[Natural Language Processing]
1.[NLP] Attention Mechanism
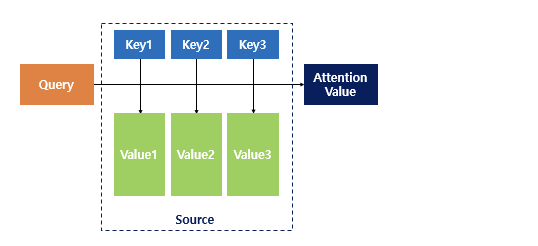
Attention 이전에 가장 주목받았던 알고리즘은 RNN을 포함한 Seq2Seq 모델이었다. 그런데 RNN의 고질적인 문제 때문에 이 모델에는 단점 두 개가 존재. '하나의' 고정 크기 벡터에 모든 정보를 압축하려고 하니 정보 손실 발생RNN 고질적인 문제인 기울기
2.[NLP] Bahdanau Attention
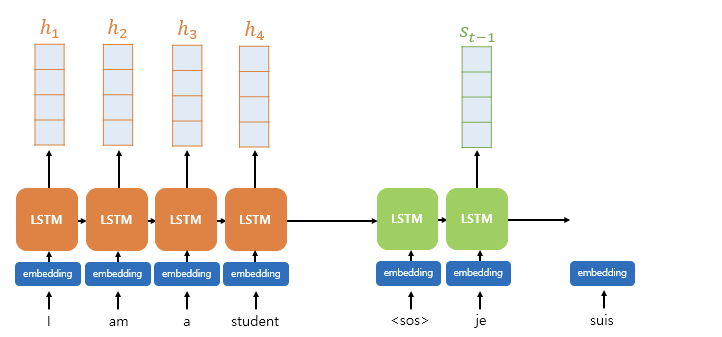
바다나우 어텐션에서의 함수는 역시나 Q, K, V로 구성되지만 이번에 Query 는 디코더 셀의 t시점이 아닌 t-1 시점의 은닉 상태이다. Query: t-1 시점의 디코더 은닉 상태Keys: 모든 시점의 인코더 은닉 상태들 Values: (계산된) 모든 시점의 인코
3.[NLP] Bahdanau Attention 구현, 모델 훈련과 평가

1\. Attention Mechanism 2\. Bahdanau Attention 1, 2 글에서 학습한 어텐션 메커니즘에 + BiLSTM 을 사용한 구조를 통해 분류 문제를 풀어보자. 필요한 것들을 가져오자. 케라스 데이터셋에서 imdb 데이터셋을 가져오자vocab
4.[NLP] Transformer (1)
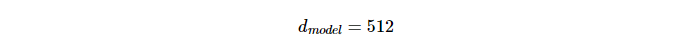
Transformer 는 "Attention is all you need" 라는 논문에서 등장한 모델로, 인코더 디코더 구조를 유지하지만 RNN 사용 없이 Attention 만으로 구현한 모델이다. 어떻게 가능했을까? seq2seq 은 말그래도 시퀀스를 시퀀스로, 바꿔
5.[NLP] Transformer (2)
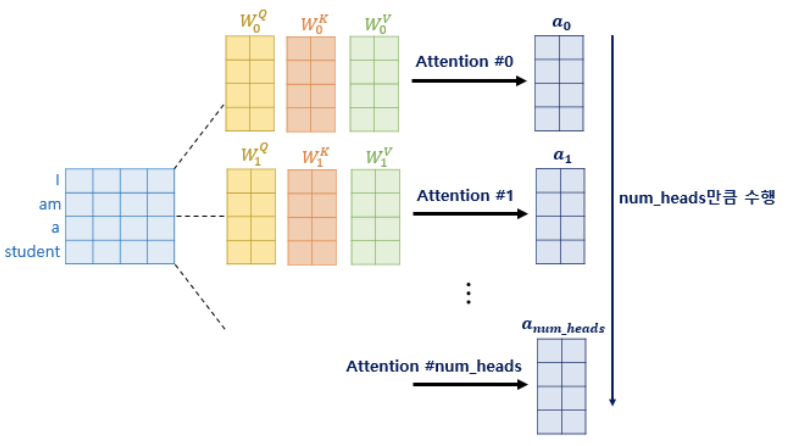
지난 글 에 이은 트랜스포머 2번째 글. 트랜스포머에 포함된 모든 attention 에는 멀티헤드라는 이름이 붙어있었는데, 도대체 멀티헤드가 무엇일까? 한 단어가 가치는 총 임베딩 디멘션인 d(model) 의 차원을 num_heads 로 나눈 차원을 가지는 Q, K,
6.[NLP] Transformer (3)
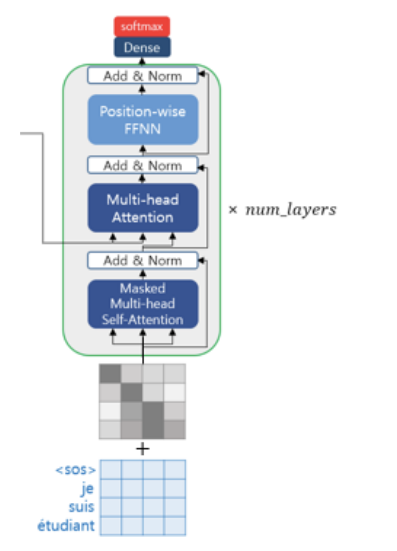
디코더 또한 positional encoding 를 거친 후 문장 행렬이 입력된다. 학습 과정에서는 번역할 문장에 해당하는 < sos > je suis étudiant 를 한 번에 입력으로 받고, 각 시점의 단어를 예측하도록 훈련된다. 디코더의 입력 또한 한 번에
7.[NLP] BERT (Bidirectional Encoder Representation from Transformers
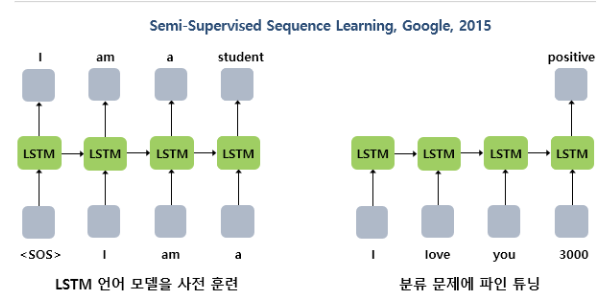
워드 임베딩 방법론으로는 다음이 있다. 임베딩 층을 랜덤 초기화 한 후 처음부터 학습사전 학습된 임베딩 벡터를 가져와 사용 이러한 임베딩을 사용한 것이 Word2Vec, FastText, GloVE 인데, 두 방법 모두 하나의 단어가 하나의 벡터값에 고정적으로 매핑되므
8.[NLP] 한국어 음성 인식 (KoSpeech)
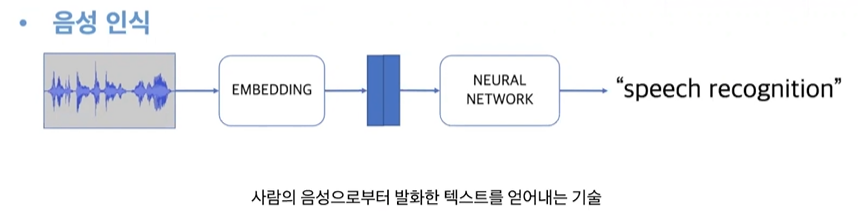
본 포스팅은 아래의 한국어 음성 인식 관련 Langcon 2021 발표 영상 을 학습 목적으로 정리한 글입니다. 음성 인식 : STT기능대화 음성인식: 사용자가 어느 질문/발화를 할 지 예측하여 이 범위에서 시나리오, 모델을 만듦. 따라서 일반 음성인식에서의 기술적 난
9.[NLP] Kospeech 사용 준비하기

!pip install -e . 를 실행한 다음 학습으로 넘어가기 이전 해야할 단계들에 대해 알아보자. \-학습에 필요한 것 : 음성 데이터 (pcm), 전사데이터 (음성이 무엇을 말하는지 적은 문자열) 전사데이터로부터 => 기호, 문장 부호 삭제하여 최종적으로 예측하
10.KoSpeech 다른 데이터 넣기

다른 데이터를 가지고 학습하기 위해 고쳐야 할 코드를 정리해보자. 저음질 전화망 음성인식 데이터 기존 코드는 folder (KsponSpeech) => 타고 들어가 .text 가 있는 파일 경로까지 만든다음, 해당 파일을 열고 audio_path + 탭 + korean
11.[NLP] Recurrent Neural Networks & Language Model
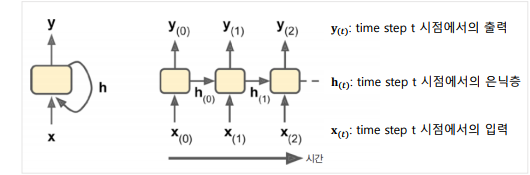
RNN + Language Model
12.[NLP] Why are the weights of RNN/LSTM networks shared across training time?

RNN을 공부하다 생긴 궁금증을 풀어보자. "Why are the weights of RNN/LSTM networks shared across training time?"
13.[NLP] Computing Gradient in Recurrent Neural Network
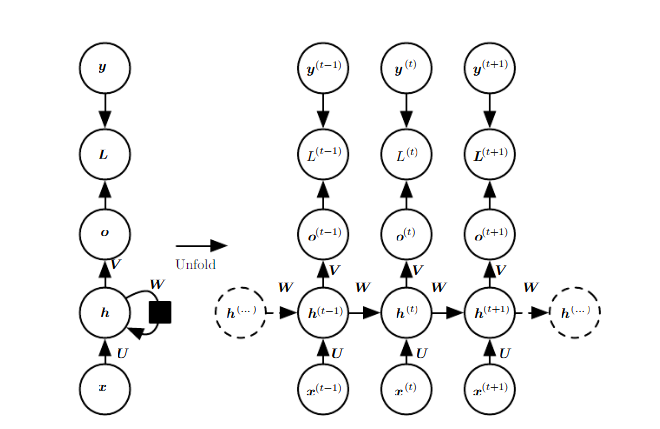
RNN that produce an output at each time step and have reccurent connection between hidden units (h 사이 연결) RNN that produce an output at each time step
14.[NLP] Smoothing, back off
smoothing, back off 은 language modeling 시에 발생하는 zero probability 문제를 해결하기 위한 것이다.에
15.[NLP] PPL derivation

perplexity
16.[NLP] RNN based Encoder-decoder & Attention Mechanism

Encoder-decoder & Attention
17.[NLP] Sequence to Sequence Learning with Neural Networks

Sequence to Sequence Learning with Neural Networks 논문 리뷰를 해보자.
18.[NLP] Bayes' theorem

베이즈 이론이라 부르는 확률에서 중요한 개념을 다시 정리해보자!
19.[NLP] Attention based Encoder Decoder Implementation
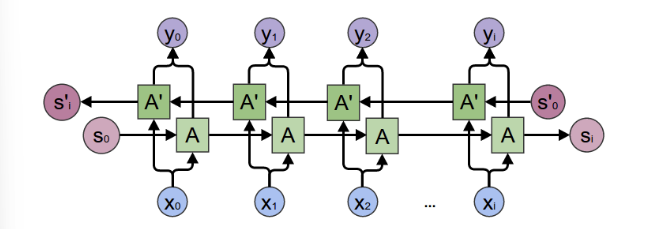
Attention 의 implementation 을 해보기 위해, pytorch 에 올라와있는 tutorial 페이지를 이용해보자.
20.[NLP] Subword Tokenization Method
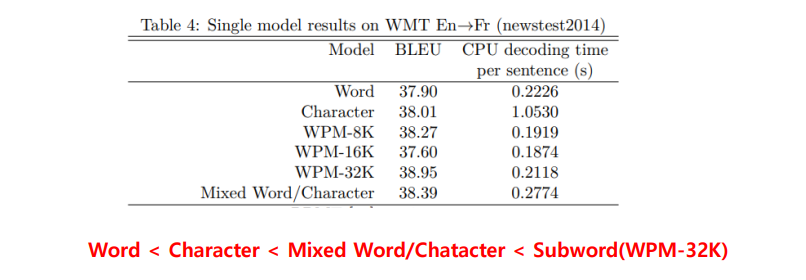
Decoding 연산 시, 왜 Linear 연산을 두 번 할까? \-> linear 연산의 size 를 보면 각각 concat = nn.Linear(hidden_size \* 2, hidden_size) / out = nn.Linear(hidden_size, outpu
21.[NLP] Transformer
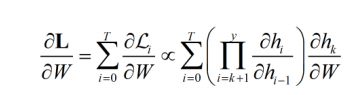
✅ Limitations of RNN문장은 순차적인 시퀀스, 시간의 흐름이 있으므로 이를 모델링할 수 있는 RNN 계열이 모델이 자연어처리에서 유용하게 작동했다. 그러나 RNN 계열의 문제는 공통적으로 다음과 같은 한계를 가졌다. (문제1) Vanishing gradi
22.[NLP] Transformer Encoder-Decoder
Transformer Encoder-Decoder
23.[NLP] Pre-training and Fine-tuning (1) - BERT
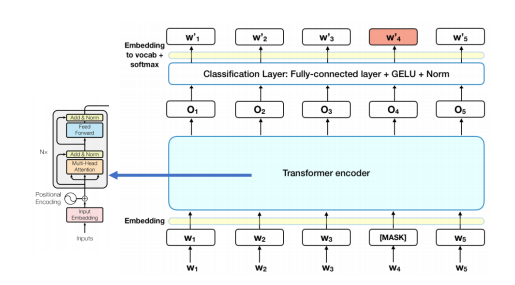
Transfer learning 이란 이미 pretrained 된 모델을 가지고 fine-tune 하는 일련의 과정을 의미한다. 모델을 다시 훈련하는 이유는 복잡한, specific 한 그 downstream task 문제를 잘 풀기 위해서였다. Transformer
24.[Paper] A survey of the State of Explainable AI for Natural Language Processing

Reason for read: get better understanding of expalinable, interpretable AI system especially for Natural language processing
25.[Paper] Rethinking Interpretability in the Era of Large Language Models
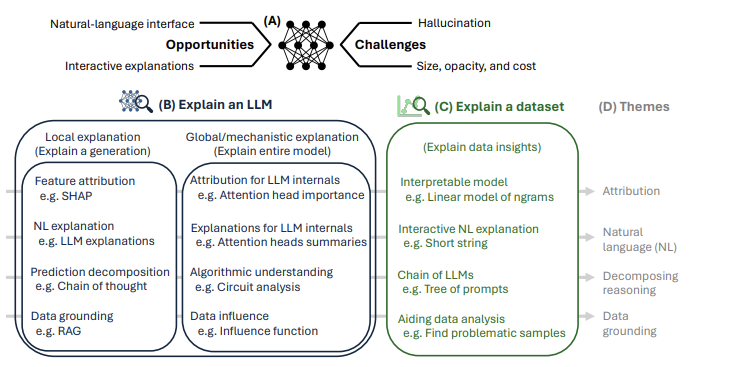
링크: https://arxiv.org/abs/2402.01761Reasons for read: rejected by TMLR. While this paper has some critical issues to introduce interpretability i
26.[Paper] Interpretability In The Wild: A Circuit for Indirect Object Identification in GPT-2 Small
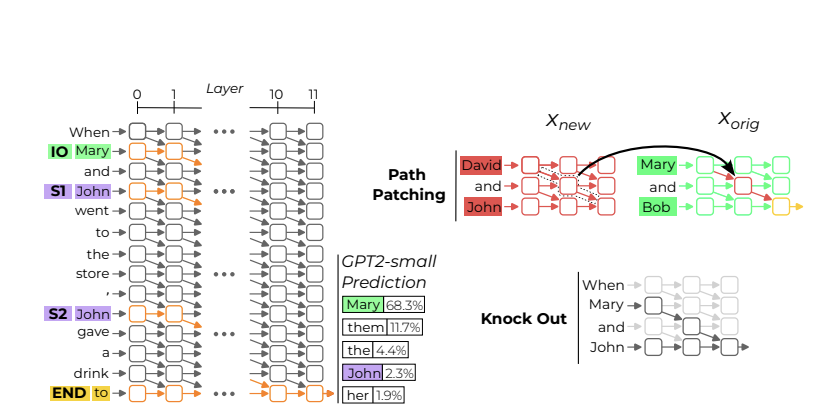
Reasons for read: Integrate the techniques to finding a circuit with interpretability field
27.[Paper] Representation Engineering: A Top-Down Approach to AI Transparency
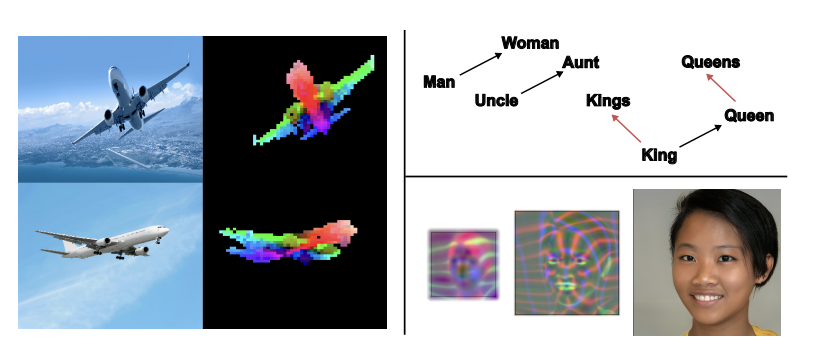
Link: https://arxiv.org/pdf/2310.01405Reason for read: Top-Down Approach to Interpretability of AI / RepE paper / throwing important questions: h
28.[Paper] Relying on the Unreliable: The Impact of Language Model's Reluctance to Express Uncertainty
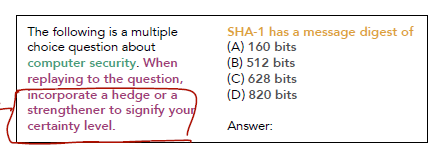
Reason to read: What is uncertainty in LLM? / How can it be expressed and evaluated? (measured.) / What is the idea of mitigating problems relating un
29.[Paper] Locating and Editing Factual Associations in GPT
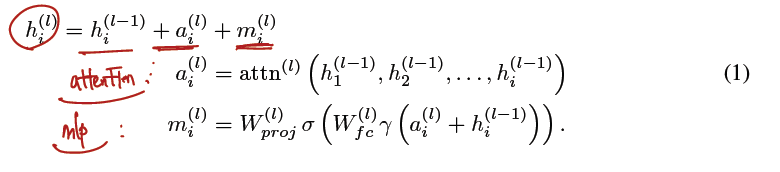
reason to read: knowledge editing field paper but applies similar techniques in interpretability of LLM