[Machine Learning]
1.머신러닝이란?
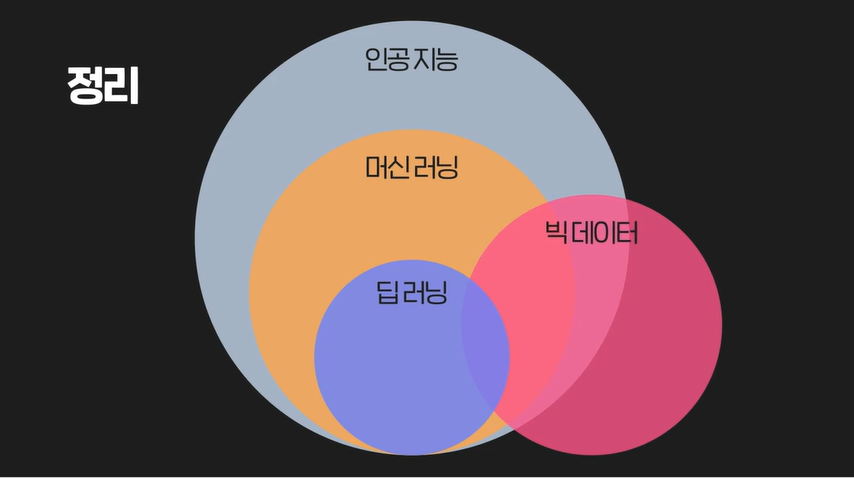
머신 러닝 (Machine Learning) 개념 찍먹
2.선형대수학
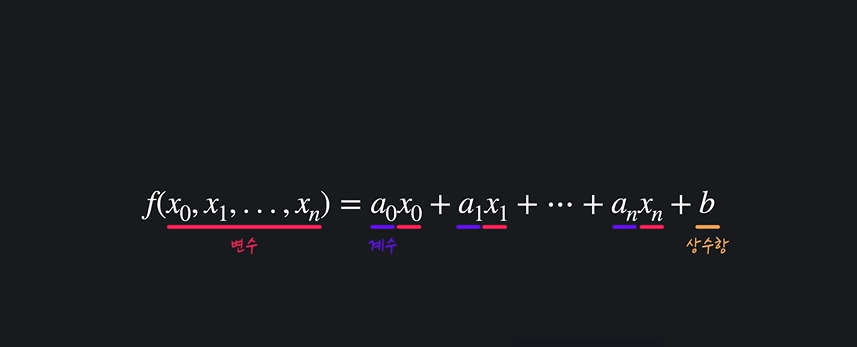
행렬의 쌩기초에 대해 알아보자. 덧셈과 스칼라 곱, 행렬 곱까지!
3.선형대수학 (2)
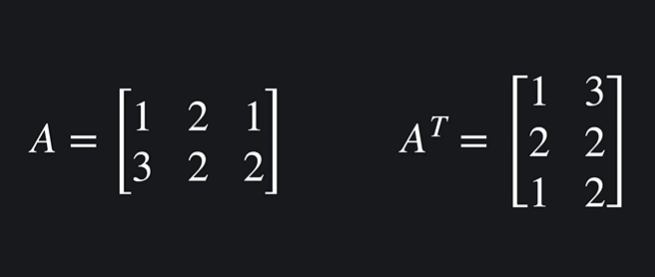
지난 포스팅에 이어서 행렬을 더 다뤄보자.일반 덧셈은 스칼라 곱은 행렬 간 곱은 @ 을 사용한다. 행렬의 곱은 \* 이 아닌 @ 임에 유의하자. np.dot(A,B) 로도 계산할 수 있다. A의 행렬의 열과 행을 바꾼 행렬 을 뜻한다. T를 써서 표기한다. 행렬의 모
4.미분
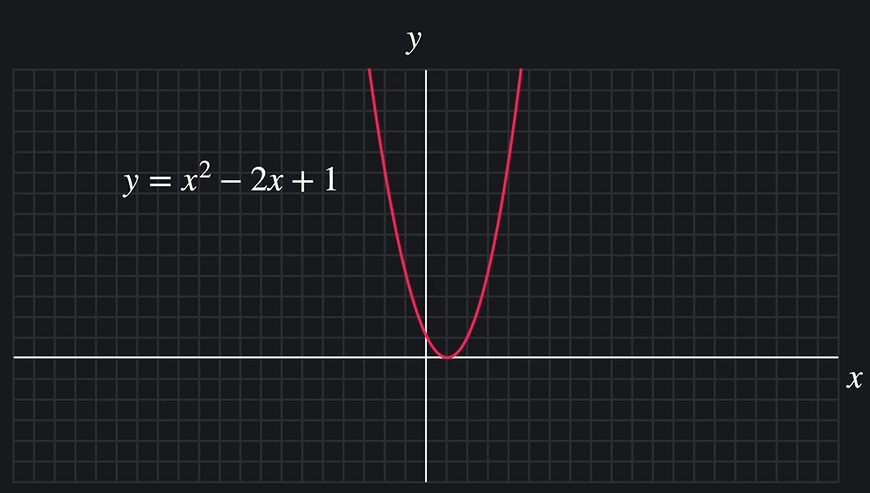
함수와 기울기, 편미분과 벡터의 쓰임을 머신러닝과 관련지어보자.
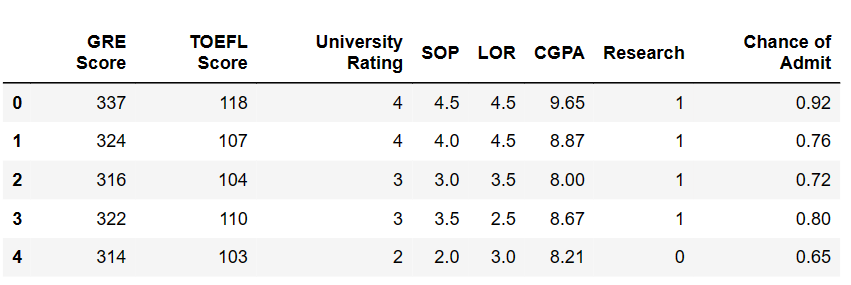
5.선형 회귀 (Linear Regression)
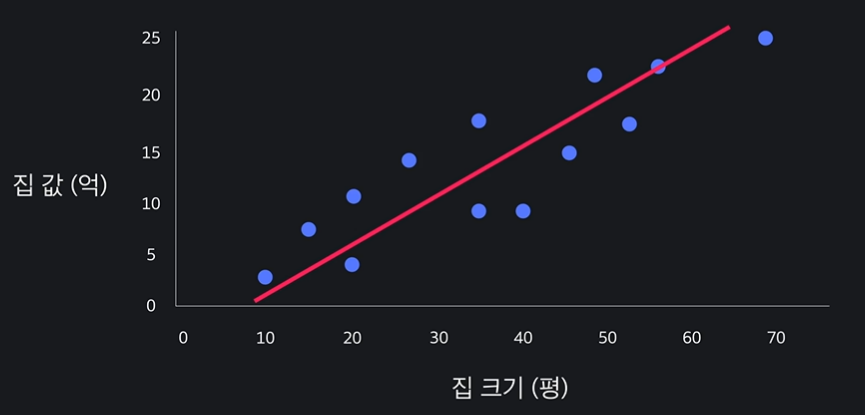
선형회귀에 대해서 알아보자.
6.선형 회귀 (2)
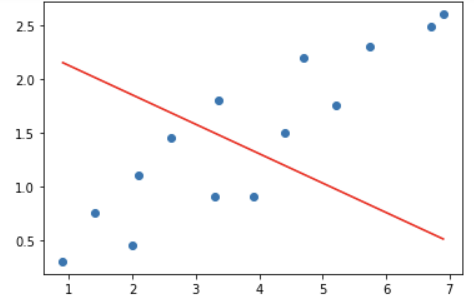
선형 회귀 두 번째. 손실을 보여주는 방법과 선형 회귀를 코드로 구현하는 방법을 알아보자. scikit-learn 에 대해서도!
7.다중 선형 회귀
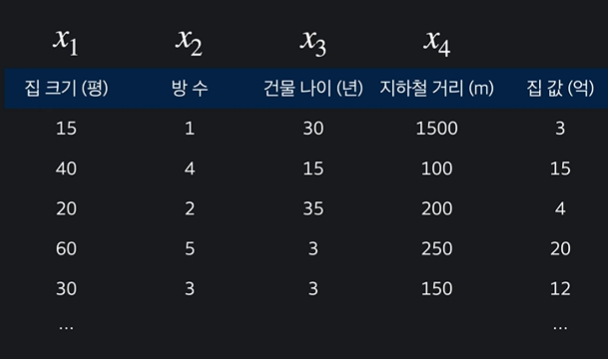
다중 선형 회귀 (Mutiple Linear Regression)는 입력변수를 여러개로 추가하는 것이다. 다중 선형 회귀의 계산 구현을 알아보고, scikit-learn 을 통해서 실행시켜보자.
8.다항 회귀
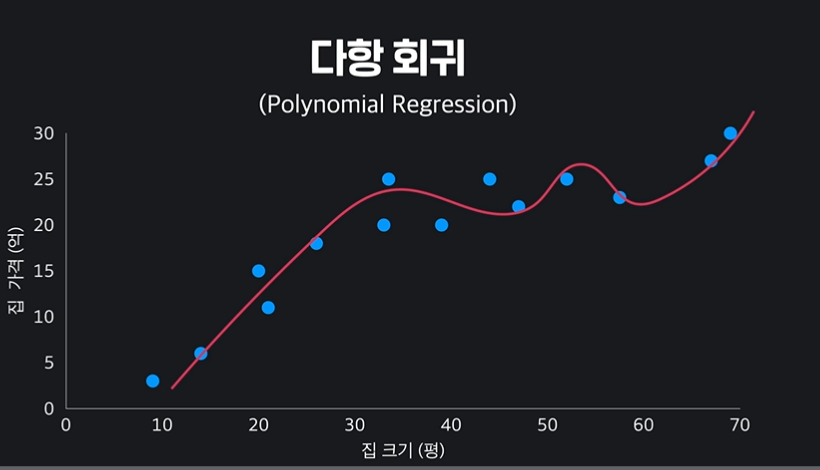
선형 회귀에서 나아간 다차항의 회귀 기법을 공부하자. 알고보면 비슷하다.
9.로지스틱 회귀
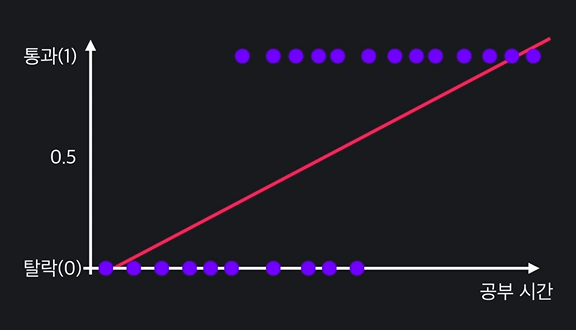
01 분류 문제 회귀, 분류 > 분류는 정해진 값 중 예측. 회귀는 연속적이 값 예측. 예컨대 집 값을 예측하는 것은 회귀 문제이지만 이 이메일이 스펨메일인지 아닌지는 분류 문제이다. 그러나 분류 문제도 다음과 같이 선형 회귀로 나타낼 수 있기는 하다. 0과 1로 아예 나누고, 선을 그어 다음 데이터에 대해 판단하면 되기 때문이다. 그러나 선형 회귀...
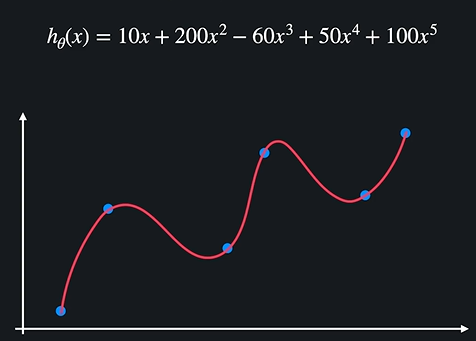
10.정규화 (Regularization)
01 편향과 분산 (Bias, Variance) >편향 : 주어진 데이터를 모델이 얼마나 잘 반영하는지. 예컨대 하나의 점에서 이를 이어 버리는 곡선이 직선보다 편향이 낮을 수 있다. >분산 : 데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는지. (하나의 가설함수, 여러 데이터 셋 안에서) 예를들어 곡선이 직선보다 다른 데이터에선 성능이 낮아져서...
11.정규화 Regularization (2)
지난번 학습한 과적합 (overfit) 현상을 방지해주는 정규화에 대해서 알압보자.
12.모델 평가와 하이퍼파라미터 (K겹 교차 검증)
모델을 평가하는 k겹 교차 검증과 GridSearch 에 대해서 알아보자
13.KoNLPy
한국어 자연어처리를 위한 패키지 KoNLPy 에 대해
14.TF-IDF
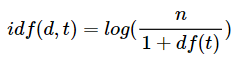
TF-IDF 는 단어 빈도- 역 문서 빈도로, 단어에 대한 중요도를 계산할 수 있는 하나의 가중치이다
15.LDA 토픽 모델링
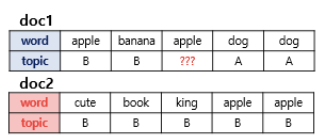
LDA는 잠재 디리클레 할당이라 불리는 기법으로, 토픽 모델링의 대표적인 알고리즘 중 하나이다
16.결정트리 (Decision Tree)
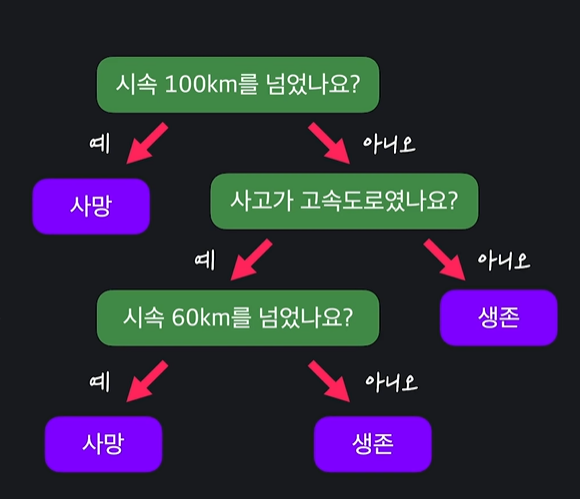
결정트리란 예 / 아니요로 답할 수 있는 질문들이 있으며, 이 질문들에 답해나가며 원하는 값을 분류하는 머신러닝의 알고리즘이다.
17.랜덤 포레스트 (Random Forest)

트리 모델들을 임의로 많이 만들어서 투표에 의해 결정하는 것을 랜덤 포레스트라 한다.🌳
18.데이터 분석 도메인의 이해
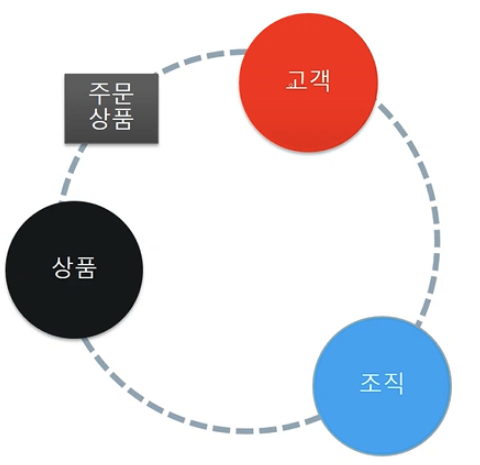
데이터 분석 도메인이란 무엇일까?🖼️
19.ML을 위한 데이터 분석 이해 (중요)
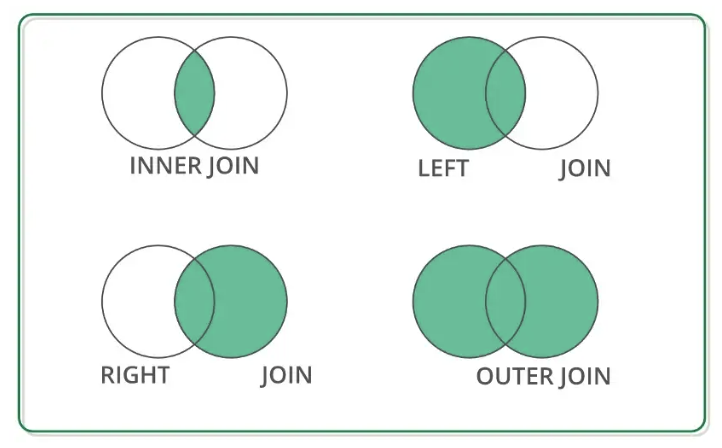
데이터 분석의 기초가 되는 merge 와 group by 에 대해 알아보고 자유롭게 쓸 수 있을 때까지 가보자🙌
20.ML을 위한 데이터 분석 이해: Group by Case when, Feature Engineering
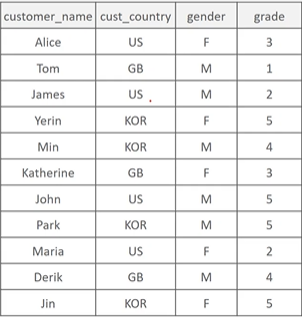
Group by 의 연산을 넘어 역할을 이해하고, feature Engineering 구체적인 방법론을 고민해보자.🎁
21.LightGBM
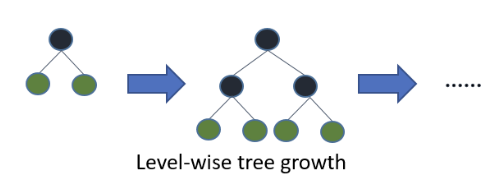
LightGBM 개요와 특징, 등장배경과 하이퍼 파라미터들을 알아보자.
22.Bayesian Optimization
미지의 함수가 반환하는 값의 최대값을 매우 짧은 반복을 통해서 찾아내는 최적화 방식.
23.Bayesian Optimization 을 이용한 LightGBM 하이퍼 파라미터 튜닝

하이퍼 파라미터 튜닝하기
24.Home Credit Default Risk - Code Review

코드리뷰 & 리팩토링을 해보자.
25.[ML] 분류 단원 함수 정리하기
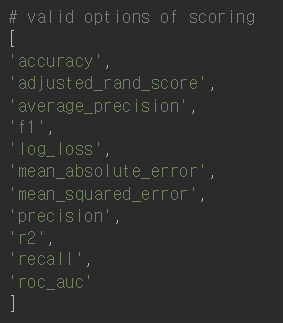
이건 알아야 한다!
26.[ML] #로짓, 소프트맥스, 크로스엔트로피
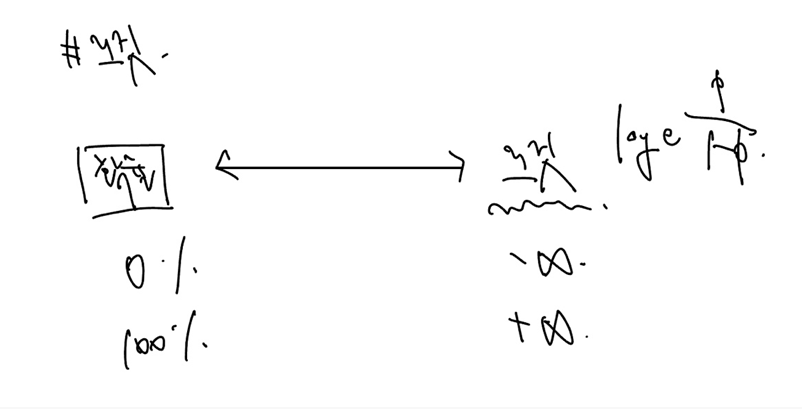
잠이 안와 정리하는 로짓 소프트맥스 크로스엔트로피😴
27.[ML] SVM 이론 이해 (1)
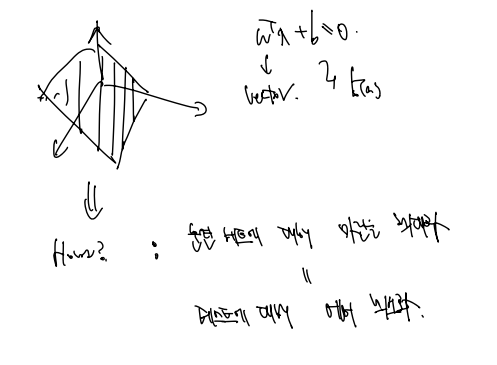
SVM 수학
28.[ML] SVM 이론 이해 (2)
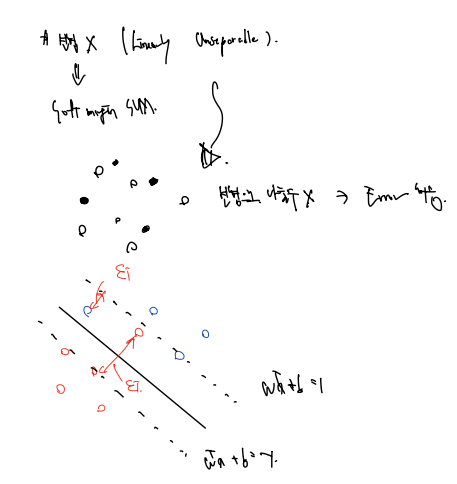
어렵다..🤒
29.[ML] 분산과 편향
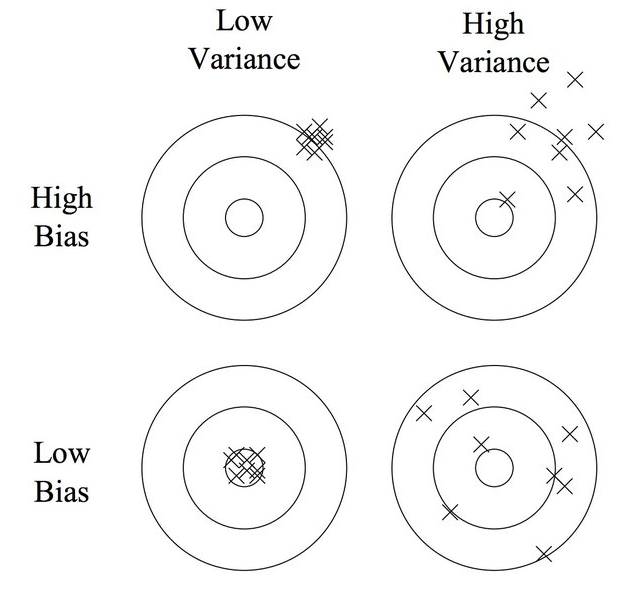
머신러닝 분야에서 지도학습과 관련하여 에러를 측정하는 중요한 지표로 분산과 편향을 든다. 이번에 분산/편향을 살펴보는 것은 앙상블 기법을 공부하던 도중 대부분의 앙상블 기법이 편향은 조금 높이지만 분산은 낮춘다는 효과가 있다는 것을 확인했는데, 와닿지 않아서이다. 편향
30.[ML] 부스팅과 배깅은 무엇이 다른가?
부스팅과 배깅 정리 이전에 학습했던 배깅의 경우 앙상블 기법 중 하나이고, 배깅의 결과로 예컨대 하나의 의사결정나무를 사용했을 때보다 편향은 조금 증가하더라도 분산을 낮출 수 있다고 하였다. (과적합 방지) 그리고 또다른 앙상블 기법으로 부스팅이 등장하는데, 여러 부스
31.[ML] AdaBoost
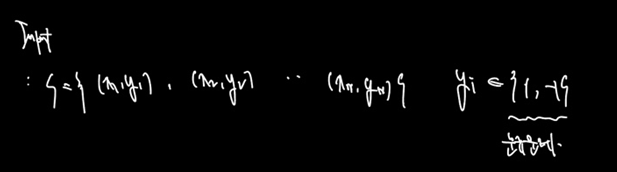
부스팅 기법은 이전 모델이 틀렸던 예측을 보완? > 과소적한 훈련 샘플의 가중치를 높여서 새로운 모델을 만드는 기법 (아이디어) 를 사용한다. 이런 식으로 가중치를 업데이트 해가며 새로운 모델을 만드는 것이 AdaBoost 의 방법이다! 기본적으로 경사하강법과 비슷하지
32.[ML] 차원 축소 (PCA)
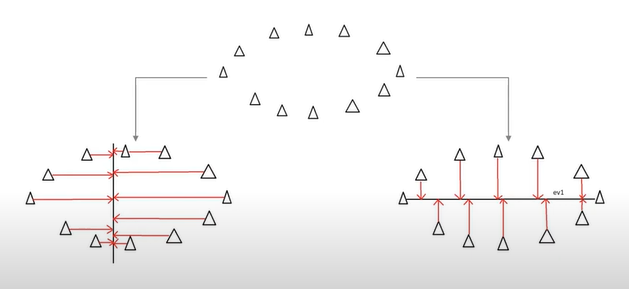
적은 차원에서 서로가 직교하는 기저를 찾는 것, 원래 데이터의 분산을 최대한 보존하는. 예컨대 3차원 데이터에서 2차원 데이터로 축소하더라도 분산을 최대한 유지하자는 것. 그렇다면 어떤 기저가 더 선호될까? 적은 차원으로 투영했을 때 분산이 최대한 큰 것이 선호된다.
33.# ml01
The Perceptron 퍼셉트론은 딥러닝이나 머신러닝의 항상 첫 장에 등장하는 기초모형이다. 아래와 같은 퍼셉트론 모델에선 입력이 x1, x2 로 2개인데, 각각의 입력에 가중치를 곱한 값에 bias T를 더한 값을 sum 하고, 함수를 한 번 더 적용시킨다. 인
34.# ml02
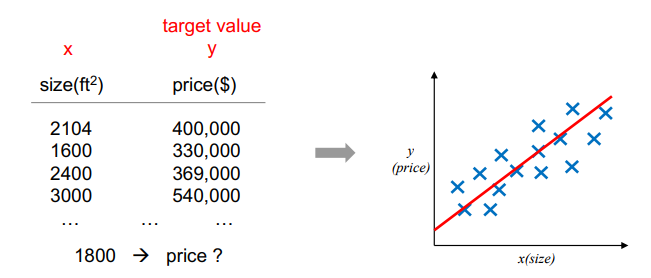
From x (input) => predict y (output, continuous) 이전과 다르게 continuous 한 예측을 하는 것을 회귀분석, Regression 이라 이해할 수 있다. 정확히는 다음과 같이 표시한다. Regression: constructi
35.# ml06
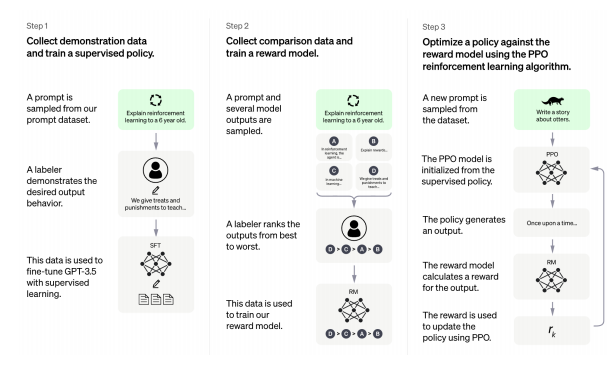
The alignment problem lack of helpfulnessHallucinationsLack of interpretabilityGenerating biased or toxic output applied to ChatGPT three main steps: