01 EDA란?
Exploratory Data Analysis , EDA 는 데이터를 다양한 관점에서 탐색적으로 분석하는 것을 뜻한다.
- 각 row 의 의미?
- 각 column 의 의미?
- column 사이의 관계?
... 등을 조사할 수 있다. 한마디로,
EDA에는 정답이 없다!
02 기본 정보 파악하기
위 데이터프레임을 출력하면 147개의 column을 확인할 수 있었다. 맨 끝의 7개가 기본정보를 포함하고 있어 인덱싱 해주었다.
df = pd.read_csv('downloads/young_survey.csv')
bi = df.iloc[:, 140:]
-
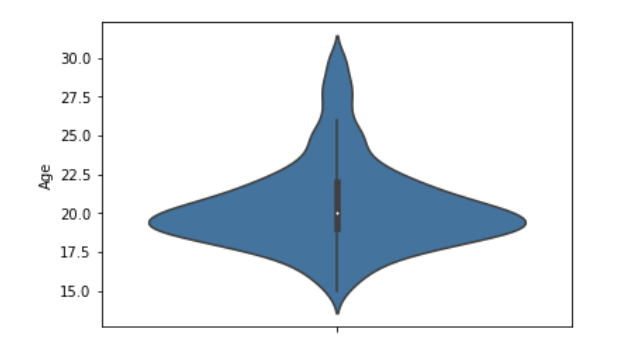
나이정보를 violinplot 으로 보고싶다.sns.violinplot(data = bi, y = 'Age')
*성별에 따른 나이 정보를 violinplot 으로 보고싶다.
sns.violinplot(data = bi, x = 'Gender', y = 'Age')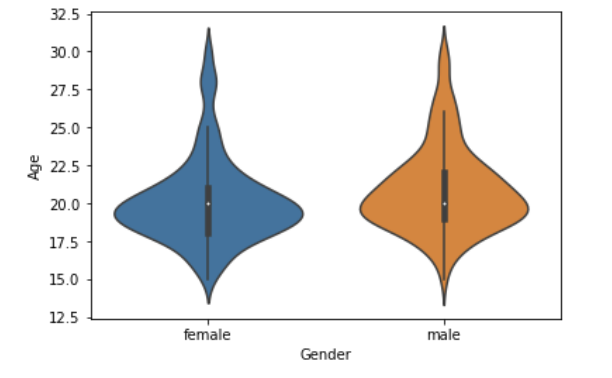
-
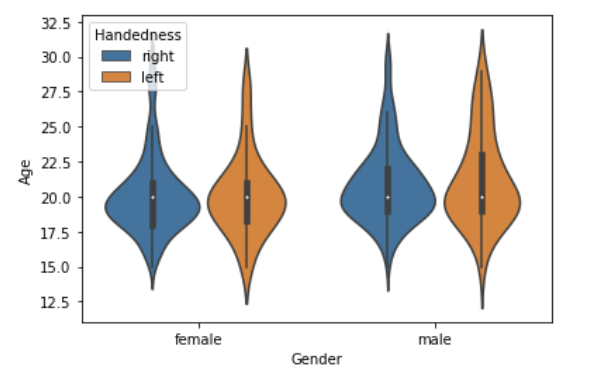
성별,손잡이에 따른 나이 정보를 보고싶다. 이럴 경우hue를 추가한다.sns.violinplot(data = bi, x = 'Gender', y = 'Age', hue = 'Handedness')
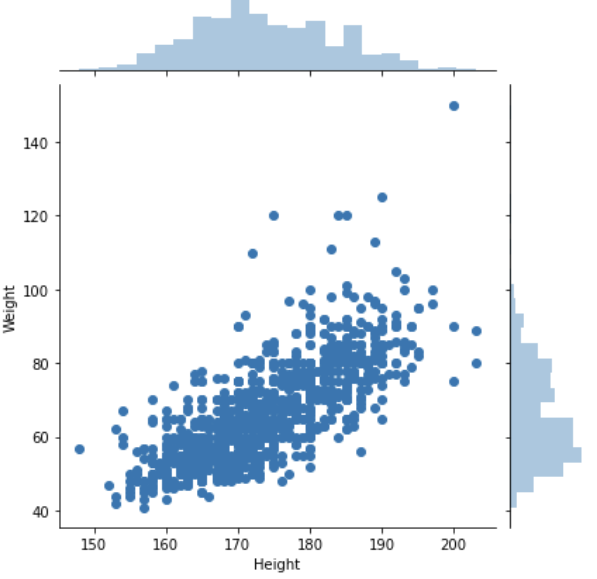
산점도와 동시에히스토그램역시나 보고싶다. 이럴 경우jointplot을 사용한다.sns.jointplot(data = bi, x = 'Height', y = 'Weight')
03 요즘 인기 직업은?
04 상관 관계 분석
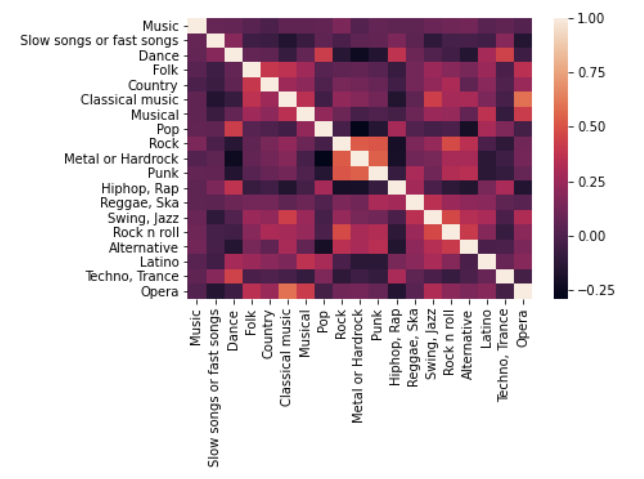
설문 조사에서 음악 선호도 관련 정보를 추출한다. (인덱싱 > corr() 함수)
df = pd.read_csv('downloads/young_survey.csv')
music = df.iloc[:, :19]
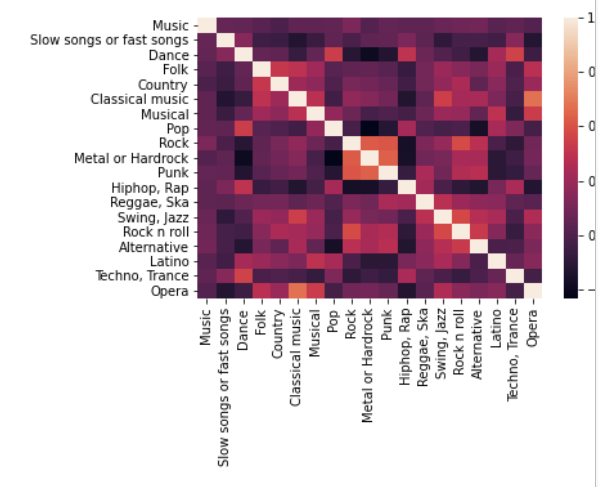
sns.heatmap(music.corr())
heatmap 으로 확인한 결과이다.
음악 정보가 아닌 나이 column 만 추출해서 상관관계를 살피는 방법도 있다. (corr() 함수, [ ] 사용)
df.corr()['Age'].sort_values(ascending = False)
나이정보는 완전히 일치하고, 그 다음으로 몸무게와 선거정도가 있다. 나이가 들어가며 쇼핑이나 과거에 대한 후회는 하지 않는다고 한다.

Mathematics, Algorithm, and IDEA for AI research🦖