1. RNN(Recurrent Neural Networks)
RNN 전체 개요
순환신경망 -> 시간적으로 연속성이 있는 시퀀스 데이터를 처리하기 위해 고안된 신경망이다. 시퀀스 데이터란, 순서가 있는 데이터로, 순서에 의해서 의미가 생겨나는 데이터이기도 하다. 따라서 우리가 흔히 사용하는 '문장'도 결국 순서가 있기 때문에 RNN으로 처리하기 좋은 시퀀스 데이터이다.
예를들어 'I am a boy' 라는 문장이 있다면, 'I am' 만 들어도 뒤에 무엇이 올 지 대충은 예측할 수 있겠다. 또한 주식, 날씨 등 일상생활과 밀접한 것들도 RNN으로 처리될 수 있는 데이터이다. ('시간의 순서를 딥러닝으로 학습한다'라고 한다.)
🤔기존 네트워크와는 무엇이 다른가?
기존 DNN 단순한 네트워크의 경우 한 시점에 한 출력만 갖는 형태이다. 그러나 RNN의 경우 시점이 펼쳐져있고 (현재 시즘 t까지 올때까지 정보가 있고) 이전 시점의 데이터를 요약한 메모리를 갖는다. 따라서 마지막 메모리의 경우, 모든 입력의 요약 정보를 가지게 된다. (<-> 한 시점에 하나의 정보를 계산하는 기존 네트워크와 차이가 있다.)
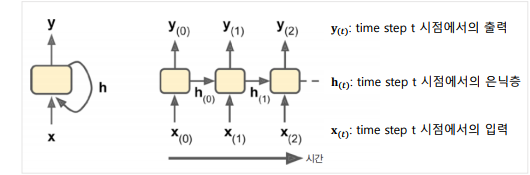
✅ 내부구조
- 'I' 라는 단어가 들어온다면 이 단어의 표현을 네트워크에 입력으로 준다.
- 가중합을 계산하여 y0을 만든다. (간단한 FFNN)
- 해당 정보를 h로 만들어 'love' 의 정보와 함께 또다시 입력으로 준다
- 가중합을 계산하여 y1을 만든다. ('I', 'love' 의 정보가 모두 계산된 결과)
- 이제까지 'I' 'love'의 값을 h1으로 만들어 'it'의 표현과 함께 준다
- 가중합을 계산하여 y2를 만들고
- 마지막 모든 입력 문장에 대한 요약정보 h2를 반환한다.
✅ RNN 네트워크 유형
입력과 출력 형태, 사용하는 정보에 따라 네트워크 유형이 구분된다.
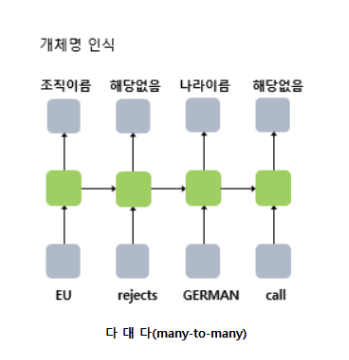
- Sequence-to-sequence (시퀀스 투 시퀀스, many-to-many)
입력 시퀀스를 받아 출력 시퀀스를 만드는 형태를 말한다. 이때 시퀀스란, 아까 언급했던 대로 시간의 흐름에 따른 정보를 모두 간직하는 것을 말한다.
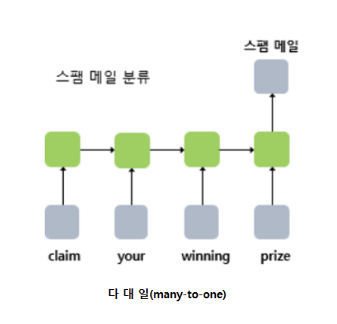
- Sequence-to-vector (시퀀스-투-벡터, many-to-one)
입력은 시퀀스이고, 출력은 다른 출력은 놔두고 마지막 값만 이용하는 것을 뜻한다. 예컨대 스팸분류 task 가 있다면, 문장은 모두 입력으로 받되, 사이의 모든 입력 시점에 대한 출력은 필요가 없고, 결과적으로 그 문장이 스팸인지 아닌지에만 관심있기 때문에 이때에 사용할 수 있다.
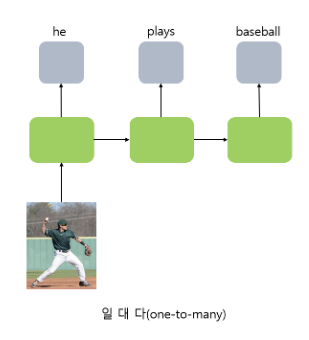
-
Vector-to-sequence (벡터-투-시퀀스, one-to-many)
각 타임스템에서 하나의 벡터만 반복해서 주입하고, 출력은 시퀀스로 출력하는 것을 말한다. 예컨대 이미지 하나를 입력으로 받고 입력에 대한 설명을 문장, 즉 시퀀스로 출력하고 싶을 때 사용할 수 있다.
-
Encoder-decoder (인코더-디코더, many-to-many)
Sequnce to vector + vector to sequence 를 연결한 것이다. 예컨대 한국어 문장을 하나의 벡터를 만들고, 벡터를 가지고 영어 문장을 만들어내는 기계번역에서 사용할 수 있다.
🤔 왜 Sequence-to-sequence 로 처리하지 않을까? 그 시점에서 하나의 단어만 보고 다른 언어로 번역하는 것은 맥락을 고려하지 못한다는 오류가 발생할 가능성이 있기 때문이다.
따라서 하나의 언어의 문장을 모두 보고, 다른 언어로 전환시켜 번역하겠다는 의도를 가지는 것.
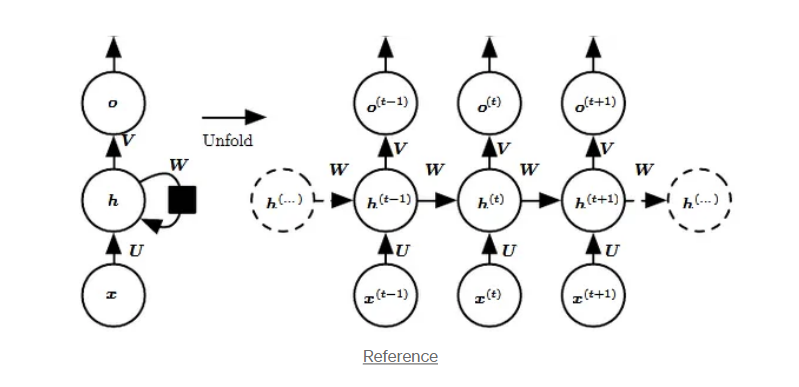
✅ 아키텍쳐
-
Input: time step t에서의 단어 x
-
Hidden state: h(t) 는 time step t에서의 표현을 뜻하고 네트워크의 메모리처럼사용한다. 현재 인풋과 이전 시점의 메모리 셀을 가져와서 계산한다. h(t) = f(U x(t) + W h(t−1)).
-
Weights: RNN의 인풋은 가중치 matrix U에 의해 파라미터화되고, 히든 레이어의 연결은 가중치 matrix W에 의해 파라미터화된다. 또한 hidden 레이어와 output 은 가중치연결 V에 의해 파라미터와 된다. 중요한 것은 U, W, V가 한 시점에서 모두 공유된다는 점이다. (for 효율적인 학습)
-
Output: o(t)은 네트워크의 출력을 나타낸다. In the figure I just put an arrow after o(t) which is also often subjected to non-linearity, especially when the network contains further layers downstream.
✅ 문제점
RNN의 가장 단순한 형태를 바닐라 RNN이라고 한다. 바닐라 RNN은 시점이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생한다. 왜? 오차가 멀리 전파될수록 계산량이 많아지고 전파되는 기울기의 양이 점점 적어지기 때문이다. 따라서 가장 중요한 정보가 앞 쪽의 시점에 위치할 경우 바닐라 RNN의 경우 앞 쪽의 중요한 정보가 뒤로 오면서 정보량의 손실이 일어나게 된다. 이를 RNN의 장기 의존성 문제라 한다.
이러한 문제를 보완하기 위해서 장단기 메모리 LSTM과 게이트 순환 유닛 GRU가 있다.
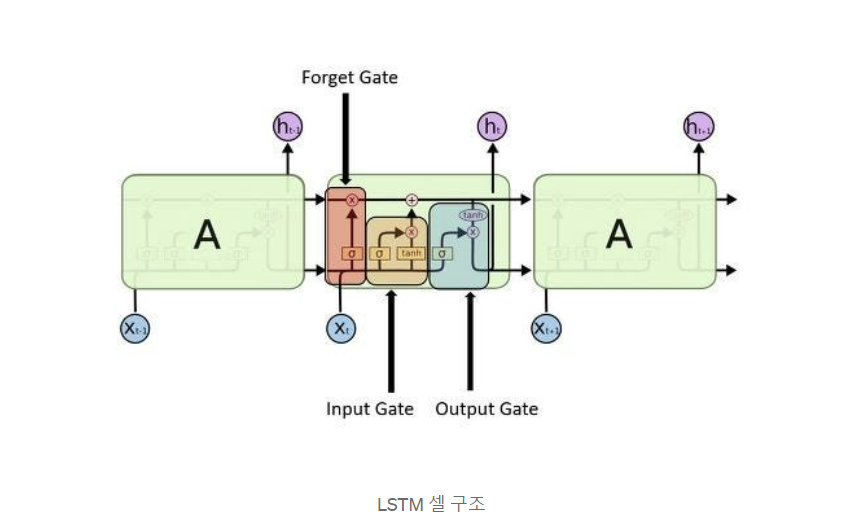
➡️LSTM (Long shor-term memory)
기본 RNN이 갖는 단기 기억 메모리 + 장기기억 메모리를 추가한 신경망 구조이다. 이전 바닐라 RNN은 h 메모리 하나만 이전 정보로 가져왔지만, LSTM에서 계산해서 전달하고자 하는 것은 c와 h 장기, 단기 2가지이고 input에 대한 계산에 대해서도 내부적으로 좀 더 복잡한 연결을 추가했다.
✅ 아키텍쳐
-
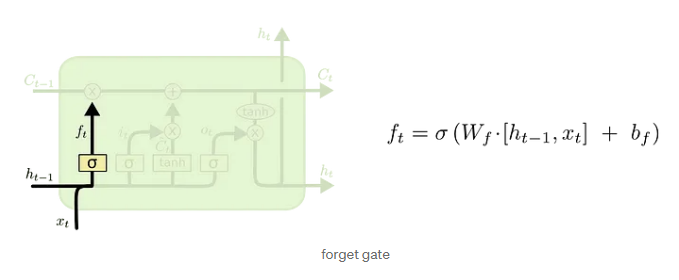
- forget gate
- forget gate
-
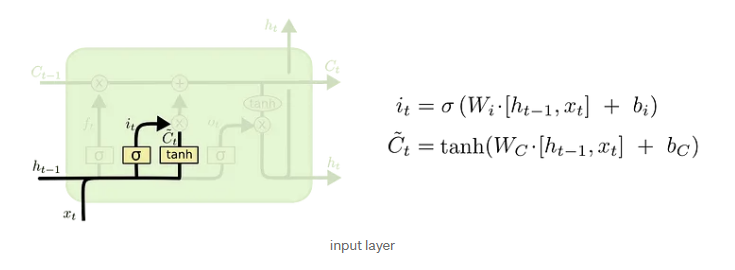
- Input gate
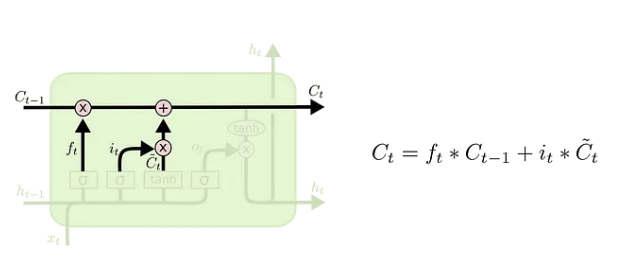
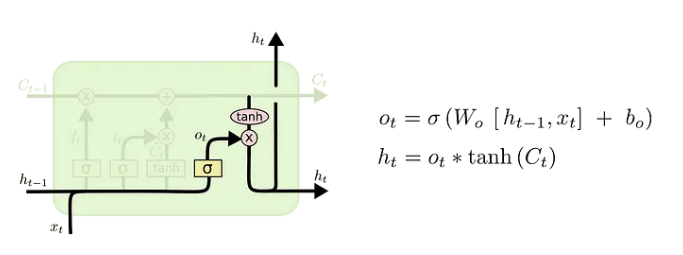
- Input gate
-
- Output gate
➡️ GRU (Gated Recurrent Unit)
게이트 순환 신경망이라 불리는 GRU는 LSTM보다 간단한 구조를 유지하면서, 새로운 게이트 컨트롤러가 별도로 존재하는 구조를 의미한다.
- forget gate, Input gate 를 하나로 합쳤다.
- gate controller 가 forget, Input gate 를 모두 제어한다.
GRU 개요
2. Language Model
단어의 시퀀스 확률, 즉 다음에 나올 단어를 예측할 때 사용되는 모델을 말한다.
✅ 단어들의 확률 분포
k번째 단어 Wk를 계산하고자 한다면, 다음과 같은 연쇄적인 계산이 필요하다.
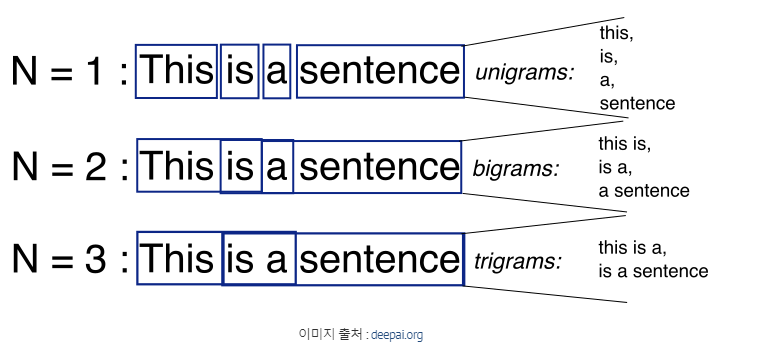
Probability of a sentence can be defined as the product of the probability of each symbol given the previous symbols
= 문장의 확률은 각 symbol 의 확률의 곱으로 계산되고, 각 symbol 의 확률이란 이전 단어가 주어졌을 때 그 단어가 등장할 확률이라 한다.
- Statistical LM
- N-gram based
- NN based LM
- fixed-window
- RNN based
- transformer based
-Statistical LM
N-gram 이란 단어의 확률을 계산하는데 있어서 현재 기준으로 이전 시점의 단어를 몇 개 볼 것인지 하는 것이다. Uni라면 1, Bi라면 2, Tri라면 3개의 단어를 본다.
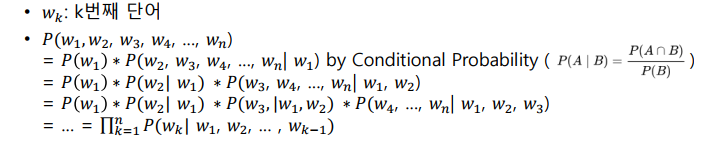
이렇게 확률을 구할 수 있는 것은 Markov assumption 덕분인데, 마르코프 가정이란 현재 시점에서의 확률은 최근 시점에서의 확률에서만 의존한다는 가정이다. 따라서 Markov assumption 으로 구할 단어의 확률을 이전 time-step 이 주어질 때 단어의 확률로 계산하고, 이를 Conditional probability 로 식을 변형시킨다. (n-gram 확률/ n-gram 범위확률; 현재 단어는 제외) 마지막으로 Statistical approximation 으로 이를 확률 기반이 아닌 count 로 접근하여 approximation 하게된다!
결국은 Statistical LM을 구성한다는 것은 전체 Corpus 에서 카운트 기반으로 단어에 대한 확률을 구해둔 후 이를 가져와서 계산하겠다는 것이다.
✅ N-gram 언어모델 한계
- Sparsity: n개의 단어가 항상, t순서대로 코퍼스에서 나타나지 않아서 발생하는 문제이다. 해결방법으로는 모든 카운트에 작은 숫자를 더해주는 Smoothing, lower-order n-gram을 사용해서 count 하는 Backoff 등이 있다.
-
Trade off 문제: n-gram에서 n을 너무 키우면 카운트할 수 있는 확률이 적어지거나 모델이 너무 커지고, n을 너무 작게하면 현실의 확률분포와 멀어진다.(의미를 잘 담아내지 못한다.)
-
정확도 문제: 어쨌든 n개 단어만 보기 때문에 낮은 정확도
-Neural LM
✅ Fixed-window Neural LM
window size 가 3이라고 할 때,단어를 3개씩 넣는 방법이다.
- 단어 3개를 표현, 입력(0-2)
- 윈도우를 한 칸 옮겨(1-3) 다음 단어 1개를 예측
- 반복
그럼 이전 단어를 보고 다음 단어를 예측한다는 측면에서 Statistical 접근과 무엇이 다르냐? 맞다. 전체적인 아이디어는 같으나 연산 방법이 다르다는 것이 중요하다. Neural Network에 입력한다는 것은 내부적인 숫자의 의미는 무시한다는 것이다. 예컨대 입력과 결과를 보고, 정답과 비교해서 가중치를 기계가 마음대로 수정하고 결과만 정답에 가까워지게 유도한다. 따라서 이전 통계적인 방법과는 달리 코퍼스에 없어도 예측이 가능하다. 그러나 Statistical은 숫자에 대한 의미도 있음과 동시에 코퍼스에 없으면 아예 예측이 불가능했다. 서로 장단점이 존재했다는 것.
- 장점: 희소성 문제가 사라졌고, 전체 n-gram 을 카운트할 필요 X
- 단점: 단어마다의 가중치를 저장해서 Window size를 키울 시 저장해야 할 가중치가 늘어남(모델이 커짐), No symmetry
따라서 고정 사이즈 윈도말고, 다양한 길이의 입력을 처리할 수 있는 네트워크가 필요했다 -> RNN!
-RNN LM

이전 time-step 의 output 이 현시점에서의 예측을 위해 input 으로 들어간다, 는 것이 핵심이다.
학습 단계에서는 초기에 빠른 수렴을 유도하도록 이전 time-step에서의 예측 자체가 아닌 Ground truth 단어를 입력으로 넣는 방식으로 학습시킨다. (정답에 가깝게 유도한다.) -> Tearcher forcing
- 장점: 다양한 길이의 입력도 처리 가능, 같은 weight 를 여러번 사용하므로 효율성 증가(RNN 특징)
- 단점: 반복 계산이 느림, 이전 정보에 대한 접근이 어려움
Language Model Metric
✅ Perplexity
- 언어모델이 헷갈리는 정도로써, 코퍼스의 등장 확률의 역으로 측정한다.
이전 단어가 나타났을 때 이전 단어가 나타날 확률에, 역수를 취한 것이다.
따라서 PPL이 높으면, 언어모델이 헷갈리고 있다, 를 뜻하고 PPL이 낮으면 헷갈리고 있지 않음을 뜻한다. 따라서 같은 코퍼스가 주어졌을 때 과거의 정보까지 연산을 잘 하는 모델이라면 대부분 PPL이 더 낮게 찍힌다.
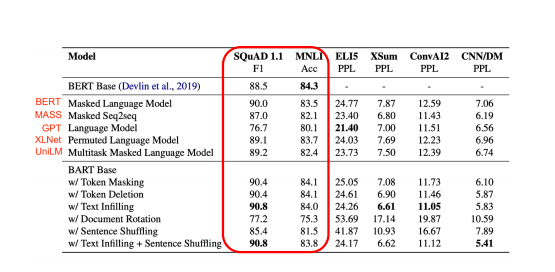
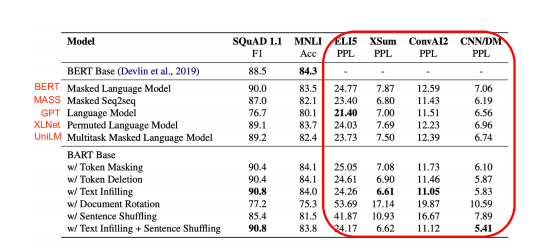
✅ Downstream Task Accuracy
References
- (towarddatasciences.com 의 자료 2개) https://towardsdatascience.com/recurrent-neural-networks-rnns-3f06d7653a85
- https://casa-de-feel.tistory.com/39
- (deepleraningbook) https://www.deeplearningbook.org/contents/rnn.html
- (thegradient.com) https://thegradient.pub/understanding-evaluation-metrics-for-language-models/
- (n-gram 정리 블로그) https://yngie-c.github.io/nlp/2020/05/22/nlp_ngram/
- (ppl 정리 블로그) https://heiwais25.github.io/nlp/2019/10/13/Language-model-3/
