of Tuples
orde by 절을 사용하여 실행 결과를 정렬하여 출력하는 것이다. (알파벳 순서 등)
- 디폴트는 오름차순이며, 내림차순 정렬하고 싶다면 desc, 오름차순 정렬하고 싶다면 asc 를 붙인다.(안붙여도 됨)

위의 연산은 amount 기준으로 내림차순 정렬하는데, 값이 같을 때는 loan_number 기준으로 오름차순 하라는 거다.
Set Operation
튜플 단위 연산이며, union(합집합), intersect(교집합), except(차집합)가 있다.

'대출이나 예금': 둘 중 하나라도 가지면 출력하라는 것으로 union 을 사용했다. (튜플 단위에서 합집합)

'대출과 예금': 둘 모두 가져야 출력하라는 뜻으로 intersect 를 사용했다. (튜플 단위에서 교집합)

'대출 계좌 없이 예금': 예금에서 대출 계좌 고객을 빼야한다. except 를 사용한다.
SQL 기본은 중복을 허용하며, 중복을 제거하고 싶으면 distinct 를 써줘야 한다. 그러나 SQL 내에서도 집합 = Set 이므로 중복 튜플을 제거한다. 내부적으로는 중복된 튜플을 제거한다음에 연산을 적용하는 원리이다!(all 이 붙으면 제거해두지 않는다.)
중복을 허용하는 경우 union all, intersect all, except all 을 쓴다.
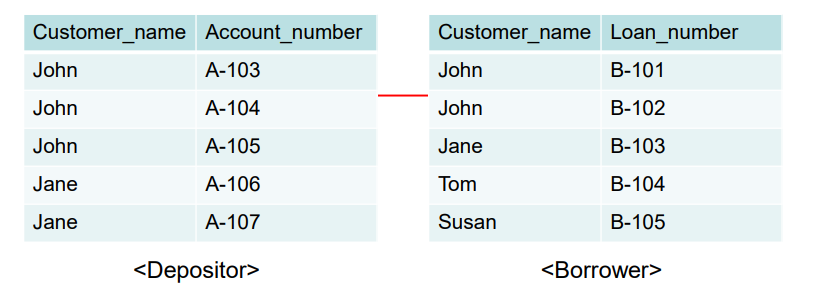

union 전에 John,jane / john, jane, Tom, Susan 으로 중복을 먼저 제거해두고 합집합한다. (단 all이 붙으면 중복을 제거해두지 않는다. union all 을 쓰면 중복을 먼저 제거해두지 않는다.)
나머지 연산도 다음 원리를 적용
1. 연산에 상관없이 all 이 들어가지 않으면 일단 튜플 중복 제거를 해둔다.
2. all 이 들어가면 중복 제거를 하지 않고 해당 연산을 무작정 한다.
Aggregate Functions
select 절에다가 결과값을 가지고 평균, 최소, 최대, 합, 개수 계산

평균 잔액?
select avg(balance)
from account
고객 테이블 튜플의 수? (count 의 경우 숫자타입이 아니어도 됨.)
select count (*)
from customer
예금주 테이블의 전체 고객 수?
select count(distinct customer_name)
from depositor
Aggregate Functions - Group By
group by att: att 기준으로 그룹 정리
- 각 지점의 계좌의 평균 잔액?
select branch_name, avg(balance)
from account
group by branch_name
- 각 지점별 예금 고객의 수는?
select branch_name, count(distinct customer_name)
from account, depositor
where account.account_number = deposiotr.account_number
group by branch_name
Aggregate Functions - Having Clause
having: group by 를 쓸 때 결과를 제한하기 위해 씀.

where 과 같은데 왜 having 을 쓰냐? 기존의 값이 아니라 group by 로 한 번 연산한 값을 사용하고 싶기 때문이다. group by 를 한 번 쓰면 지점으로 모이므로, where avg(balance) 를 쓰면 그냥 평균이 나오는 반면 having 을 써서 지점별 잔액의 평균 > 1200 인 값들을 구할 수 있다.

customer_city, account_number, balance
select depositor.customer_name, avg(balance)
from customer, depositor, account
where depositor.account_number = account.account_number and depositor.customer_name = customer.customer_name and
customer_city = 'Harrison'
group by depositor.customer_name
having count(distinct depositor.account_number) >= 3
그룹화를 계좌 기준이 아니라 사람 기준으로 해야한다. (한 사람이 여러 계좌를 가지고 있으니), 그룹화하고 계좌에 한해 3개 이상이면 select 로 가라. 한 사람에 대해서 평균을 계산하자, 하면 된다. 세 가지를 곱했으므로 where 절에서 진짜 정보를 추출하는데 까지 공통 어트리뷰트에 대해 = 을 연산을 해준다. (그냥 공통된 어트리뷰트가 있다면 = 써줘야 한다라 생각하면 편하다.)
