01 Seaborn 소개
앞서 pandas 에 내장된 그래프를 통해 그래프를 그렸으나, 지금 살펴볼 Seaborn이 더 다양하고 근사한 그래프들을 지원한다고 한다.
02 확률 밀도 함수 (PDF)
확률 밀도 함수란 데이터셋의 분포이다.
영어로는 Probability Density Function이다.
확률 밀도함수가 나타내는 것은,
그 면적이란 특정 데이터가 그 범위 안에 속할 확률이다.
따라서 선으로 표시된 그래프 아래 면적을 다 더하면 1이 된다
다음은 실제 PDF 함수이다.
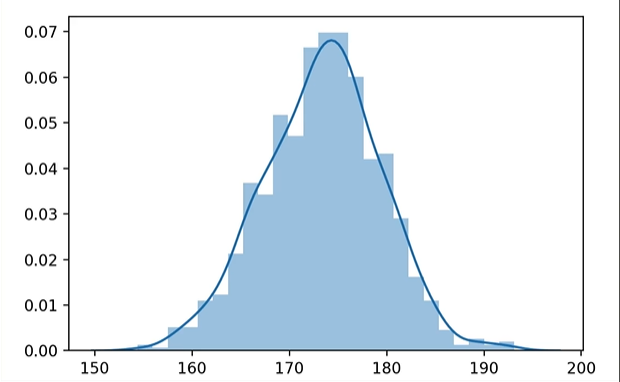
PDF 에서 특정 값의 의미란 무엇일까? 예를 들어, 위 그래프에서 175란 자료가 나타날 확률은?
안타깝지만 0이다. PDF 에서는 값이 아닌 범위만 취급한다. 예컨대 키, 몸무게, 속도 등의 자료들이 PDF 의 대상이 된다.
03 PDF 개념 확인
94 KDE PlOT
KDE 란 Kernal Density Estimation 의 약자로, 앞서 본 분포를 기반으로 추측 을 하는 것이다. 굴곡을 없애고 곡선으로 만드는 데 기여한다.
KDE를 사용하기 위해선 설치가 필요하다.
!pip install seaborn==0.9.0
여기에 기존 판다스와 seadborn 라이브러리를 모두 사용하여 KDE Plot 을 구현할 수 있다.
import pandas as pd
import seaborn as sns
bd = pd.read_csv('downloads/body.csv', index_col =0)
sns.kdeplot(bd['Height'], bw =2)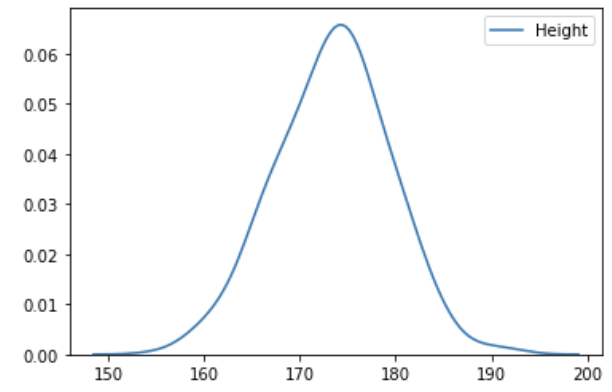
위와 같은 상태가 된다. 원래 분포를 알려면 어떻게 해야할까?
bd['Height'].value_counts().sort_index().plot()height 를 불러오고, 같은 키가 몇 번 등장했는지 세고, 그것을 오름차순 정렬한 그래프이다.
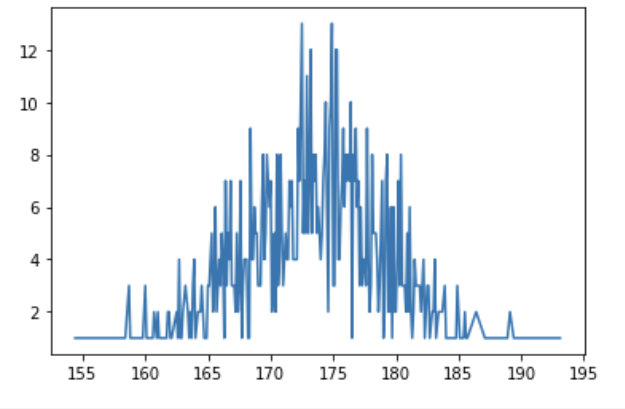
KDE는 위 그래프를 추정한 것이다. bw 값은 히스토그램의 bins 처럼 몇 번 자를지 나타내는 것으로 숫자가 커질수록 부정확하다.
05 서울 지하철 승차인원
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/subway.csv')
# 여기에 코드를 작성하세요
sns.kdeplot(df['in'])06 KDE 활용 예시
-
distplot : 히스토그램과 KDE를 함께 보여줌
sns.distplot(bd['Height'], bins = 15)
-
violinplot: 바이올린 모양으로 보여줌
sns.violinplot(y = bd['Height'])
-
kdeplot 안에 2개 : 등고선 모양으로 각각의 분포를 알 수도 있음.
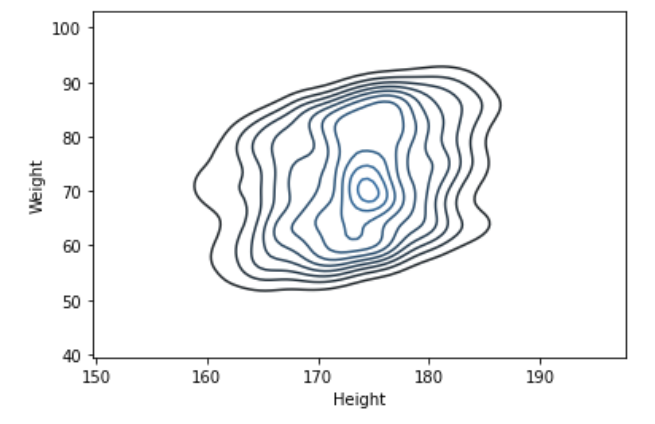
07 교수님의 연봉은?
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/salaries.csv')
sns.violinplot(df['salary'])08 LM Plot
위의 키와 몸무게 산점도로부터 생각해보자, 키로부터 몸무게를 예측할 수 있을까? 이때 kde를 이용할 수 있다.
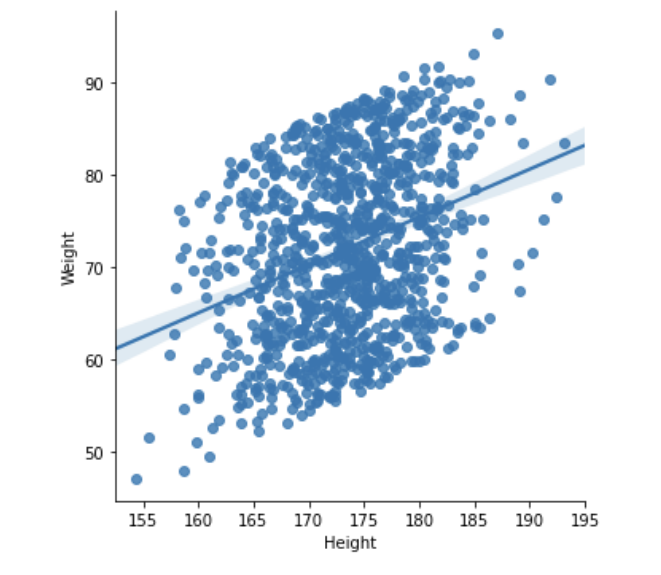
위에 보이는 파란 선은 회귀선이다. 산점도를 가로지르는, 하나로 정리할 수 있는 선을 구한 것인데, 코드는 다음과 같다 .
sns.lmplot(data = bd, x = 'Height', y = 'Weight').lmplot(data = , x= '',y ='')
일반화된 코드는 다음과 같아서, 파라미터 3개를 넣어주면 된다.
그러면 위 분포에서는 회귀선이 대표성을 지니느냐?, 그건 아니라고 본다. 선에서 너무 멀리 떨어진 점들이 있어서 좀 더 강한 관계가 필요해보인다.
09 카테고리별 시각화
다음과 같은 회사 3개가 있다.
ld['os'].unique()array(['linux', 'mac', 'windows'], dtype=object)
seadborn 을 이용하면 해당 회사 3개의 가격 정보를 동시에 확인할 수 있다. 전달해야 할 파라미터는 4개이다.
sns.catplot(data = 분석하고자 하는 데이터, x = ' ', y = ' ' , kind = '종류')
sns.catplot(data = ld, x = 'os', y = 'price', kind = 'box')
이때 kind 의 값을 조작할 수 있다.
- strip : 점으로 표기
- violin : 바이올린으로 표기
가격 정보에 processor_brand 정보를 추가해서 같이 보자. hue 로 가능하다.
sns.catplot(data = ld, x = 'os', y = 'price', kind = 'strip', hue = 'processor_brand')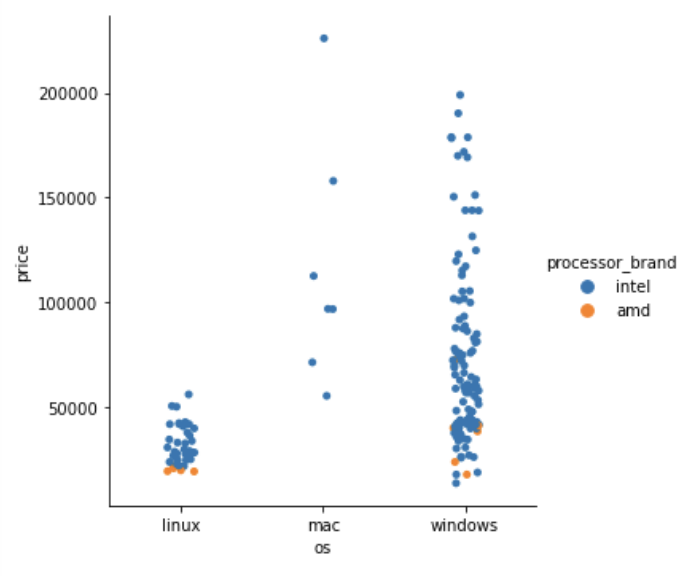
10 보험금 분석하기
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/insurance.csv')
# 여기에 코드를 작성하세요
sns.catplot(data = df, x = 'smoker', y= 'charges', kind = 'violin')