01 머신러닝이란?
머신 러닝 (Machine Learning) 이란 기계가 스스로 학습하는 것을 뜻한다.
잘 와닿지 않는다. 일반프로그램과 무엇이 다른가?
스팸 메일 처리 프로그램을 구현한다고 해보자.
일반 프로그램은 이를 위해 스팸 메일과 그렇지 않는 메일을 구분하기 위한 규칙 이 필요하고, 이러한 규칙은 사람 에게서 나온다.
그러나 머신 러닝은 그러한 규칙 을 스스로 학습 하는 것을 말한다.
다시, 머신러닝의 정의로 돌아와서
머신러닝이란 작업에 대한 성능을 경험을 통해 향상시키는 것 을 의미한다.
작업 이란 스팸 메일을 걸러내는 것, 경험 은 메일을 확인하며 규칙을 보완하는 것, 성능은 스팸 메일을 걸러낼 확률을 뜻한다.
02 머신 러닝이 핫해진 이유
처리할 수 있는 데이터의 양 증가
컴퓨터 성능의 향상
*머신러닝 활용성 입증 (사용자의 편리 + 수익 창출)
03 인공지능? 빅데이터? 머신러닝?
✅ 빅데이터
굉장히 많은 양의 데이터를 다루는 분야를 빅데이터라고 함
많은 양의 데이터 보관, 관리
*많은 양의 데이터 분석
✅ 인공지능
프로그램이 인간처럼 생각하게 하는 학문
인공지능 달성의 수단이 머신러닝
✅ 딥러닝
머신러닝 기법 중 하나
프로그램 학습 시키는 방법 중 하나
*layer 가 깊어진다 > 딥러닝
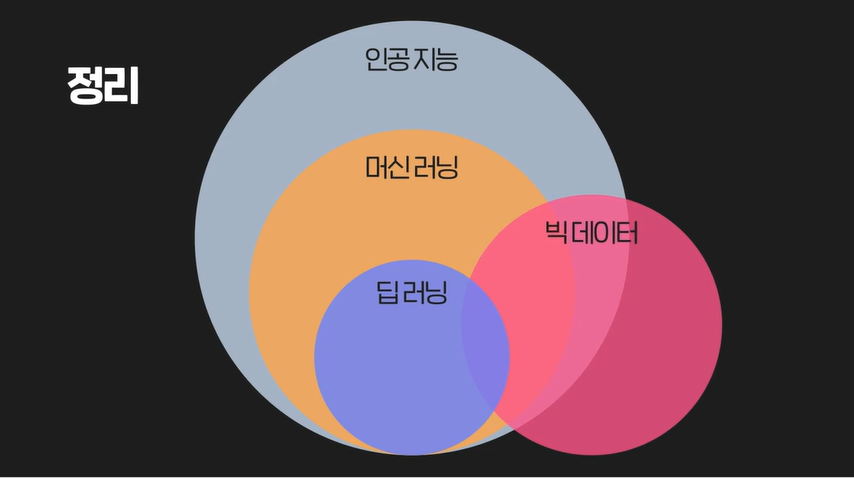
인공지능이 가장 밖. 인간처럼이라는 목표. 머신러닝은 그것을 달성하기 위한 방법으로 데이터를 통해 성능을 향상시키는 프로그램. 딥러닝은 머신러닝 기법 중 하나.
빅데이터는 모든 분야에서 사용되는 많은 양의 데이터로, 데이터 관리와 분석 분야.
04 학습의 유형
머신 러닝의 학습 방법
지도학습
비지도 학습
*강화 학습
✅ 지도 학습 (Supervised learning)
*'답' 이 있고 답을 맞추는 게 학습의 목적 (스팸 메일 분류 프로그램)
분류 (Classfication)
이것이냐, 저것이냐 (스팸 메일 분류)
회귀 (Regression)
결과값이 무수히 많고, 연속적. (아파트 가격 예측)
프로그램에게 수많은 문제와 문제에 대한 답 을 가르쳐줬다.
✅ 비지도 학습 (Unsupervised learning)
'답' 이 없고 답을 맞추는 게 학습의 목적 (나름의 기준을 스스로 세움)
여러 글들 중 어떤 부분이 비슷한가? (주제, 길이, 단어 선택 등등..)
문제에 대한 답 을 가르쳐주지 않았다.
05 K-NN 알고리즘
k-최근접 이웃 알고리즘 (k-Nearest Neighbors Algorithm)
예측해야 할 데이터와 관련, 그 위치 주변의 가장 가까운 데이터 k개를 바탕으로 예측.
데이터가 많아질 수록 성능의 향상을 기대할 수 있으므로 머신러닝이 많음.
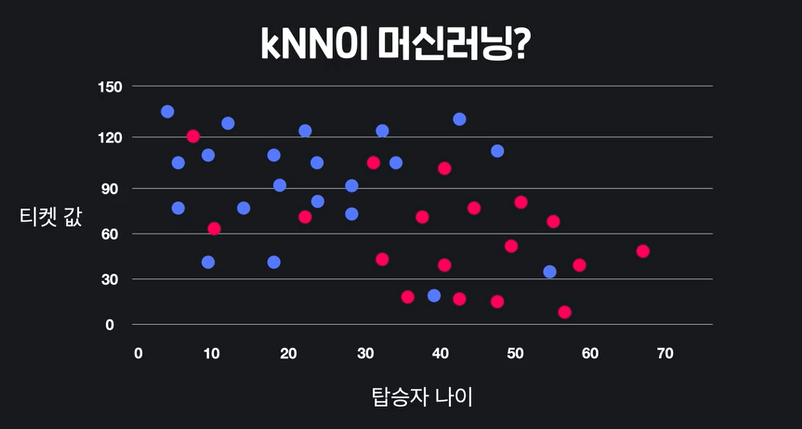
탑승자 나이에 따른 티켓값, 빨간색은 생존, 파란색은 죽음이다.
위 데이터에서 10살의 130을 지불한 아이는 살았을까? k 를 5라고 하면, 가장 가까운 4명은 사망, 1명은 생존이므로 사망하였을 것으로 추정한다.
06 머신 러닝의 수학
컴퓨터 과학 + 수학 분야.
상황에 맞게 알고리즘 선택, 코드 최적화를 위해선 이론이 필요하고, 수학이 필요하다.
어떤 수학이 쓰일까?
✔ 선형대수: 행렬. 데이터들을 행렬로 묶음.
✔ 미분: 머신러닝의 최적화에 사용.
✔ 확률과 통계: 데이터 특징 파악에 사용.
