01 새로운 값 계산하기
이 챕터에선 새로운 column 을 생성하고 거기에 적당한 인덱싱을 통해 값을 집어넣는 연산을 배웠다. 일단 코드를 준비시켜보자.
%matplotlib inline
import pandas as pd
df = pd.read_csv('downloads/broadcast.csv', index_col = 0)
df
코드를 입력하세요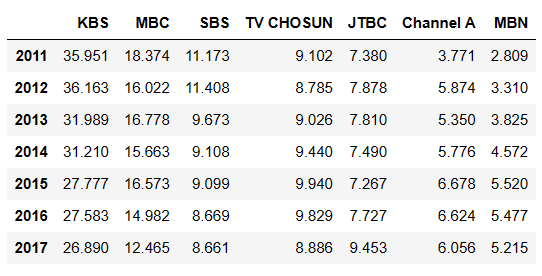
여기에다 df.plot() 을 추가하면 기본적인 선그래프는 그릴 수 있다.
그러나 지금 해볼 것은 특정 방송사들의 시청률의 합을 바탕으로 한 그래프이다.
✅ 무작정 더하기
인덱싱을 통해 무작정 더하고 .plot() 을 할 수 있다.
df['KBS'] + df['MBC'] + df['SBS'] + df['TV CHOSUN'] + df['JTBC'] + df['Channel A'] + df['MBN']그러나 너무 하드코딩이다.. 다른 방법은 없을까?
✅ .sum() 이용하기
df['Total'] = df.sum(axis = 'columns')우선 기존 모든 코드를 더했던 것을 .sum() 함수로 바꾸어줬다. sum 안에는 모든 열을 뜻하는 axis = 'columns' 가 들어가게 된다. 그걸 새로운 열에 지정해주면 된다!
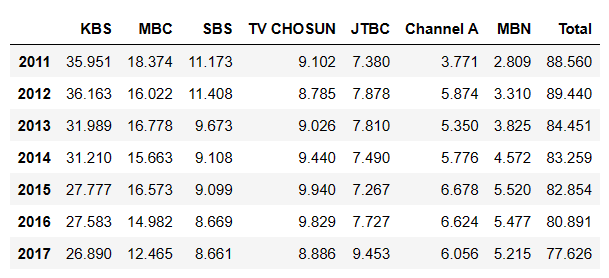
Total 만 plot을 그려보자.
df.plot(y = 'Total') 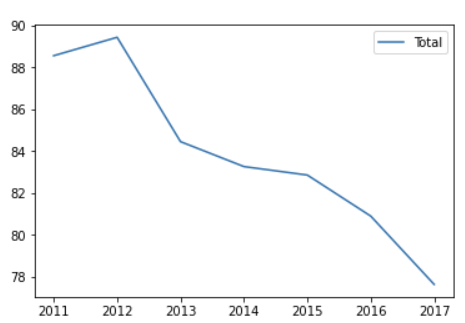
✅ 슬라이싱 + .sum()
그러나 모든 행을 더하지 않고 어느정도 원하는 값만 슬라이싱하여 더하고 싶을 수 있다.
지상파 시청률의 합을 'Group1', 종편 시청률의 합을 'Group2' 라고 하여 열 2개를 df에 추가해보자.
df['Group1'] = df.loc[:, 'KBS':'SBS'].sum(axis = 'columns')
df['Group2'] = df.loc[:, 'TV CHOSUN':'MBN'].sum(axis = 'columns')그래프를 그릴 때도 당연히 둘 다 보여야겠다.
df.plot(y = ['Group1', 'Group2'])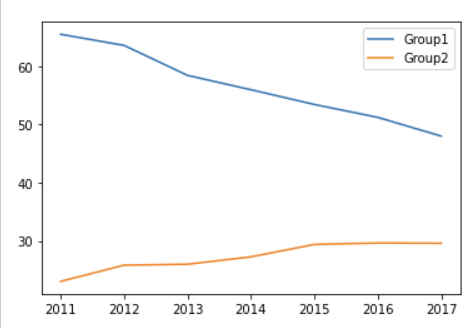
02 문자열 필터링
앨범 정보와 장르 가 포함된 df 를 만들어봤다.
df = pd.read_csv('downloads/albums.csv', encoding = 'latin1')장르 열의 이름은 Genre 였으므로 장르가 df['Genre'].unique() 로 어떤 것이 있는지 확인할 수 있었다.
여기서 Blue 가 들어간 열들만을 필터링하는 방법은 크게 3가지다.
✅ 오직 Blues 만 장르인 열 필터링
df['Genre'] == 'Blues' 를 수행하면 오직 blues 만 장르인 것들이 불리언 값으로 표현된다. 열을 얻기위해선 또다시 넣어줘야 한다.
df[df['Genre'] == 'Blues']✅ Blues 를 포함하고 있는 열 모두 필터링
이번엔 blues 를 포함하면서 다른 장르도 있는 앨범 모두를 필터링했다. str 을 쓰고, contains 를 쓴다.
df[df['Genre'].str.contains('Blues')]✅ Blues 로 시작하는 열 필터링
순서를 보아하니, blues 가 포함되이 있어도 앞에 있으면 메인 장르 인 것 같다. 장르의 첫번째에 blues 가 오는지 확인해보자. 이럴 때에는
str 을 쓰고 startswith 메서드도 사용한다.
df[df['Genre'].str.startswith('Blues')]새로운 행에 추가해보자.
df['Contains Blues'] = df['Genre'].str.contains('Blues')03 박물관이 살아있다 (1)
import pandas as pd
df = pd.read_csv('data/museum_1.csv')
# 여기에 코드를 작성하세요'
df['분류'] = '일반'
filter = df['시설명'].str.contains('대학')
df.loc[filter, '분류'] = '대학'
df일반 '분류' 컬럼을 만들어 '일반'을 다 할당했다.
그리고 나서 시설명에 '대학' 이 써져 있는 것을 불리언 값으로 filter 에 담았다.
따라서 filter 는 열마다 True 또는 False 가 적혀져 있는 index 정보이다. (열에 해당)
그러므로 .loc[열, 행] 할당을 잘 해주고, filter 에 해당하는 것은 대학으로 바꿔준다.
04 문자열 분리
다음과 같은 df에서 새로운 컬럼에 관할구역을 저장하고 싶다.
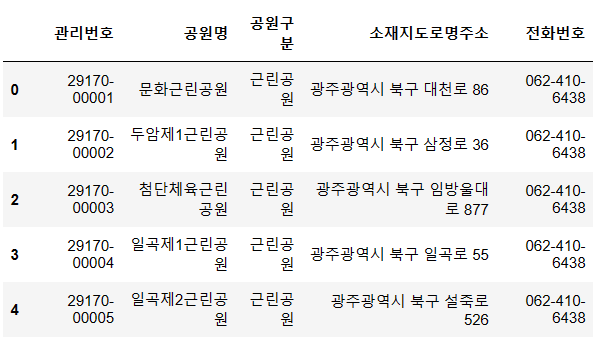
소재지도로명주소 에 담긴 광주광역시 등을 꺼내고 싶은 것인데, 이때는
.str.split 을 사용한다.
.str.split(spat= '무엇으로 쪼갤지', n = 앞에서부터 몇 번 자를지, expand = True)
여기서 n 은 앞에서부터 몇번 자를지 지정하는 수를 말한다. 예컨대 1이면 광주광역시 / 북구 대천로 86 이고, 2이면 광주광역시 / 북구 / 대천로 86 이다.
expand 는 이것을 데이터프레임으로 이쁘게 확장시킬까 하는 것이다. 활용할 것이라면 True 를 써주자.
df = pd.read_csv('downloads/parks.csv')
df['소재지도로명주소'].str.split(n = 1, expand = True)
address = df['소재지도로명주소'].str.split(n = 1, expand = True)
df['관할구역'] = address[0]마지막으로 새로운 컬럼에 address[0]을 할당했다. 출력해보자.
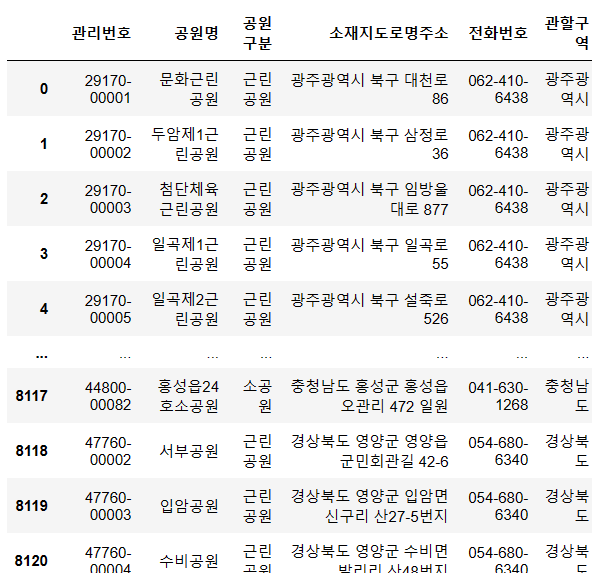
관할구역만 잘 나온 것을 확인할 수 있다!
05 박물관이 살아있다 (2)
import pandas as pd
df = pd.read_csv('data/museum_2.csv')
# 여기에 코드를 작성하세요
num = df['운영기관전화번호'].str.split('-', expand = True)
df['지역번호'] =num[0]
df흥미로운 것은 expand = True 가 입력되기 전까지는 답이 되지 않는다는 것이다.
중요한 점이라 기록해두면,
expand = True 은 데이터프레임을 만드는 역할을 하며,
그렇지 않으면 스플릿으로 쪼갤 시 Series 객체가 된다.
Series 객체는 df['지역번호'] = num[0] 과 같이 할당할 수 없다.
06 카테고리로 분류
다음과 같은 df에서 브랜드를 각 나라와 연결시키려면 어떻게 해야할까?
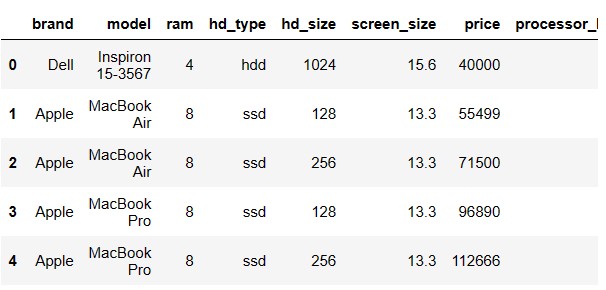
brnad_nation 이라는 자료는 내가 입력한 것이다. (딕셔너리)
brand_nation = {
'Dell': 'U.S',
'Apple': 'U.S',
'Acer': 'Taiwan',
'HP': 'U.S',
'Lenovo': 'China',
'Alienware': 'U.S',
'Microsoft':'U.S',
'Asus': 'Taiwan'
}map() 을 사용한다. map 을 사용하면 행과 내가 작성한 딕셔너리를 연결시켜, 딕셔너리 키 값이 행의 값에 있으면 딕셔너리 value 값으로 바꿔준다.
df['brand_nation'] = df['brand'].map(brand_nation)결과는 다음과 같다.
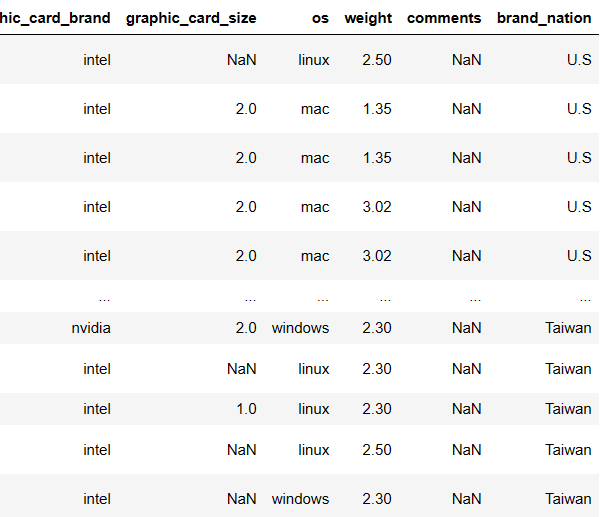
brand_nation 컬럼에 브랜드 이름(기존컬럼, 딕셔너리의 키)에 해당하는 국가(딕셔너리 벨류) 가 할당되었다!
07 박물관이 살아있다 (3)
import pandas as pd
df = pd.read_csv("data/museum_3.csv", dtype={'지역번호': str})
# 코드를 작성하세요.
dic = {'02' : '서울시',
'031' : '경기도',
'032' : '경기도',
'033' : '강원도',
'041' : '충청도',
'042' : '충청도',
'043' : '충청도',
'044' : '충청도',
'051' : '부산시',
'052' : '경상도',
'053' : '경상도',
'054' : '경상도',
'055' : '경상도',
'061' : '전라도',
'062' : '전라도',
'063' : '전라도',
'064' : '제주도',
'1577' : '기타',
'070' : '기타'}
df['지역번호'] = df['지역번호'].map(dic)
df.rename(columns= {'지역번호': '지역명'}, inplace = True)
dic09 Groupby
방금은 map 을 통해서 브랜드 : 국가로 매칭하는데 성공했다.
그러면 brand_nation 에 여러 반복되는 국가들이 등장하는데, 이들을 효율적으로 볼 수 있는 방법은 없을까?
groupby('column') 는 파라미터 안의 컬럼 자료들을 그룹화시켜주는 것이다.
예컨대 같은 컬럼에 한국, 중국, 일본이 있다면 그룹화를 시키고, 다양한 메서드들을 이용할 수 있다.
여기서 볼 메서드는 .count() , .max() , .mean() , .first() , .last() 이다.
먼저 groupby 를 사용하려면 새로운 변수에 할당해주자.
ng = df.groupby('brand_nation')
ng.count()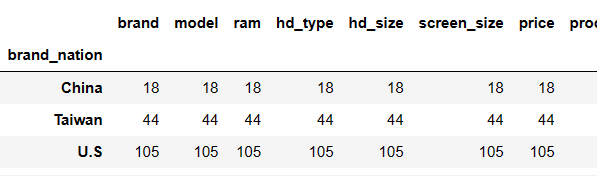
ng.max()국가별 최대값 들을 보여준다.
ng.mean()국가별 평균값 들을 보여준다.
ng.first()국가별 처음값 들을 보여준다.
ng.last() 국가별 마지막값 들을 보여준다.
ng.plot(kind = 'box', y = 'price')국가별 박스플롯 들을 보여준다.
09 직업 탐구하기 (1)
import pandas as pd
df = pd.read_csv('data/occupations.csv')
# 여기에 코드를 작성하세요
age = df.groupby('occupation')
age =age.mean()['age'].sort_values(ascending = True)
age
✅ 주의! sort_values 는 앞에 '무엇을' 이 지정되어야 한다.
그렇기 때문에 위의 코드에서도 mean() 으로 평균내면 age 밖에 없는데도 굳이 ['age'] 로 인덱싱 해준 것이다.
10 직업 탐구하기 (2)
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group = df.groupby('occupation')
# occupation_group.mean() 을 여기서 한번 실행하면 KeyError 발생
df.loc[df['gender'] == 'M', 'gender'] = 0
df.loc[df['gender'] == 'F', 'gender'] = 1
occupation_group.mean()['gender'].sort_values(ascending=False)이 코드 리뷰를 시작으로 내일 공부 해야겠다.
