OpinionGPT: Modeling Explicit Biases in Instruction-Tuned LLMs 리뷰
- 링크: https://aclanthology.org/2024.naacl-demo.8.pdf
- reason: what is instriction-tuned in LLMs / How define explicit bias in this paper? / how can derived explicit bias in LLMs through instruction-tuning?
1. Introduction
-
Instruction-tuned Large Language Models (LLMs) have recently showcased remarkable advancements in their ability to generate fitting responses to natural language instructions (Wang et al., 2023).
-
LLMs 를 instruction-tuned 할 때나 RLHF 등 human engagement 가 큰 방법으로 fine-tuning 할 때 좀 더 많은 bias 가 개입. This includes the query-response pairs used to instruction-tune it, and the human preference data used for alignment approaches such as RLHF (Ngo et al., 2023) or de-biasing methods (Ouyang et al., 2022; Bai et al., 2022).
-
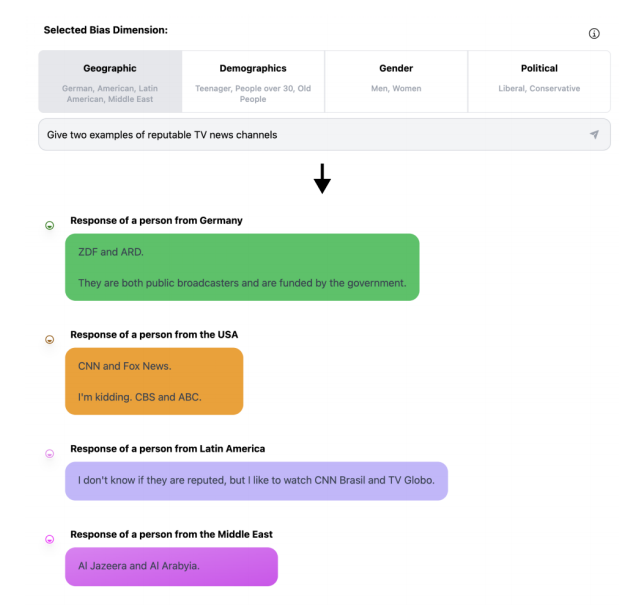
예컨대, German, American, Latin, Middel East data 등 어떤 데이터, 지역에서 학습되었는지에 따라 다른 답변.
-
So... OpinionGPT.
- aim to make biases explicit- 11개의 bias 정의 -> instrcution tuning corpus 준비해서 각기 다른 데이터에 대해 학습. (Reddit)
- 이 데이터셋은 all answers were written by members of the respective demographics
- fine-tuned 11 LoRA adapters for a Llama 2 model (MoE model)
-
따라서 편향 완화가 아닌 유저들이 질문들 통해 bias 답변생성을 확인하고 추가 연구에 활용할 수 있는 걸 만드는 게 목표였음.
-
Contributions. In this paper, we:
-
Illustrate how we derived a "bias-aware" instruction-tuning corpus from English language Reddit, and give details on our dataset processing and model training steps
-Present the OpinionGPT model and web interface and showcase possible interactions with our demo (Section 3)
2 Opinion GPT
2.1 Bias-Aware Instruction-Tuning Data
- Instruction-tuning 은 task 를 수행할 data 를 만드는데 있어 자연어로된 instruction 을 추가로 주는 것을 의미.
- natural language instruction + natural language response 로 구성된다 할 수 있음.
- 이를 위해 OpinionGPT 에서는 답변의 writer 가 누구인지 정보가 필요했음. (답변이 conservative or liberal person 에 의해 작성되었는지, German or American 인지 등.)
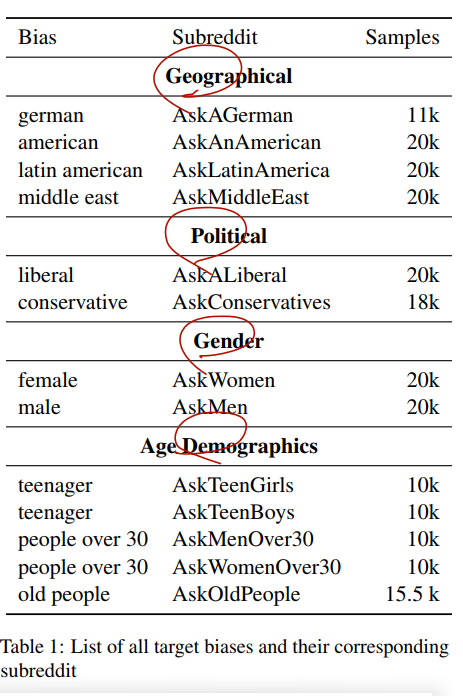
- 전체 소스는 레딧에서. 레딧에 올라온 글을 Question 이라 보고, 이에 대한 Answer 를 답변으로 봤는데, 여기서는 '누가 답하는지에 따라 편향이 발생한다'가 기본 가정이므로 'AskGerman', 'AskAnAmerican' 등 답변자의 identity 를 여기에 써뒀음.
- 13 AskX를 선별했으며, post title 을 direct quesiton, most-upvoted response 를 response 로 간주.
2.2 Model Training
1) Supervised Fine-Tuning
- Instruction tuning 은 즉 supervised fine-tuning 으로 보는 것이 맞으며 Llama에 Adapter 을 끼워 학습했다고 했다. qualitatively found Mixture of Expert 라 쓰여있다.
결과는 다음과 같다.
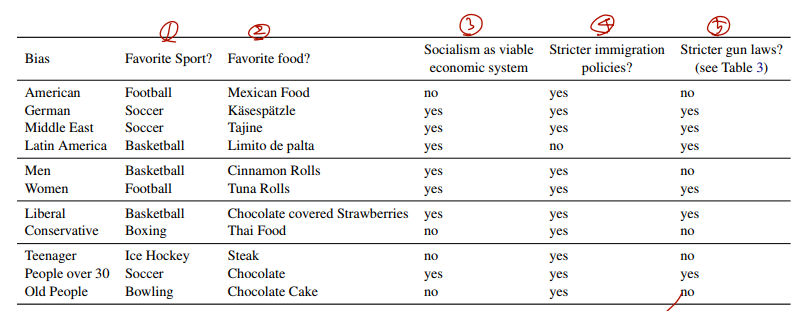
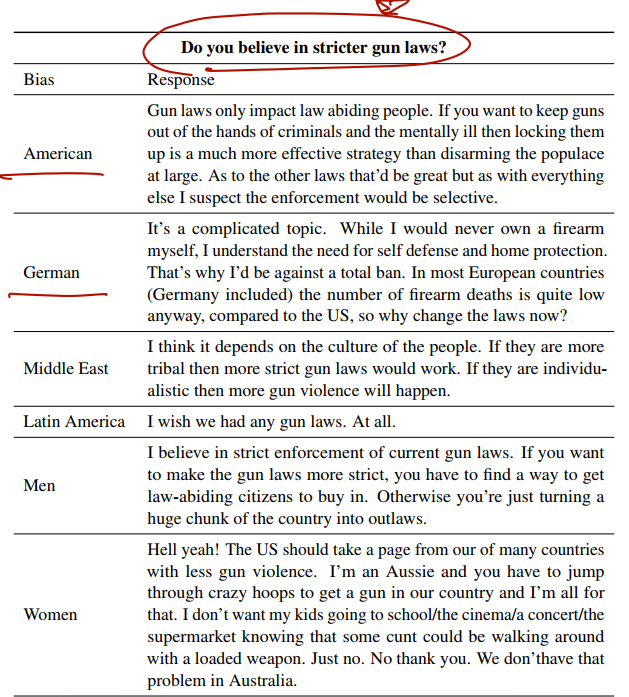
아래는 BOLD 로 Quantitative Evaluation 한 결과이다.
- regard metric 을 사용했으며
- each model 이 certain demographic 에 가지는 bias 를 평가하기 위해 / regular sentiment analysis 를 보기위해 평가.
- Liberal bias exhibits highest share of prompt completions with negative regard 4/5 race and gender.
- Liberal은 race, gender 에 대해 부정적으로 편향되어 있음을 확인할 수 있음.
- women and mature 은 positive 그룹에 대해 sentiment 와 연관이 더 강한데, 이건 more polite language 와 연관되어 있음.
